-
【ElasticSearch】深入探索 DSL 查询语法,实现对文档不同程度的检索,以及对搜索结果的排序、分页和高亮操作
前言
Elasticsearch(简称ES)是一个强大的开源搜索和分析引擎,广泛应用于各种应用程序中,从企业级搜索引擎到日志和指标分析。其强大之处在于其灵活的数据模型和丰富的查询语言,使得用户能够轻松地进行全文检索、精确查询、地理坐标查询等操作。
本文将深入探讨Elasticsearch的DSL(Domain Specific Language)查询,分为多个部分进行介绍。首先,我们会了解Elasticsearch DSL Query的分类,然后深入研究全文检索查询、精确查询、地理坐标查询以及复合查询等不同类型的查询。
每一节都会提供详细的语法和实际示例,以便读者能够更好地理解和运用Elasticsearch中强大的查询功能。最后,我们将介绍对搜索结果进行排序、分页以及搜索关键字高亮处理等实用的处理技巧,以完善搜索体验。
让我们开始深入探讨Elasticsearch DSL Query,发现如何利用其强大的功能来提升搜索和分析的效果。
一、Elasticsearch DSL Query 的分类
Elasticsearch 提供了强大而灵活的DSL(领域特定语言)查询,用于定义对索引库中文档的不同类型查询。下面将详细介绍一些常见的 DSL查询类型:
1. 查询所有 -
match_all查询所有文档,通常用于测试或获取整个索引的文档。
{ "query": { "match_all": {} } }- 1
- 2
- 3
- 4
- 5
2. 全文检索查询
match查询
利用分词器对用户输入的内容进行分词,然后在索引中匹配分词后的词语。
{ "query": { "match": { "field_name": "search_text" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
multi_match查询
在多个字段上执行全文检索查询。
{ "query": { "multi_match": { "query": "search_text", "fields": ["field1", "field2"] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3. 精确查询
ids查询
根据文档ID查询文档。
{ "query": { "ids": { "values": ["doc_id1", "doc_id2"] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
term查询
根据精确词条值查找数据,适用于 keyword、数值、日期、boolean等类型字段。
