-
3D 生成重建006-3DFuse 形状引导一致性的文生3d的方法
3D生成重建006-3DFuse 形状引导一致性的文生3d的方法
0 论文介绍
在004-DreamFusion and SJC 中dreamfusion提到将2D观测结果“提升”到3D世界的任务本质上是模糊的,并可能受益于更健壮的3D先验。这篇论文就是基于这个点出发,对文生3d进行拓展。这篇论文基于dreamfusion的思路,引入PointE的图生3d模型,生成一个初步的粗糙的点云,然后将稀疏的深度引导加入到扩散模型中,因为加入了更多的约束条件,所以进一步控制nerf往一个固定的方向去优化,这一定程度上能帮助缓解CFG过大问题,让模型可能不需要那么大的CFG系数。这个点是论文的核心点。另外设计的两个点一个就是类似gan inversion的思路,通过文本生成图像之后,去反优化text表示 e ∗ e^* e∗,这种做法有利于减少文本的歧义性。第三个点就是为了在风格上保持一致,论文在中间微调了一个lora层,在进行深度扩散的时候可以让生成的结果在风格上保持一致,这和第一点有点类似的效果,应该一定程度能让CFG系数不那么大,从而减轻过饱和过度光滑问题。值得一提的是,虽然引入了形状先验,但是他使用的稀疏的深度信息,但是依然不能存在Janus problem(多面体问题)。在使用形状引导这点他和同期的latent nerf是很接近的,换一种角度理解这跟通过文本给mesh着色也是很接近,只不过3dfuse的形状更加粗糙。
参考
论文资料链接3dfuse1 论文方法
下面这个图是论文的整体结果图。整体上也是围绕前面的三点进行,只不过与介绍顺序不同。这张图最左边的部分,生成semantic code这部分约等于inversion操作。右上角绿色的部分包含一个形状先验,是通过PointE实现的。其中橙色方框中的LoRA layers是要根据左边生成的几张视图进行训练的,训练好之后,才会和深度信息一起跟扩散模型的Unet结果结合。右下角部分就是一个nerf场。
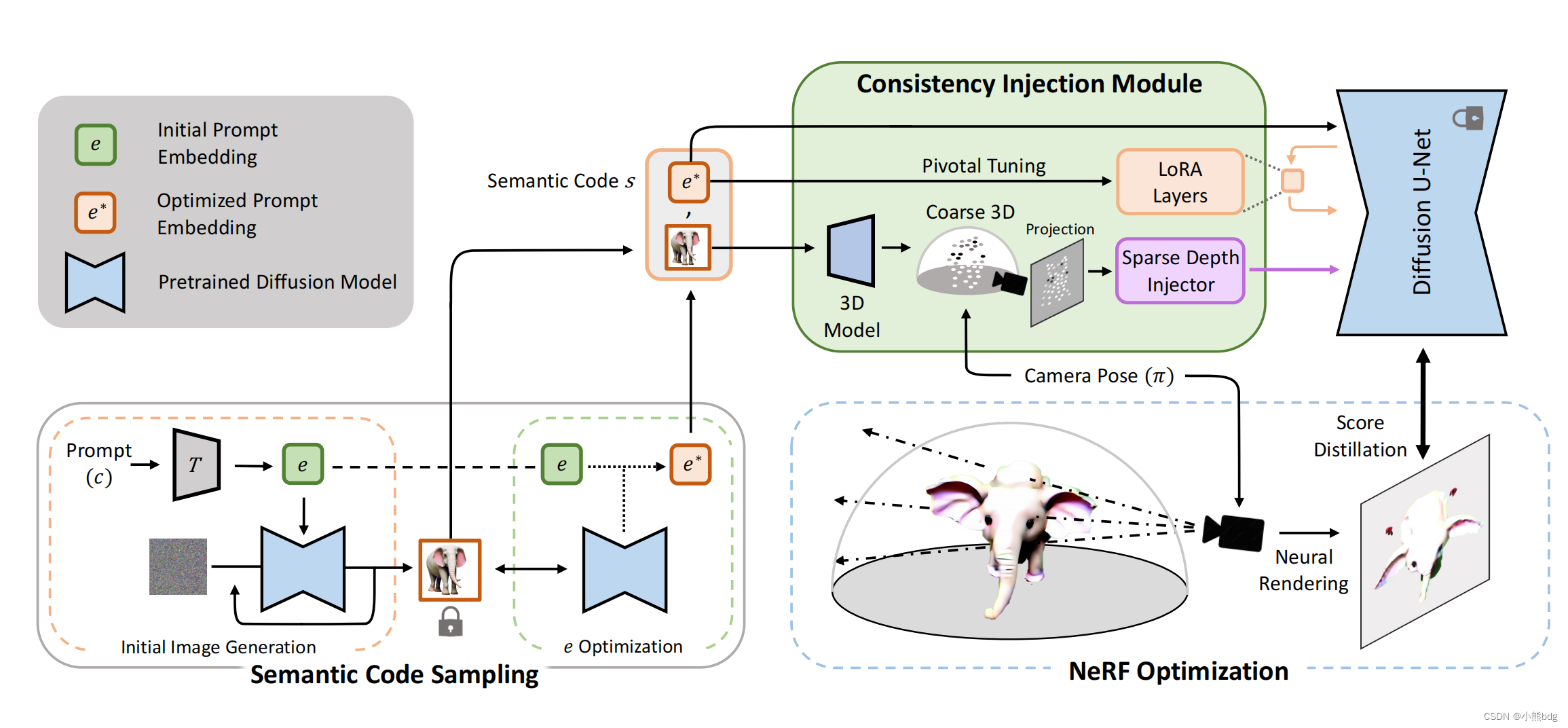
1.1 semantic code
这个部分基本上就是扩散模型中textual inversion论文来实现的。输入一个promt,扩散模型生成一张图像,然后基于生成的图像和输入的prompt进行反向优化得到更新的 e ∗ e^* e∗,公式原理如下 e ∗ = arg min e ∣ ∣ ϵ θ ( x t ^ , e ) − ϵ ∣ ∣ 2 2 