-
大模型之Prompt研究和技巧
大模型之Prompt编写
简介
Prompt是是给 AI **模型的指令,**一个简短的文本输入,用于引导AI模型生成特定的回答或执行特定任务。
Prompt是你与语言模型沟通的方式。一个好的Prompt可以让AI更准确地理解你的需求,从而给出更有用的回答。
组成
Prompt的组成拆解主要包括以下六个要素:
- 任务(Task): 任务是Prompt的核心,通常以动词开始,明确表达你希望ChatGPT完成的任务或目标。这可以包括生成文本、给予建议、写作内容等。可以有多个任务,以清晰地定义你的需求。
- 上下文(Context): 上下文提供了与任务相关的背景信息,以确保ChatGPT理解问题的背景和约束条件。这包括用户的背景信息、成功标准、所处环境等。上下文对于任务的明确性和有效性至关重要。
- 示例(Exemplars): 示例是提供具体例子或框架的部分,用来引导ChatGPT生成更准确的输出。提供示例可以明确示范所需的内容和格式,从而提高输出质量。但并不是每次都需要提供示例,有时候也可以让ChatGPT自行生成。
- 角色(Persona): 角色明确指定ChatGPT和Bard(如果涉及到虚构的角色)所扮演的角色或身份。这可以是具体的人,也可以是虚构的角色,有助于调整语气和内容以适应特定角色的需求。
- 格式(Format): 格式部分可视化了你期望输出的外观和结构,如表格、列表、段落等。明确指定输出的格式可以确保ChatGPT生成的内容符合你的预期。
- 语气(Tone): 语气定义了输出文本的语气或风格,如正式、非正式、幽默等。指定语气有助于确保ChatGPT的回应符合所需的情感和风格要求。
通过合理组织这六个要素,你可以创建一个清晰明了的Prompt,有效引导ChatGPT生成符合期望的文本输出。
当创建一个Prompt时,下面是一些具体的例子,展示如何使用上述六个要素:
1. 任务(Task):
- 生成一篇有关太阳能发电的文章。
- 给予我一些建议,以降低生活中的碳足迹。
- 写一封感谢信,以表达对客户的感激之情。
2. 上下文(Context):
- 作为一个学生,你要写一篇有关气候变化的研究报告,希望获得深入了解可再生能源的信息。
- 你是一位环保活动家,需要有关减少塑料污染的可行性计划。
- 你正在回顾一次商务合作,需要一封感谢信来强调合作的重要性。
3. 示例(Exemplars):
- 作为示例,可以提供一些有关太阳能的统计数据,或者一个类似的文章的开头段落。
- 作为示例,列出一些环保措施,如减少用塑料制品、使用可再生能源等。
- 提供一些已经写好的感谢信段落,以供参考。
4. 角色(Persona):
- 请以一位环保组织的志愿者的身份来回答。
- 请以一位科学家的身份来回答。
- 请以一位公司首席执行官的身份来回答。
5. 格式(Format):
- 请以段落的形式写一篇文章,包括标题、引言、正文和结论。
- 请以列表形式列出减少碳足迹的建议。
- 请以正式书信的格式写一封感谢信,包括日期、地址、称呼等。