{ "query": { "term": { "field_name": "exact_value" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
range查询
根据范围查询,适用于数值、日期等类型的范围查询。
{ "query": { "range": { "field_name": { "gte": "start_value", "lte": "end_value" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. 地理查询
geo_distance查询
根据经纬度查询指定距离范围内的文档。
{ "query": { "geo_distance": { "distance": "10km", "location": { "lat": 40.73, "lon": -73.98 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
geo_bounding_box查询
根据指定的矩形框查询文档。
{ "query": { "geo_bounding_box": { "location": { "top_left": { "lat": 40.73, "lon": -74.1 }, "bottom_right": { "lat": 40.01, "lon": -71.12 } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5. 复合查询
bool查询
通过组合多个查询条件,支持must、must_not、should等逻辑。
{ "query": { "bool": { "must": [ { "match": { "field1": "value1" } }, { "range": { "field2": { "gte": 10, "lte": 20 } } } ], "must_not": [ { "term": { "field3": "value2" } } ], "should": [ { "match": { "field4": "value3" } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
function_score查询
根据某个函数计算的分数对查询结果进行打分,用于加权不同的查询条件。
{ "query": { "function_score": { "query": { "match": { "field": "search_text" } }, "functions": [ { "filter": { "range": { "field2": { "gte": 10, "lte": 20 } } }, "weight": 2 } ], "score_mode": "multiply" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
以上是一些常见的 Elasticsearch DSL查询类型,在使用的时候可以根据具体需求灵活组合这些查询条件来实现复杂的搜索和过滤功能。下面是针对于这些不同查询的详细说明以及查询演示。
二、全文检索查询
全文检索查询是通过对用户输入的内容进行分词,然后在索引中匹配分词后的词语,实现更灵活的文本搜索。在Elasticsearch中,常用的关键词是
match和multi_match。2.1
match查询match查询会根据一个字段进行查询,适用于单一字段的全文检索。在实际应用中,可以使用copy_to将多个字段的值合并到一个字段,从而实现类似multi_match的查询效果。例如,针对
hotel索引库的全文检索查询:GET /hotel/_search { "query": { "match": { "all": "如家" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里假设
all字段是通过copy_to包含了多个字段的内容,如:“brand”、“business”、“name”。查询结果如下: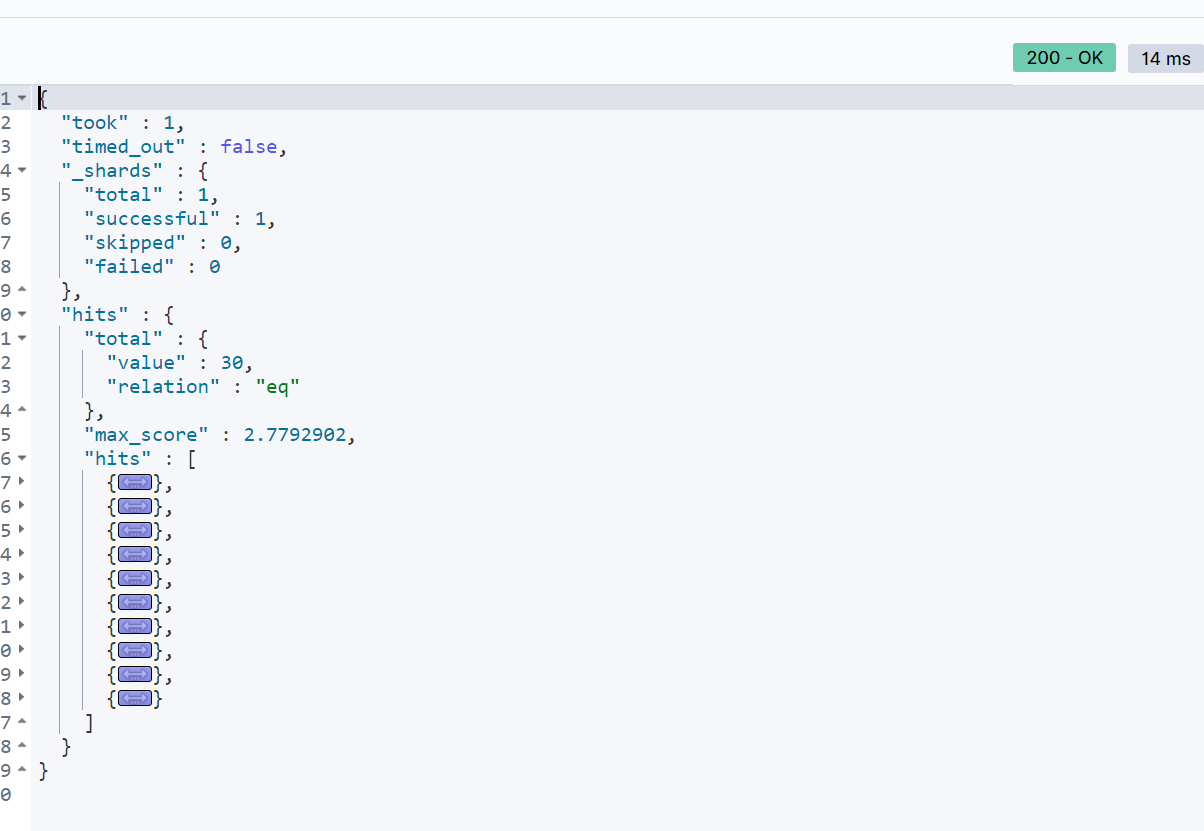
2.2
multi_match查询multi_match查询允许根据多个字段进行全文检索查询,但需要注意,参与查询的字段越多,查询效率可能越低。例如,使用
multi_match查询:GET /hotel/_search { "query": { "multi_match": { "query": "如家", "fields": ["brand", "business", "name"] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个例子中,参与查询的字段同样是:“brand”、“business”、 “name”。查询结果如下:

可以观察到,
match和multi_match的查询结果是相同的。在实际应用中,选择使用哪种方式要根据具体需求和性能考虑来决定。三、精确查询
精确查询是搜索引擎中常用的查询方式,特别适用于针对关键字、数值、日期、boolean等类型字段的精准检索。在酒店订购网站等应用中,用户通常希望根据特定的条件,如城市、星级、品牌、价格范围等,进行准确的信息检索。
下面将介绍在 Elasticsearch 中如何使用
