-
mongoDB 性能优化
前言
如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。
而且听说点赞的人每天的运气都不会太差,实在白嫖的话,那欢迎常来啊!!!
mongoDB 性能优化
1. explain方法来查看查询的执行计划
使用explain方法来查看查询的执行计划。explain方法提供了关于查询性能的详细信息,包括查询使用的索引、文档的扫描数量等。
db.collection.find(query).explain("executionStats")- 1
executionStats参数告诉MongoDB只返回执行统计信息。
示例:
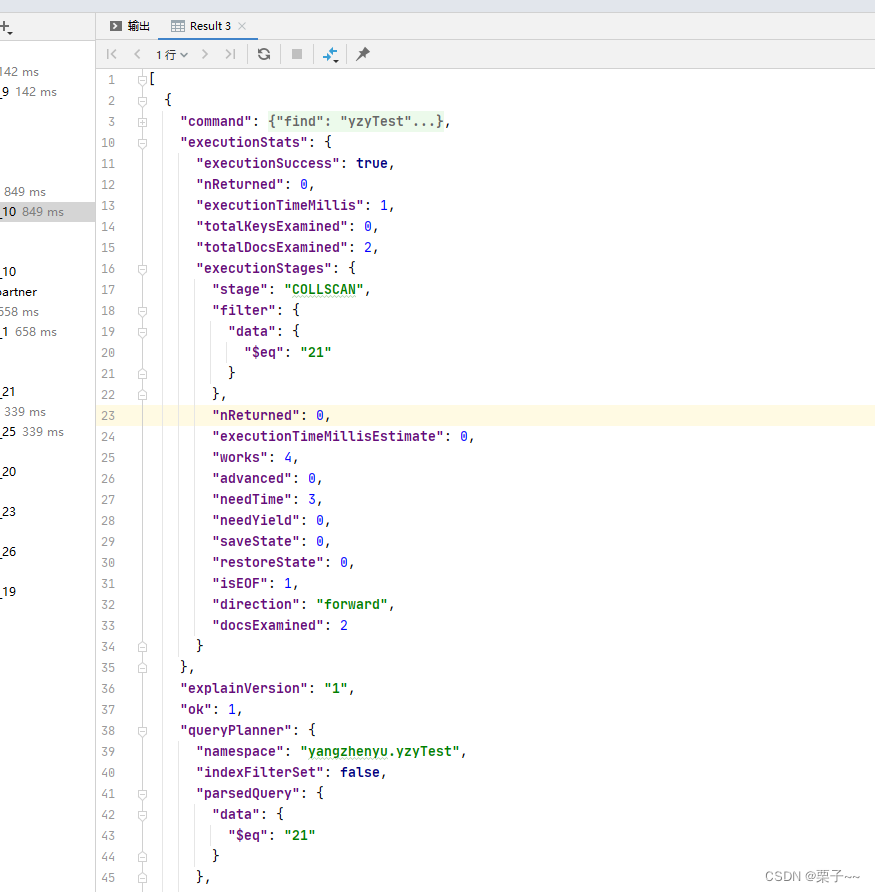

执行上述查询后,MongoDB会返回一个包含执行计划信息的文档。你可以查看该文档来分析查询的性能。
- plannerVersion: 查询规划器的版本。
- namespace: 查询的命名空间(数据库和集合)。
- executionSuccess: 指示查询是否成功执行。
- nReturned: 返回的文档数量。
- executionTimeMillis: 查询的执行时间(以毫秒为单位)。
- winningPlan,它提供了MongoDB选择的执行计划的详细信息,包括使用的索引、扫描的文档数量等。
winningPlan是MongoDB查询执行计划中的一个关键部分,它描述了MongoDB选择的执行计划,包括使用的索引、查询策略等。分析winningPlan可以帮助你了解MongoDB是如何执行查询的,以便更好地优化查询性能。
以下是一些常见的要点,可以帮助你分析winningPlan:
- 查询的阶段(Stage): winningPlan中的stage字段描述了MongoDB执行查询的主要阶段。常见的阶段包括COLLSCAN(集合扫描)、IXSCAN(索引扫描)、FETCH(从索引中获取文档)等。了解查询的主要阶段有助于确定查询性能的瓶颈。
- 索引使用: 如果winningPlan中的阶段是IXSCAN,表示MongoDB正在使用一个或多个索引来执行查询。你可以查看winningPlan中的inputStage字段,以了解使用的具体索引。优化索引的选择和使用可以显著提高查询性能。
- 筛选条件: winningPlan中的filter字段描述了用于筛选文档的条件。这可以帮助你确定MongoDB是否有效地使用索引来减少文档扫描的数量。
- 索引覆盖: 如果winningPlan中的阶段是FETCH,表示MongoDB在索引扫描后需要额外的步骤来获取文档。优化查询性能的一种方式是尽量让索引覆盖查询,即索引本身包含了查询所需的字段,而无需额外获取文档。
- 文档数量: winningPlan中通常包括有关查询返回的文档数量的信息,如nReturned。这对于评估查询的效率和性能至关重要。
- 排序和限制: 如果查询中包括排序和限制条件,winningPlan中也会包含这些信息。排序和限制条件可能会影响查询性能,特别是如果没有适当的索引支持。
- 索引覆盖: 查询计划中的 indexOnly 指示是否使用了索引覆盖,即查询结果是否可以完全从索引中获取,而无需额外的文档检索。索引覆盖可以显著提高查询性能。
- 其他信息: winningPlan中可能还包含其他信息,例如direction字段用于表示索引扫描的方向(正向或反向),以及其他执行计划相关的信息。
综合分析上述信息,你可以确定查询性能的瓶颈,并采取相应的优化措施,例如创建合适的索引、调整查询条件、减少文档扫描等,以提高查询的效率和性能。请注意,分析查询计划可能需要一定的经验,特别是在复杂的查询场景中,但它是优化MongoDB查询性能的关键步骤。
2. 查看mongoDB 集合的索引
use your_database db.myCollection.getIndexes()- 1
- 2
示例:
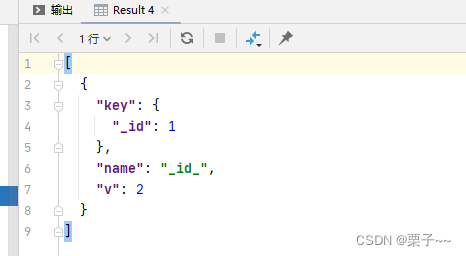
- key: 这部分指示了索引的字段和排序方式。在你的示例中,“_id”: 1 表示这个索引是基于 _id 字段创建的,而 1 表示按升序排序。MongoDB默认为每个集合创建一个唯一索引,用于快速查找文档。
- name: 这是索引的名称。在你的示例中,索引名称是 “id”,这是默认的命名规则,通常是字段名加下划线。