6. 语气(Tone):
- 请使用正式的语气,避免使用俚语或口语。
- 请使用轻松的语气,可以适当加入幽默元素。
- 请使用感激之情的语气,表达真诚的感谢。
这些示例突出了如何根据具体的需求来组成Prompt,以确保ChatGPT能够理解任务、上下文、示例、角色、格式和语气,并生成相应的内容。通过合理搭配这些要素,可以引导ChatGPT产生符合要求的文本回应。
技术
Zero-Shot
Zero-Shot Prompting 指的是在大型语言模型(LLM)中,不需要额外微调或训练,直接通过文本提示就可以完成指定的下游任务。
主要思想是:
- 先训练一个通用的大型语言模型,学习语言的基本规则,掌握丰富的常识和知识。
- 然后在不改变模型参数的情况下,只通过软性提示指导模型完成特定任务。
- 模型根据提示和已掌握的知识,生成对应任务的输出。
举个例子,我们可以给 ChatGPT 一个简短的 prompt,比如
描述某部电影的故事情节,它就可以生成一个关于该情节的摘要,而不需要进行电影相关的专门训练。Zero-Shot Prompting 技术依赖于预训练的语言模型,这些模型可能会受到训练数据集的限制和偏见。它的输出有时可能不够准确,或不符合
预期。这可能需要对模型进⾏进⼀步的微调或添加更多的提示⽂本来纠正。
Few-shot
Few-shot Prompting 是 Zero-shot Prompting的扩展,指使用很少量的任务相关示例来辅助提示,使模型更快适应新任务。
其关键思想是:
- 仍然基于预训练好的通用语言模型
- 使用软提示指导模型完成新任务
- 额外提供1-2个相关示例作为提示补充
例如:
任务: 生成一篇关于太阳能的文章。
示例:
- 示例1:太阳能是一种清洁能源,通过太阳能电池板将太阳能转化为电力。
- 示例2:太阳能电池板通常安装在屋顶上,可以为家庭提供可再生能源。
- 示例3:太阳能是减少温室气体排放的重要途径。
任务描述: 请以这些示例为基础,撰写一篇关于太阳能的文章,重点介绍太阳能的工作原理、应用领域以及对环境的影响。
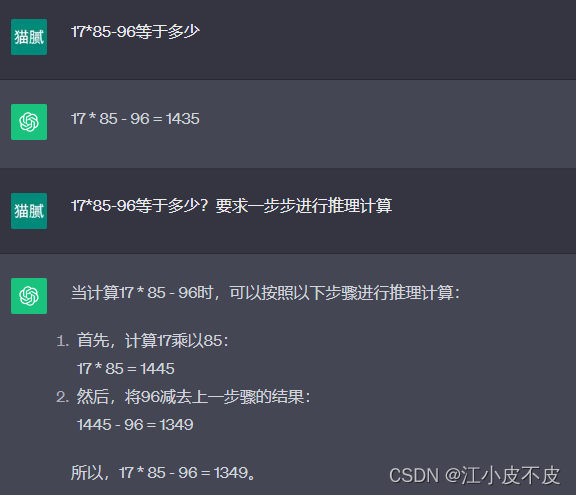
COT
论⽂表明,它仅在⼤于等于 100B 参数的模型中使⽤才会有效。如果是⼩样本模型,这个⽅法不会⽣效。
思维链提示,就是把一个多步骤推理问题,分解成很多个中间步骤,分配给更多的计算量,生成更多的 token,再把这些答案拼接在一起进行求解。

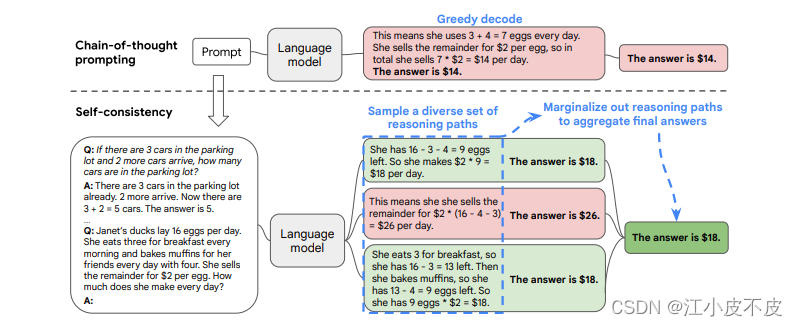
COT-SC
让模型⽣成多个思维链,然后取最多数答案的作为最终结果。
其实重复运算多次,取概率最⾼的那⼀个,需要借助脚本辅助完成这个功能。
Self-consistency是对CoT方法的改进,相比于CoT只进行一次采样回答,SC采用了多次采样的思想,最终选择consistent的回答作为最终答案。SC的成立的基础是文章认为,一个复杂的推理问题可以采用多种不同的方式进行解决,最终都可以得到正确答案。人类思考同一个问题可能会有不同的思路,但是最后可能得到相同的结论。可以理解为“一题多解”“条条大路通罗马”。SC相比于CoT性能进一步得到了更大的提升。