e^*=\mathop{\arg\min}\limits_{e}||\epsilon_{\theta}(\hat{x_t},e)-\epsilon||_2^2 e∗=eargmin∣∣ϵθ(xt^,e)−ϵ∣∣22
其中 x t ^ \hat{x_t} xt^表示对生成的图像添加噪声。
这个操作在其他3d生成算法中也有出现,比如realFusion和Chasing Consistency等,下面两个图中有体现。
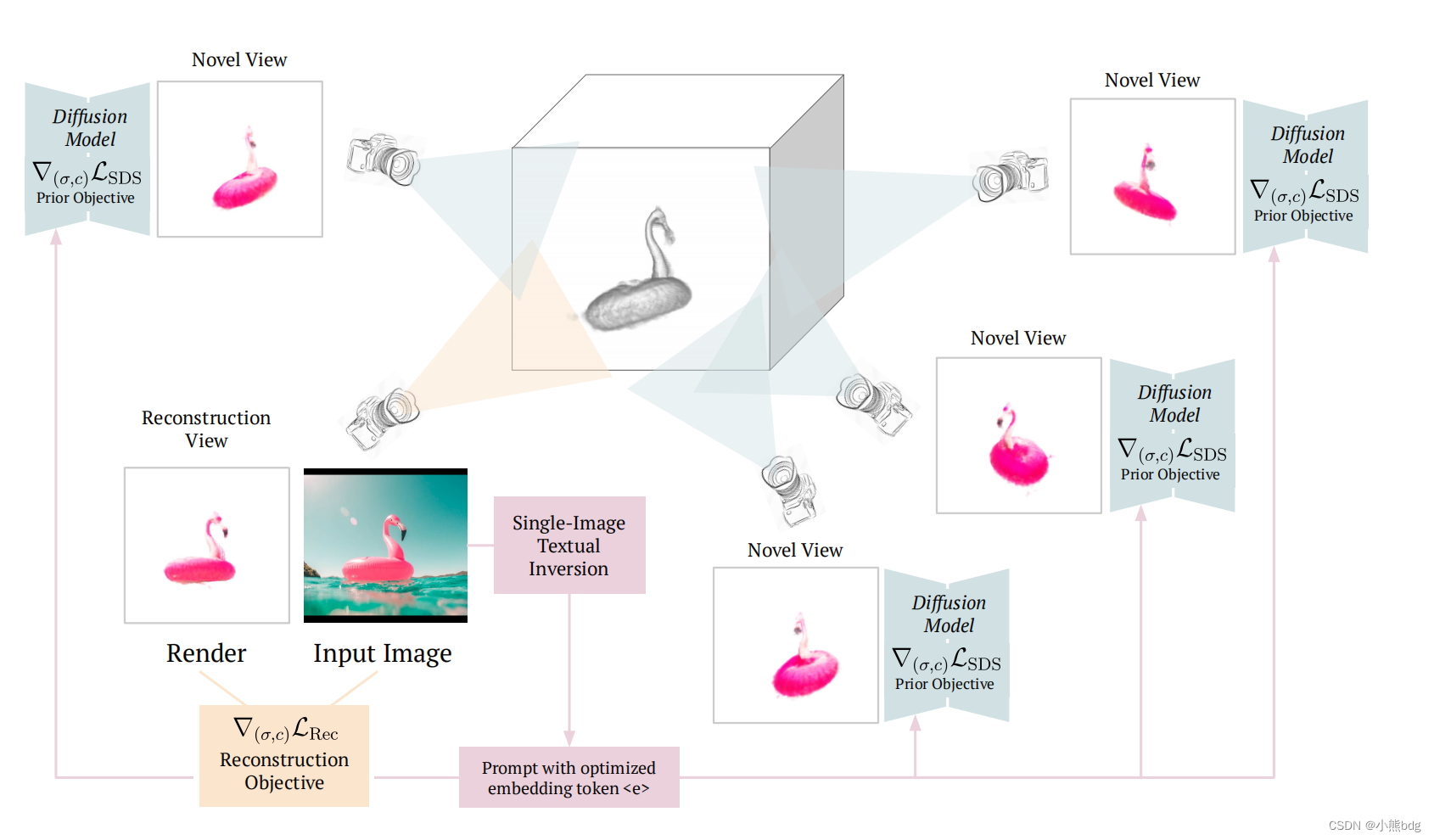
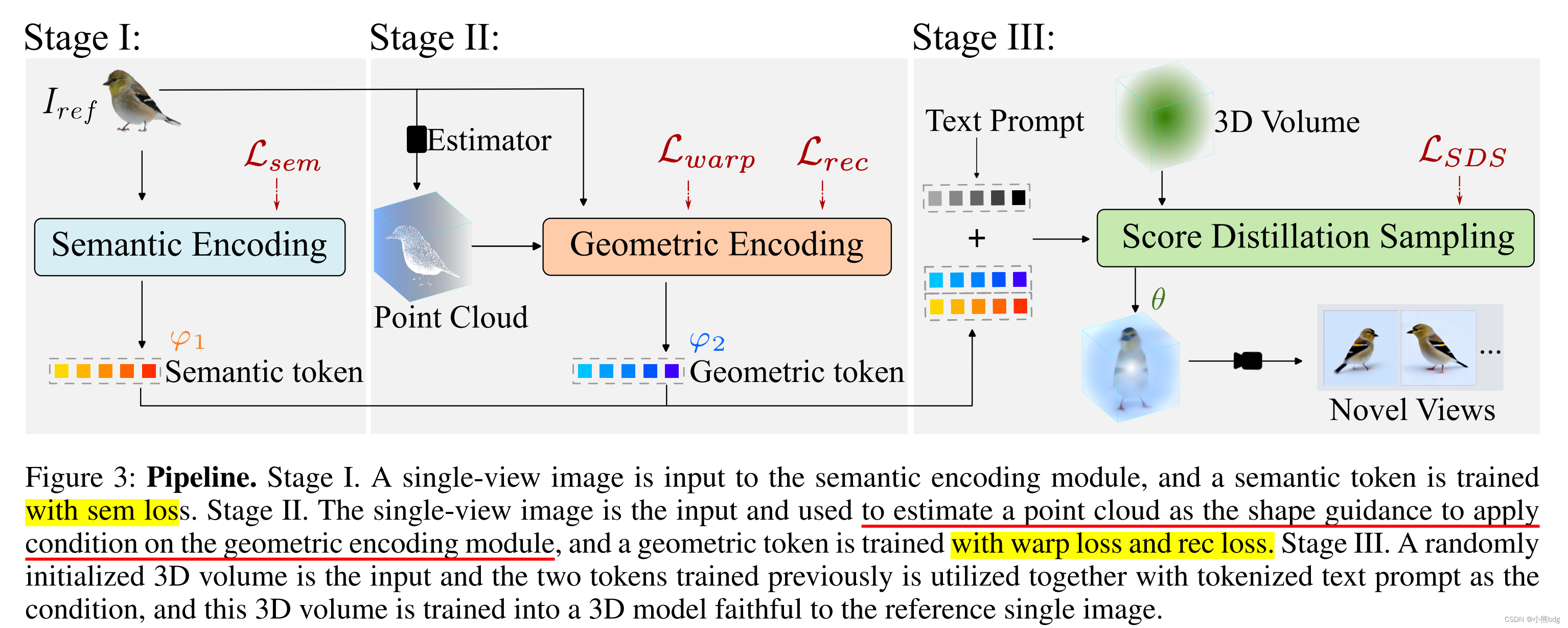
1.2 稀疏深度信息PointE
pointE是openAi在大型的3d数据集上训练的一个点云扩散模型。效果虽然比较粗糙,但是能够提供一定的先验信息,他的升级版本是shapE,d都是很贵的模型。

1.3 lora部分
LoRA在大模型很火热的今天,属于很重要的工具,因为动不动就去调整几百几千亿参数的大模型是很吃力的,LoRA就是一个很优秀的微调算法。参考链接lora
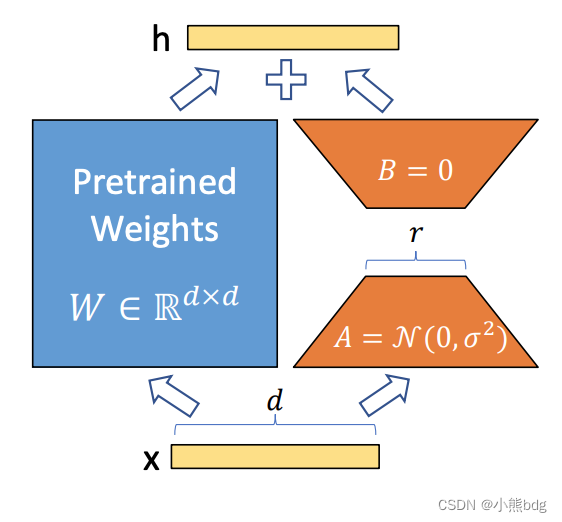
如上图,在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。训练的时候固定 PLM 的参数,只训练降维矩阵 与升维矩阵 ,而模型的输入输出维度不变,输出时将 与 PLM 的参数叠加。用随机高斯分布初始化 ,用 0 矩阵初始化 ,保证训练的开始此旁路矩阵依然是 0 矩阵。参考知乎
2 效果
可以看出来,还是存在确实细节和多面体问题,但是过饱和得到一定缓解。
3dfuse
-
相关阅读:
CSRF的其他防范措施?
虚拟摄像头之八: 从 Camera api2 角度看摄像头框架
关联路网拓扑特性的车辆出行行为画像分析
uniapp打包微信小程序。报错:https://api.weixin.qq.com 不在以下 request 合法域名列表
[JS] canvas 详解
怎么开发自己的NFT平台
网络技术一:计算机网络概述
vite+react 使用 react-activation 实现缓存页面
nvidia系统开机自启
FL Studio 21.2.3.4004 完整破解版 [Mac + Win] 下载 2024最新免费Crack 下载
- 原文地址:https://blog.csdn.net/weixin_41871126/article/details/133763518