-
【ElasticSearch】使用 Java 客户端 RestClient 实现对文档的查询操作,以及对搜索结果的排序、分页、高亮处理
前言:RestClient 查询文档的 RestAPI
在 Elasticsearch 中,通过 RestAPI 进行 DSL 查询语句的构建通常是通过
HighLevelRestClient中的resource()方法来实现的。该方法包含了查询、排序、分页、高亮等所有功能,为构建复杂的查询提供了便捷的接口。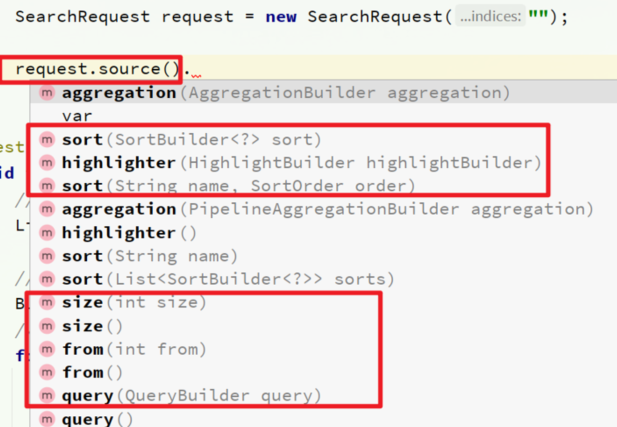
RestAPI 中构建查询条件的核心部分是由一个名为
QueryBuilders的工具类提供的。该工具类包含了各种查询方法,如下图所示: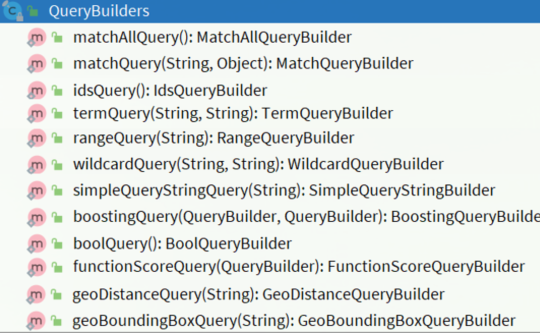
查询的基本步骤如下:
- 创建
SearchRequest对象。 - 准备
Request.source(),也就是 DSL。 - 使用
QueryBuilders构建查询条件。 - 将查询条件传入
Request.source().query()方法。 - 发送请求,得到结果。
- 解析结果,可以参考 JSON 结果,从外到内逐层解析。
这种方式使得构建复杂的查询变得简单而灵活。在接下来的实例中,我们将深入学习如何使用
HighLevelRestClient中的resource()方法构建各种查询,并充分利用QueryBuilders工具类来满足不同的搜索需求。一、全文检索查询
1.1 match_all 查询
match_all查询的单元测试代码:@Test void testMatchAll() throws IOException { // 1. 准备Request SearchRequest request = new SearchRequest("hotel"); // 2. 组织 DSL 请求 request.source().query(QueryBuilders.matchAllQuery()); // 3. 发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4. 解析结果 List<HotelDoc> hotelDocs = handleResponse(response); System.out.println(hotelDocs); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个测试代码演示了如何使用
match_all查询来获取指定索引(这里是 “hotel”)下的所有文档。具体步骤如下:- 创建
SearchRequest对象,指定索引为 “hotel”。 - 使用
QueryBuilders.matchAllQuery()构建查询条件。 - 将查询条件添加到请求的 DSL 中。
- 发送请求,得到查询结果。
- 解析查询结果,将文档转换为
HotelDoc对象。
1.2 match 查询
@Test void testMatch() throws IOException { // 1. 准备Request SearchRequest request = new SearchRequest("hotel"); // 2. 组织 DSL 请求 request.source().query(QueryBuilders.matchQuery("all", "如家")); // 3. 发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4. 解析结果 List<HotelDoc> hotelDocs = handleResponse(response); System.out.println(hotelDocs); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个测试代码演示了如何使用
match查询来搜索包含特定关键词(这里是 “如家”)的文档。具体步骤如下:- 创建
SearchRequest对象,指定索引为 “hotel”。 - 使用
QueryBuilders.matchQuery("all", "如家")构建查询条件,表示在 “all” 字段中搜索包含 “如家” 的文档。 - 将查询条件添加到请求的 DSL 中。
- 发送请求,得到查询结果。
- 解析查询结果,将文档转换为
HotelDoc对象。
1.3 multi_match 查询
@Test void testMultiMatch() throws IOException { // 1. 准备Request SearchRequest request = new SearchRequest("hotel"); // 2. 组织 DSL 请求 request.source().query(QueryBuilders.multiMatchQuery("如家", "name", "business")); // 3. 发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4. 解析结果 List<HotelDoc> hotelDocs = handleResponse(response); System.out.println(hotelDocs); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个测试代码演示了如何使用