term和range进行精确查询。3.1 term 查询
term查询用于根据词条的精确值进行查询。例如,在酒店订购网站中,用户希望查找位于上海的所有酒店,可以使用以下 DSL 语句:GET /hotel/_search { "query": { "term": { "city": { "value": "上海" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
查询结果:

上述查询返回了所有城市为上海的酒店信息。然而,要注意的是,
term查询对查询关键字的精确匹配要求较高。如果将查询的值更改为 “上海北京”,将找不到匹配的结果: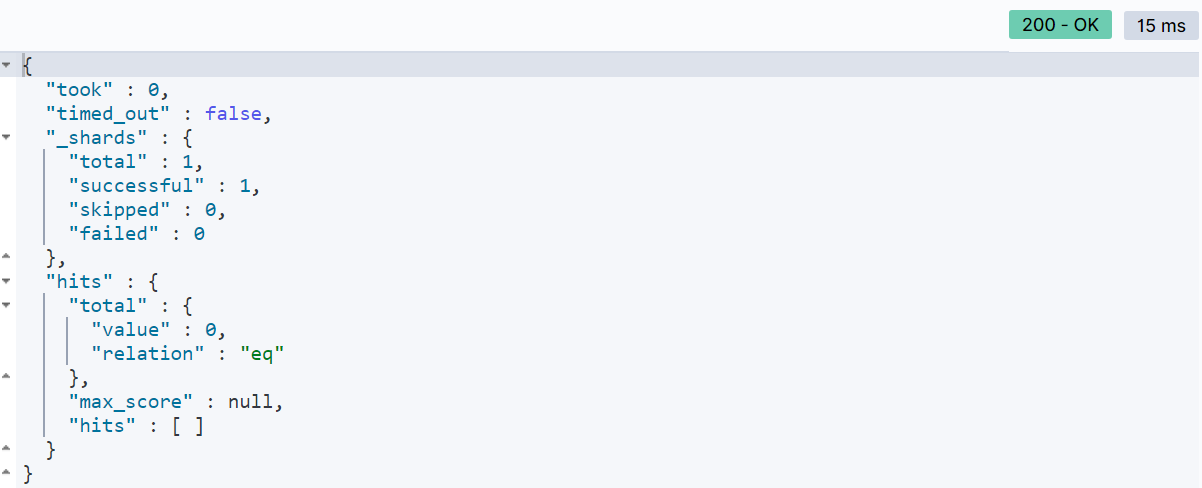
因此,在使用
term查询时,务必确保查询的关键字是准确的。3.2 range 查询
range查询用于根据值的范围进行查询,特别适用于数值型字段,比如价格范围。例如,用户希望查找价格在 100 到 200 之间的酒店,可以使用以下 DSL 语句:GET /hotel/_search { "query": { "range": { "price": { "gte": 100, "lte": 200 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
查询结果:
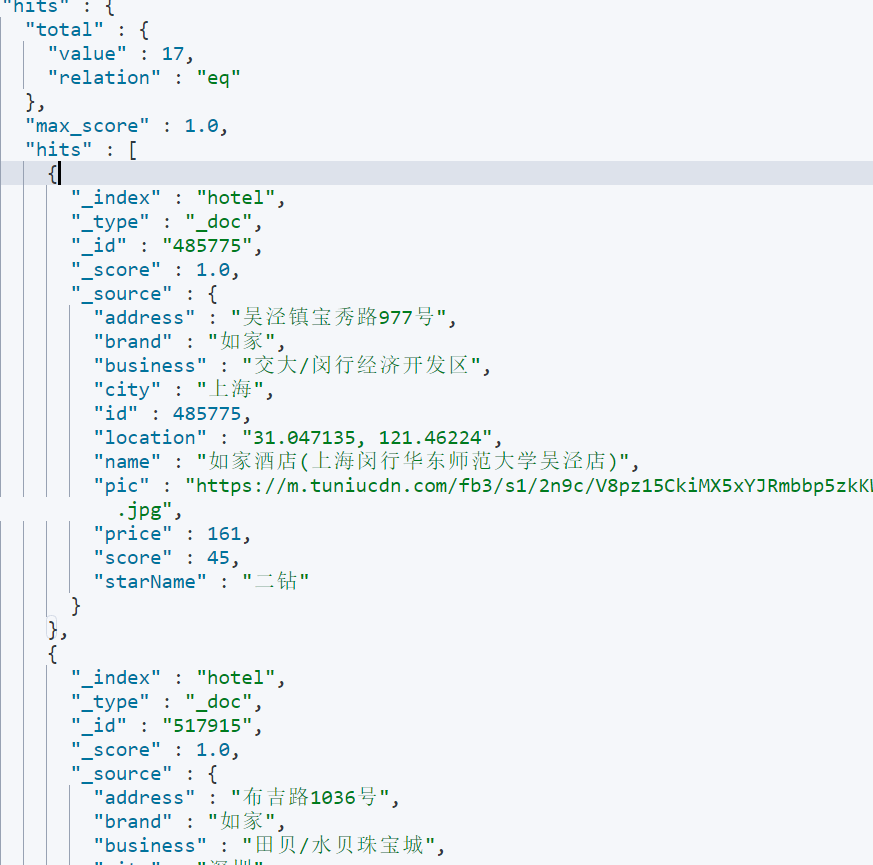
在上述查询中,使用了
gte表示大于等于某个值,而lte表示小于等于某个值。通过这样的查询,可以精确地获取符合价格范围的酒店信息。总的来说,精确查询在搜索引擎中是非常常用且实用的功能,通过合理使用
term和range查询,可以满足用户对于准确信息检索的需求。四、地理坐标查询
地理坐标查询是 Elasticsearch 中常见的功能之一,特别适用于需要根据地理位置信息进行搜索的场景,如查询附近的酒店、出租车、或者附近的人。下面介绍两种常用的地理坐标查询方式:
geo_bounding_box和geo_distance。4.1 geo_bounding_box 查询
geo_bounding_box查询用于查询geo_point值在某个矩形范围内的所有文档。以下是一个示例:GET /indexName/_search { "query": { "geo_bounding_box": { "FIELD": { "top_left": { "lat": 31.1, "lon": 121.5 }, "bottom_right": { "lat": 30.9, "lon": 121.7 } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