- ns: 这是索引所属的命名空间。在你的示例中,索引属于 “scfop-api-partner” 数据库中的 “dataSyncRequestVO” 集合。
- v: 这是索引版本的信息。在你的示例中,版本号为 2,这表示索引是MongoDB的版本2索引格式。
总结来说,这个输出告诉你在 “scfop-api-partner” 数据库的 “dataSyncRequestVO” 集合上存在一个名为 “id” 的索引,它是一个升序索引,用于加速对 _id 字段的查找。这个索引通常是自动生成的,以确保每个文档都有唯一的 _id 值,这是MongoDB文档的默认主键。
3. mongoDB 怎么添加索引
使用db.collection.createIndex()方法来创建索引。这个方法用于在指定集合上创建一个或多个索引。
这将在名为 “yourCollection” 的集合上创建一个基于 “yourField” 字段的升序索引。
db.yourCollection.createIndex({ yourField: 1 });- 1
创建多个单索引:
db.yourCollection.createIndexes([{'yourField':1},{'yourField':1},{'yourField':1}])- 1
如果你想创建一个复合索引(多个字段的组合索引),可以传递一个包含多个字段和排序方式的对象:
db.yourCollection.createIndex({ field1: 1, field2: -1 });- 1
这将在名为 “yourCollection” 的集合上创建一个基于 “field1” 字段升序和 “field2” 字段降序的复合索引。
你也可以指定其他选项来定制索引,例如唯一索引、稀疏索引等。这些选项可以作为第二个参数传递给 createIndex() 方法。
db.yourCollection.createIndex({ yourField: 1 }, { unique: true, sparse: true });- 1
在这个例子中,我们创建了一个唯一索引,该索引只包含具有 “yourField” 字段的文档,并且该字段可以有缺失值(稀疏索引)。
记得在使用索引前,要考虑你的数据模型、查询模式和性能需求来选择合适的索引策略。索引可以显著提高查询效率,但不当使用也可能会导致资源浪费和性能下降。4. 升序索引与降序索引是什么意思
升序索引(Ascending Index):
升序索引是最常见的索引类型,也是MongoDB默认创建的索引类型。在升序索引中,索引键的值按照从小到大(A到Z、0到9)的顺序排序。升序索引在排序字段上提供了高效的查询性能,因为它使得MongoDB可以快速定位和遍历索引,尤其是在范围查询(例如 g t 、 gt、 gt、lt)和排序操作中。
在MongoDB中,如果你创建一个索引而没有明确指定排序方式,MongoDB将默认使用升序索引。
例如,以下命令将创建一个基于字段 fieldName 的升序索引:db.collection.createIndex({ fieldName: 1 });- 1
降序索引(Descending Index):
降序索引与升序索引相反,它按照从大到小(Z到A、9到0)的顺序排序索引键的值。降序索引在某些查询场景中也可以提供性能优势,尤其是在需要按照字段降序排序的查询操作中。
你可以通过将字段的排序方式设置为 -1 来创建一个降序索引。例如:db.collection.createIndex({ fieldName: -1 });- 1
这将创建一个基于 fieldName 字段的降序索引。
需要注意的是,使用降序索引可能会增加索引的维护成本,因为MongoDB需要额外的空间和计算来维护降序索引。因此,在选择索引排序方式时,需要根据实际的查询需求和性能测试结果来决定。 -
相关阅读:
【常用的 SVN 命令及简要示例】
上周热点回顾(6.19-6.25)
请收藏:流固耦合经验总结(一)
图数据库(Neo4j)入门
阿里巴巴Java开发编程规约(整理详细版)
图像分割竟能如此丝滑、高清?大规模二分图像分割数据集DIS5K解读
CentOS 7 安装指定版本的python环境
Vue3 生命周期
CentOS yum update
第十二章-系统调用
- 原文地址:https://blog.csdn.net/weixin_38316697/article/details/133776344