multi_match查询来在多个字段(这里是 “name” 和 “business”)中搜索包含特定关键词(这里是 “如家”)的文档。具体步骤如下:- 创建
SearchRequest对象,指定索引为 “hotel”。 - 使用
QueryBuilders.multiMatchQuery("如家", "name", "business")构建查询条件,表示在 “name” 和 “business” 字段中搜索包含 “如家” 的文档。 - 将查询条件添加到请求的 DSL 中。
- 发送请求,得到查询结果。
- 解析查询结果,将文档转换为
HotelDoc对象。
可以看到,这些测试代码的结构类似,只是在构建查询条件时使用了不同的
QueryBuilders方法,用于满足不同的查询需求。二、精确查询
精确查询常见的有
term查询和range查询,同样使用QueryBuilders指定具体的查询方式。2.1 term 查询
@Test void testTerm() throws IOException { // 1. 准备Request SearchRequest request = new SearchRequest("hotel"); // 2. 组织 DSL 请求 request.source().query(QueryBuilders.termQuery("city", "上海")); // 3. 发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4. 解析结果 List<HotelDoc> hotelDocs = handleResponse(response); System.out.println(hotelDocs); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个测试代码演示了如何使用
term查询来搜索指定字段(这里是 “city”)中包含特定关键词(这里是 “上海”)的文档。具体步骤如下:- 创建
SearchRequest对象,指定索引为 “hotel”。 - 使用
QueryBuilders.termQuery("city", "上海")构建查询条件,表示在 “city” 字段中搜索包含 “上海” 的文档。 - 将查询条件添加到请求的 DSL 中。
- 发送请求,得到查询结果。
- 解析查询结果,将文档转换为
HotelDoc对象。
2.2 range 查询
@Test void testRange() throws IOException { // 1. 准备Request SearchRequest request = new SearchRequest("hotel"); // 2. 组织 DSL 请求 request.source().query(QueryBuilders.rangeQuery("price").gte(150).lte(200)); // 3. 发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4. 解析结果 List<HotelDoc> hotelDocs = handleResponse(response); System.out.println(hotelDocs); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个测试代码演示了如何使用
range查询来搜索指定字段(这里是 “price”)中在给定范围内的文档。具体步骤如下:- 创建
SearchRequest对象,指定索引为 “hotel”。 - 使用
QueryBuilders.rangeQuery("price").gte(150).lte(200)构建查询条件,表示在 “price” 字段中搜索价格在 150 到 200 之间的文档。 - 将查询条件添加到请求的 DSL 中。
- 发送请求,得到查询结果。
- 解析查询结果,将文档转换为
HotelDoc对象。
这些测试代码演示了如何使用精确查询来满足特定的搜索需求。在实际应用中,可以根据具体的业务场景和数据结构选择不同的查询方式。
三、复合查询:Boolean 查询与 function score 查询的综合案例
例如,现在通过一个酒店预订网址的查询功能不但可以在搜索框输入关键字进行查询,还可以勾选指定的筛选条件,比如城市、星级、品牌和价格范围:

另外,再所有的酒店数据中还存在一部分属于广告(ES 文档中新增一个布尔类型的isAD字段表示),要求查询结果中的广告需要顶置显示,因此整个查询分为两部分:即boolean查询和function score查询。boolean查询:实现对搜索关键字的查询,以及过滤:城市、星级、品牌和价格等条件;function score查询:实现对广告文档的相关性增加操作。
具体的查询代码如下:
private static void buildBasicQuery(RequestParams params, SearchRequest request) { // 1. 原始查询 Query BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); // 关键字搜索 must String key = params.getKey(); if (key == null || key.isEmpty()) { boolQuery.must(QueryBuilders.matchAllQuery()); } else { boolQuery.must(QueryBuilders.matchQuery("all", key)); } // 城市条件 if (params.getCity() != null && !params.getCity().isEmpty()) { boolQuery.filter(QueryBuilders.termQuery("city", params.getCity())); } // 品牌条件 if (params.getBrand() != null && !params.getBrand().isEmpty()) { boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand())); } // 星级条件 if (params.getStarName() != null && !params.getStarName().isEmpty()) { boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName())); } // 价格范围 if (params.getMaxPrice() != null && params.getMinPrice() != null) { boolQuery.filter(QueryBuilders .rangeQuery("price").lte(params.getMaxPrice()).gte(params.getMinPrice())); } // 2. 算分查询 FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery( // 原始查询,相关信算法的查询 boolQuery, // function score 数组 new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{ // 其中一个具体的 function score new FunctionScoreQueryBuilder.FilterFunctionBuilder( // 过滤条件 QueryBuilders.termQuery("isAD", true), // 算分函数 ScoreFunctionBuilders.weightFactorFunction(10) ) }); request.source().query(functionScoreQuery); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
对上述代码的详细说明:
RequestParams是一个封装了前端请求参数的对象,里面包含了 ES 文档中的各个字段;- 在这个方法中,首先构建了一个
boolQuery作为原始查询条件,包含了关键字搜索、城市、品牌、星级和价格范围等多个条件; - 接着,构建了一个
functionScoreQuery,将原始查询作为参数传入,同时定义了一个FilterFunctionBuilder,用于处理广告部分的查询,对广告文档的分数进行加权,使其在查询结果中更靠前显示; - 最后,将 functionScoreQuery 设置为请求的查询条件。
这个综合的查询案例涵盖了多个条件的组合查询以及对特定文档的加权分数处理。在实际应用中,可以根据业务需求扩展和修改这个查询方法。
四、对查询结果的处理
4.1 将查询结果按照自己的距离远近排序
在前端查询酒店数据的时候,一般都会定位获取到自己当前的位置,然后传递给后端。
RequestParams作为前端参数的封装对象,包含了这个位置信息,可通过get方法进行获取;- 然后可以通过
SortBuilders中的geoDistanceSort方法计算距离并进行排序操作,即可获取酒店与自己的实际距离。