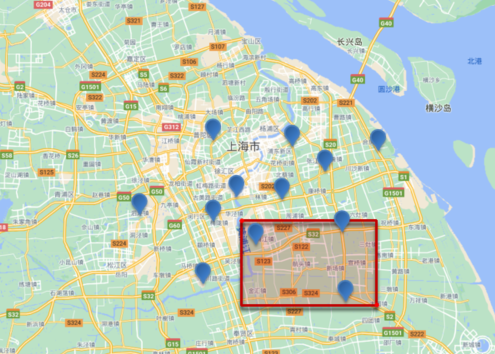
在这个例子中,通过指定矩形的左上角和右下角的经纬度,可以查询所有位置在这个矩形范围内的文档。
搜索范围示意图,形状为矩形:
4.2 geo_distance 查询
geo_distance查询用于查询到指定中心点距离小于某个距离值的所有文档。以下是一个示例:GET /indexName/_search { "query": { "geo_distance": { "distance": "15km", "FIELD": "31.21,121.5" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个例子中,通过指定中心点的经纬度和距离值,可以查询所有距离中心点小于 15 公里的文档。
搜索范围示意图,形状为圆:
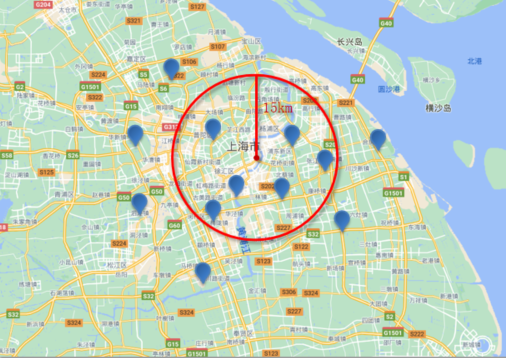
通过这两种方式,可以在地理坐标信息中实现灵活而精确的查询,满足用户在不同应用场景下的位置搜索需求。
五、复合查询
复合(compound)查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑,例如:
-
function score: 算分函数查询,可以控制文档相关性算分,控制文档排名,类似于百度搜索结果中一些顶置的广告。 -
Boolean Query:布尔查询,一个或多个查询子句的组合,子查询的组合方式有:- must:必须匹配每个子查询,类似“与”。
- should:选择性匹配子查询,类似“或”。
- must_not:必须不匹配,不参与算分,类似“非”。
- filter:必须匹配,不参与算分。
5.1 function score 查询
假设,现在文档中有一些是广告,我们希望这些广告在查询结果中是最靠前的,因此可以使用
function score查询来修改特定文档的打分,例如,给“如家”这个品牌的酒店排名靠前一定:为了实现这个目标,我们需要提供以下三个要素:
-
哪些文档需要算分加权?
- 品牌为如家的酒店。
-
算分函数是什么?
weight。
-
加权模式是什么?
- 乘积。
查询 DSL 语句如下:
GET /hotel/_search { "query": { "function_score": { "query": { "match": { "all": "上海" } }, "functions": [ { "filter": { "term": { "brand": "如家" } }, "weight": 10 } ], "boost_mode": "multiply" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