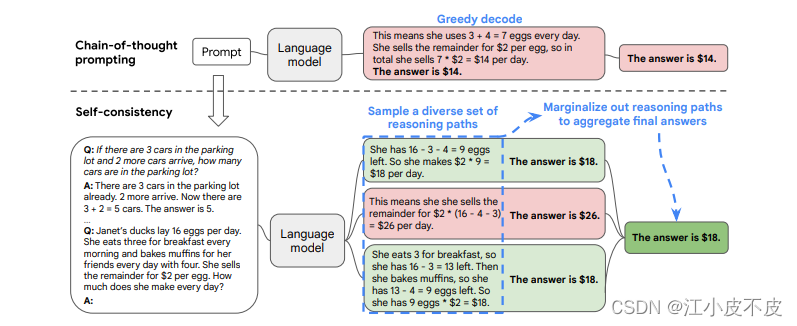
通过多次采样回答,最终选择一致性最高的结果作为最终结果,这在很大程度上可以避免LLM随机性带来的错误问题。
TOT
Tree of Thoughts(ToT)框架,⽤于改进语⾔模型(LMs)的推理能⼒。该框架是对流⾏的“Chain of Thought”⽅法的⼀种
泛化,允许模型在解决问题的过程中进⾏更多的探索和策略性前瞻。
ToT允许模型⾃我评估不同的选择,以决定下⼀步的⾏动,并在必要时进⾏前瞻或回溯,以做出全局性的选择。
在24点游戏中,使⽤链式思考提示的GPT-4仅解决了4%的任务,⽽使⽤ToT⽅法的成功率达到了74%
在其他场景中的应用型不是很大。
GoT
GoT有三种操作:
-
Aggregation
-
Refining
-
Generation
Aggregation指的是几个想法的整合,变成了一个更好的想法,图上表现为多个节点指向同一个节点;
Refining指节点自身进行反思,不断改善自己本身的内容,图上表现为一个节点重新指向自己;
Generation指通过一个节点,产生了后续1个或者更多新的想法,图上表现为一个节点指向一个或多个节点。
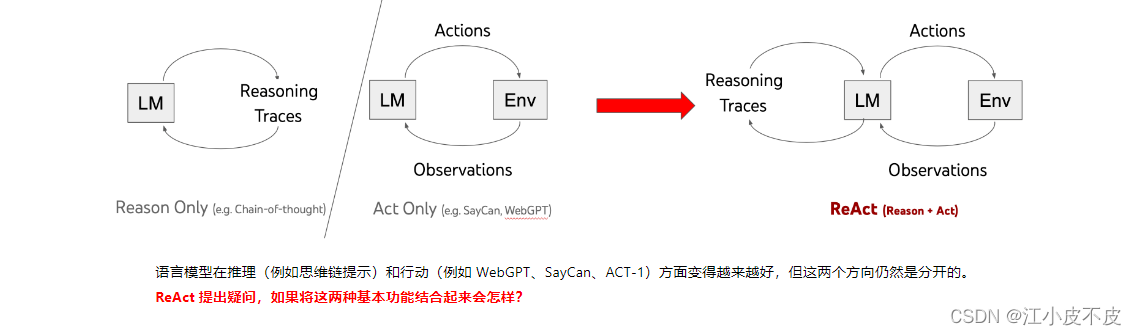
ReAct
和langchain 中的Agent是一个道理
使用 LLM 以交错的方式生成推理轨迹和特定于任务的动作,从而实现两者之间更大的协同作用。
推理轨迹帮助模型归纳、跟踪和更新行动计划以及处理异常,而操作允许它与外部源(例如知识库或环境)交互,以收集附加信息。我们应用我们的方法,名为 ReAct,适应各种语言和决策任务,并证明其在最先进的基线上的有效性,以及比没有推理或行动组件的方法提高的人类可解释性和可信度。
具体来说,在问答(HotpotQA)和事实验证(Fever)方面,ReAct 通过与简单的维基百科 API 交互,克服了思维链推理中普遍存在的幻觉和错误传播问题,并生成类似人类的任务解决轨迹,比没有推理痕迹的基线更容易解释。
-
相关阅读:
Spring 从入门到精通 (十四) 切入点详解
如何通过DBeaver 连接 TDengine?
第六十三章 IIS 7 或更高版本的替代选项 (Windows) - 替代选项 4:将 CGI 模块与 NSD 结合使用 - 映射 IRIS 文件扩展名
Vue收集表单数据
js第七章
2000至2022年中国月度植被覆盖度产品
卷积神经网络的结构组成与解释(详细介绍)
安装K8s基础环境软件(二)
tflite 学习——生成.tflite 模型与验证
Linux系统编程系列之线程池
- 原文地址:https://blog.csdn.net/qq128252/article/details/133775725