String location = params.getLocation(); if (location != null && !location.isEmpty()) { request.source().sort(SortBuilders .geoDistanceSort("location", new GeoPoint(location)) .order(SortOrder.ASC) .unit(DistanceUnit.KILOMETERS) ); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.2 根据前端请求参数进行分页操作
分页需要的页码以及页面大小一般都由前端传递参数给后端,然后后端获取这两个参数进行分页操作。
RequestParams作为前端参数的封装对象,包含了这两个参数,可通过get方法进行获取;- 然后再根据分页偏移量的计算公式
offset = (page - 1) * size即可获取偏移量,然后通过source的from和size方法,即可实现分页查询。
例如:
int page = params.getPage(); int size = params.getSize(); request.source().from((page - 1) * size).size(size);- 1
- 2
- 3
4.3 对搜索关键字进行高亮处理
要对搜索关键字进行高亮处理同样非常简单,只需要使用
resouce中的highlighter方法指定要进行高亮的字段即可。实现的示例代码如下:
@Test void testHighlight() throws IOException { // 1. 准备Request SearchRequest request = new SearchRequest("hotel"); // 2. 组织 DSL 请求 // 2.1 query request.source().query(QueryBuilders.matchQuery("all", "如家")); // 2.2 设置高亮 request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false)); // 3. 发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4. 解析结果 List<HotelDoc> hotelDocs = handleResponse(response); System.out.println(hotelDocs); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
说明:
注意
requireFieldMatch方法的作用是高亮的字段是否需要和搜索的字段匹配。例如:使用字段all查询匹配brand字段,此时brand字段使用了copy_to到all字段,因此要高亮的字段并不匹配,如果不设置requireFieldMatch为false则会高亮失败。对结果的解析:
实现高亮的原理是对搜索关键字加上了
其实高亮的处理并没有作用到查询出的原始文档中,而是在每个hits里面新增了一个highlight字段,里面包含了高亮的关键字,因此还需要对handleResponse函数进行改造,使得能够处理高亮的查询结果:例如,在
handleResponse函数的result.add(hotelDoc)这句代码之前,新增了以下代码用于处理高亮的情况,即使用高亮处理了的关键字替换查询结果中对应的关键字:// 获取高亮结果 Map<String, HighlightField> highlightFields = hit.getHighlightFields(); if(highlightFields != null && !highlightFields.isEmpty()) { // 获取高亮名称 HighlightField highlightField = highlightFields.get("name"); // 获取高亮的值 String name = highlightField.getFragments()[0].toString(); hotelDoc.setName(name); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
当运行这段测试代码,即可发现成功对
name字段的 “如家” 添加了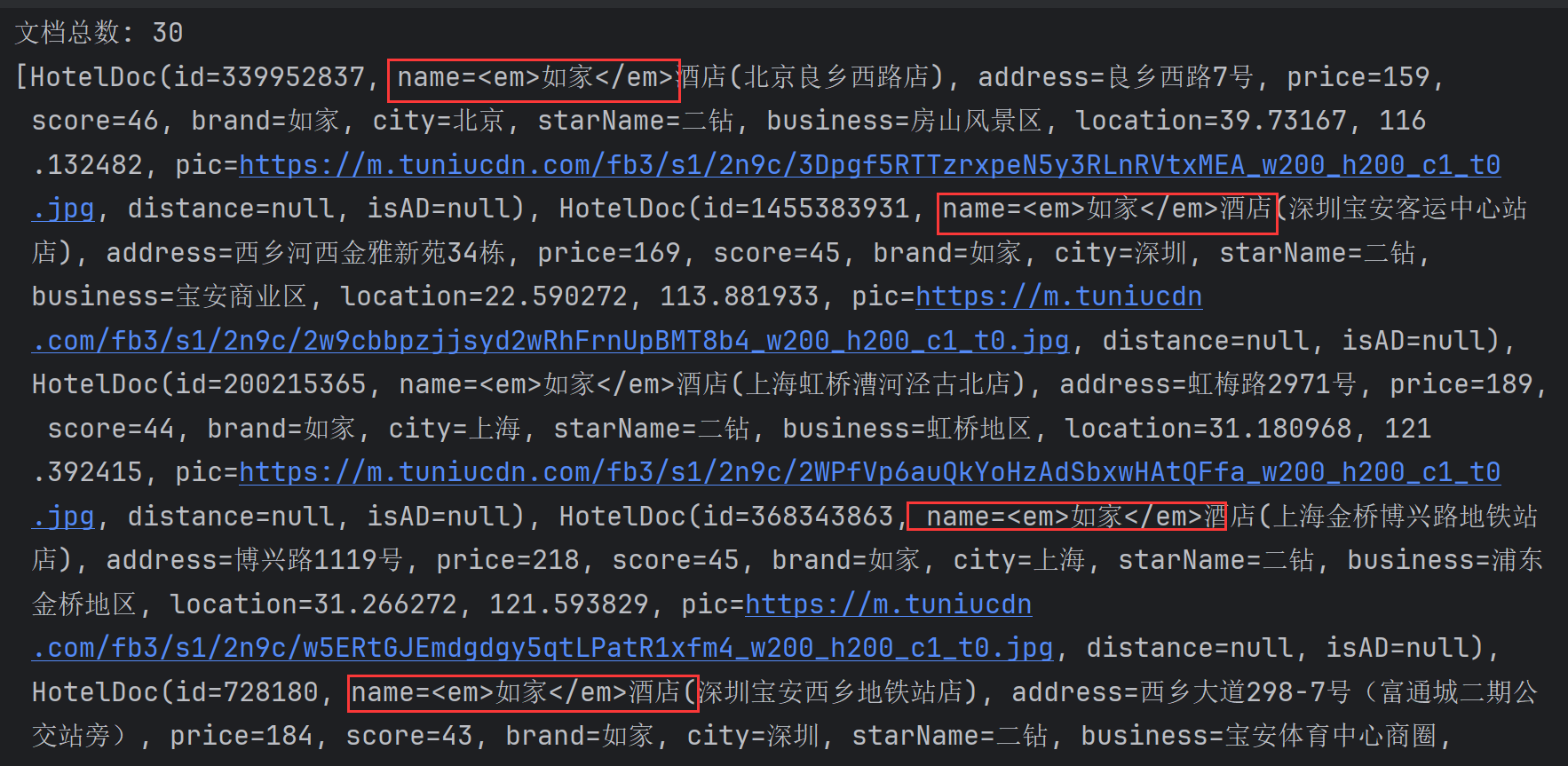
- 创建
-
相关阅读:
用ChatGPT编写一个词卡显示网页
多线程基础部分Part2
Vue---v-for渲染和样式绑定
灯具rohs检测认证多少钱,ROHS认证价格
筹备三年,自动驾驶L3标准将至,智驾产业链的关键一跃
mysql在update,非主键索引更新引起死锁
CompletableFuture之批量上传
leetcode 215.数组中第k大的元素
一段时间后,stop-dfs.sh关不掉Hadoop3.1.3集群,stop-hbase.sh关不掉HBase集群
LLM实战(一)| 使用LLM抽取关键词
- 原文地址:https://blog.csdn.net/qq_61635026/article/details/133688996