说明:
query:原始查询条件,搜索文档并根据相关性打分(query score)。filter:过滤条件,符合条件的文档才会被重新算分。weight:算分函数,算分函数的结果称为 function score ,将来会与 query score 运算,得到新算分。常见的算分函数有:weight:给一个常量值,作为函数结果(function score)。field_value_factor:用文档中的某个字段值作为函数结果。random_score:随机生成一个值,作为函数结果。script_score:自定义计算公式,公式结果作为函数结果。
boost_mode:加权模式,定义 function score 与 query score 的运算方式,包括:multiply:两者相乘。默认就是这个。replace:用 function score 替换 query score。- 其它:
sum、avg、max、min。
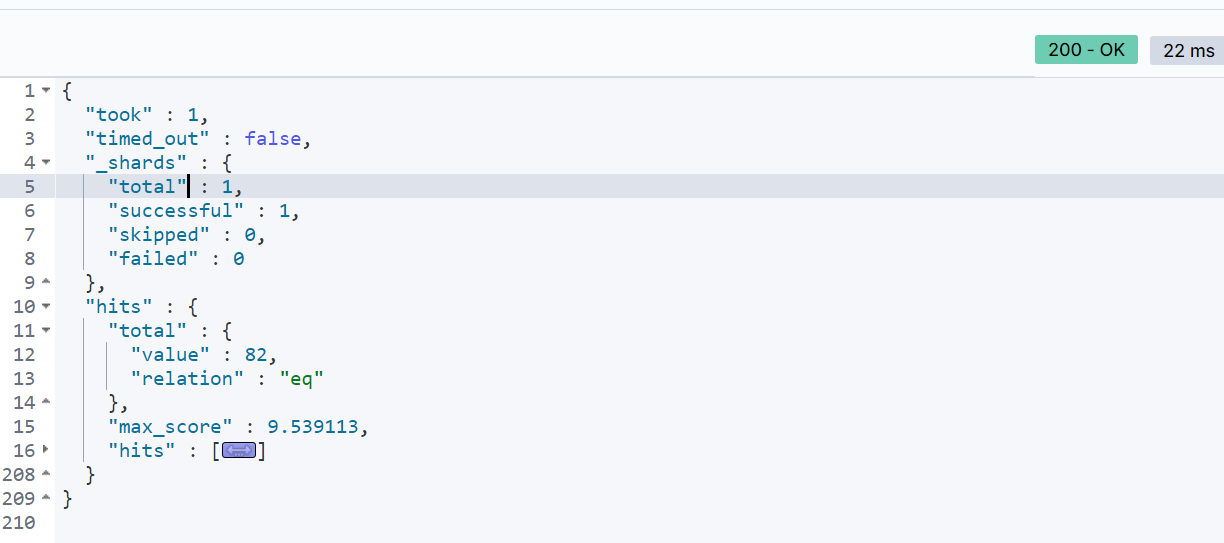
查询结果:
5.2 boolean 查询
例如,现在有一个查询需求:搜索名字包含“如家”,价格不高于400,在坐标
31.21,121.5周围 10km 范围内的酒店。GET /hotel/_search { "query": { "bool": { "must": [ { "match": { "name": "如家" } } ], "must_not": [ { "range": { "price": { "gte": 400 } } } ], "filter": [ { "geo_distance": { "distance": "10km", "location": { "lat": 31.21, "lon": 121.5 } } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
说明:
must:必须匹配每个子查询,类似“与”。must_not:必须不匹配,不参与算分,类似“非”。filter:必须匹配,不参与算分。
搜索结果:
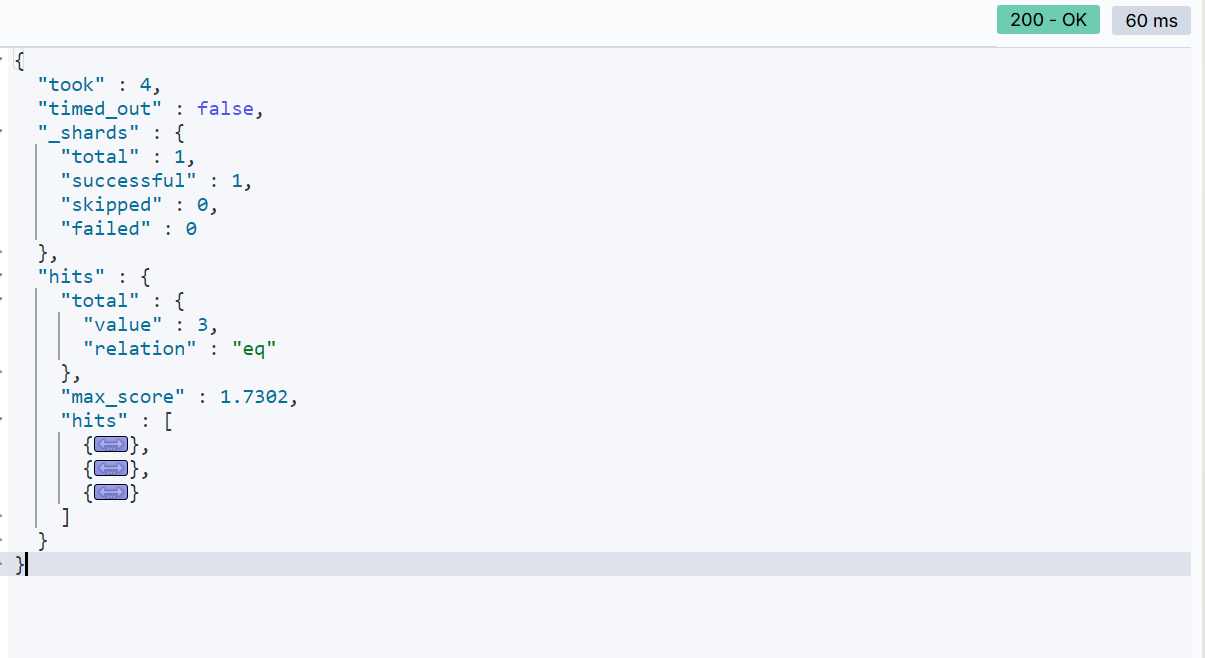
通过这个例子,我们可以看到如何使用布尔查询来组合多个条件,实现更精确的搜索。
六、对搜索结果的处理
6.1 对搜索结果进行排序
ElasticSearch 支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword 类型、数值类型、地理坐标类型、日期类型等。
示例一:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序
评价是
score字段,价格是price字段,按照顺序添加两个排序规则即可。GET /hotel/_search { "query": { "match_all": {} }, "sort": [ { "score": "desc" }, { "price": "asc" } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
示例二:实现对酒店数据按照到(121.507712,31.224612)的位置坐标的距离升序排序
获取经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/。
GET /hotel/_search { "query": { "match_all": {} }, "sort": [ { "_geo_distance": { "location": { "lat": 31.224612, "lon": 121.507712 }, "order": "asc", "unit": "km" } } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
6.2 对搜索结果进行分页
ElasticSearch 默认情况下只返回 top 10 的数据。而如果要查询更多数据就需要修改分页参数了。ElasticSearch 中通过修改
from、size参数来控制要返回的分页结果。基本语法如下:
GET /hotel/_search { "query": { "match_all": {} }, "from": 990, // 分页开始的位置,默认为0 "size": 10, // 期望获取的文档总数 "sort": [ {"price": "asc"} ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
示例:使用
match_all查询,然后对结果进行分页GET /hotel/_search { "query": { "match_all": {} }, "from": 0, "size": 5 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
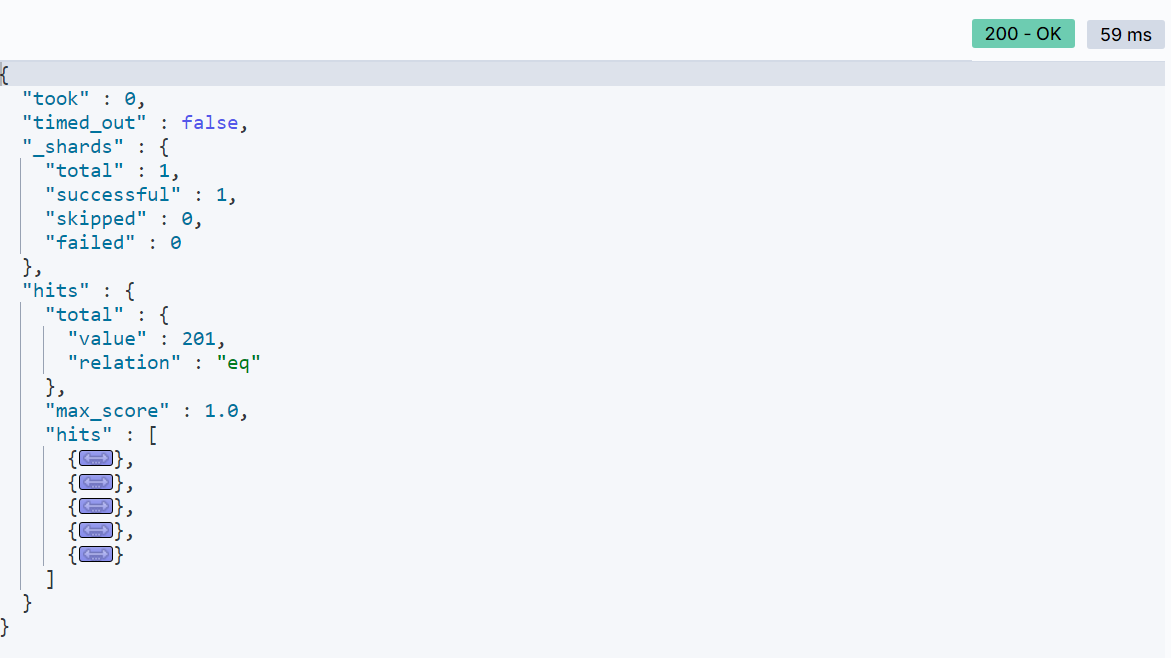
搜索结果,现在就只展示5条结果了:
深度分页问题:
ES是分布式的,所以会面临深度分页问题。例如按 price 排序后,获取 from = 990,size =10 的数据:
- 首先在每个数据分片上都排序并查询前1000条文档。
- 然后将所有节点的结果聚合,在内存中重新排序选出前1000条文档。
- 最后从这1000条中,选取从990开始的10条文档。
如果搜索页数过深,或者结果集(from + size)越大,对内存和 CPU 的消耗也越高。因此 ES 设定结果集查询的上限是10000。
深度分页解决方案:
针对深度分页,ES提供了两种解决方案:
- **search after:**分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- **scroll:**原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
6.3 对搜索结果中的搜索关键字高亮处理
高亮处理,就是在搜索结果中把搜索关键字突出显示。
原理:
- 将搜索结果中的关键字用标签标记出来。
- 在页面中给标签添加 CSS 样式。
语法:
GET /hotel/_search { "query": { "match": { "FIELD": "TEXT" } }, "highlight": { "fields": { "FIELD": { "pre_tags": "", // 用来标记高亮字段的前置标签 "post_tags": "" // 用来标记高亮字段的后置标签 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
示例:对搜索的品牌名称进行高亮处理
GET /hotel/_search { "query": { "match": { "brand": "如家" } }, "highlight": { "fields": { "brand": { "pre_tags": "", "post_tags": "" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
搜索结果:
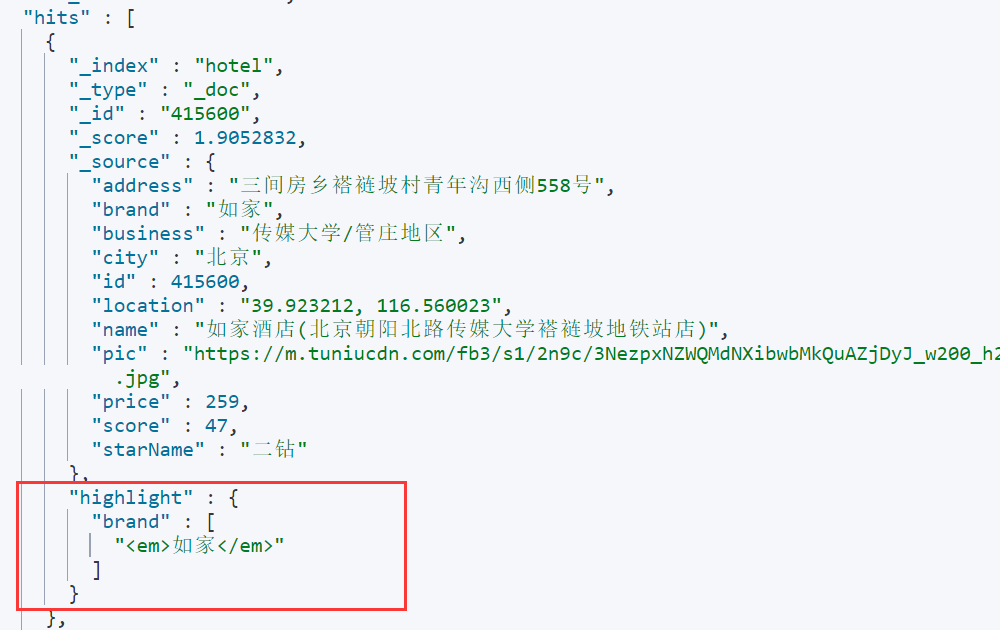
以上便是对ElasticSearch搜索结果进行排序、分页和关键字高亮处理的一些示例和基本操作。
-
相关阅读:
Python多线程和多进程:初步了解
【2023年11月第四版教材】专题3 - 10大管理49过程输入、输出、工具和技术总结
Spread for ASP.NET 15.2 个性化需求中文版
设计模式——七大原则详解
window屏幕录制
C# QRCode二维码的解析与生成
文件操作和IO
springboot昆明学院档案管理系统毕业设计源码311758
sizeof和strlen求取数组&指针之辨析
DIFM网络详解及复现
- 原文地址:https://blog.csdn.net/qq_61635026/article/details/133688961
