-
CV计算机视觉每日开源代码Paper with code速览-2023.10.10
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
1.【基础网络架构:Transformer】Hierarchical Side-Tuning for Vision Transformers
-
开源代码(即将开源):https://github.com/AFeng-x/HST

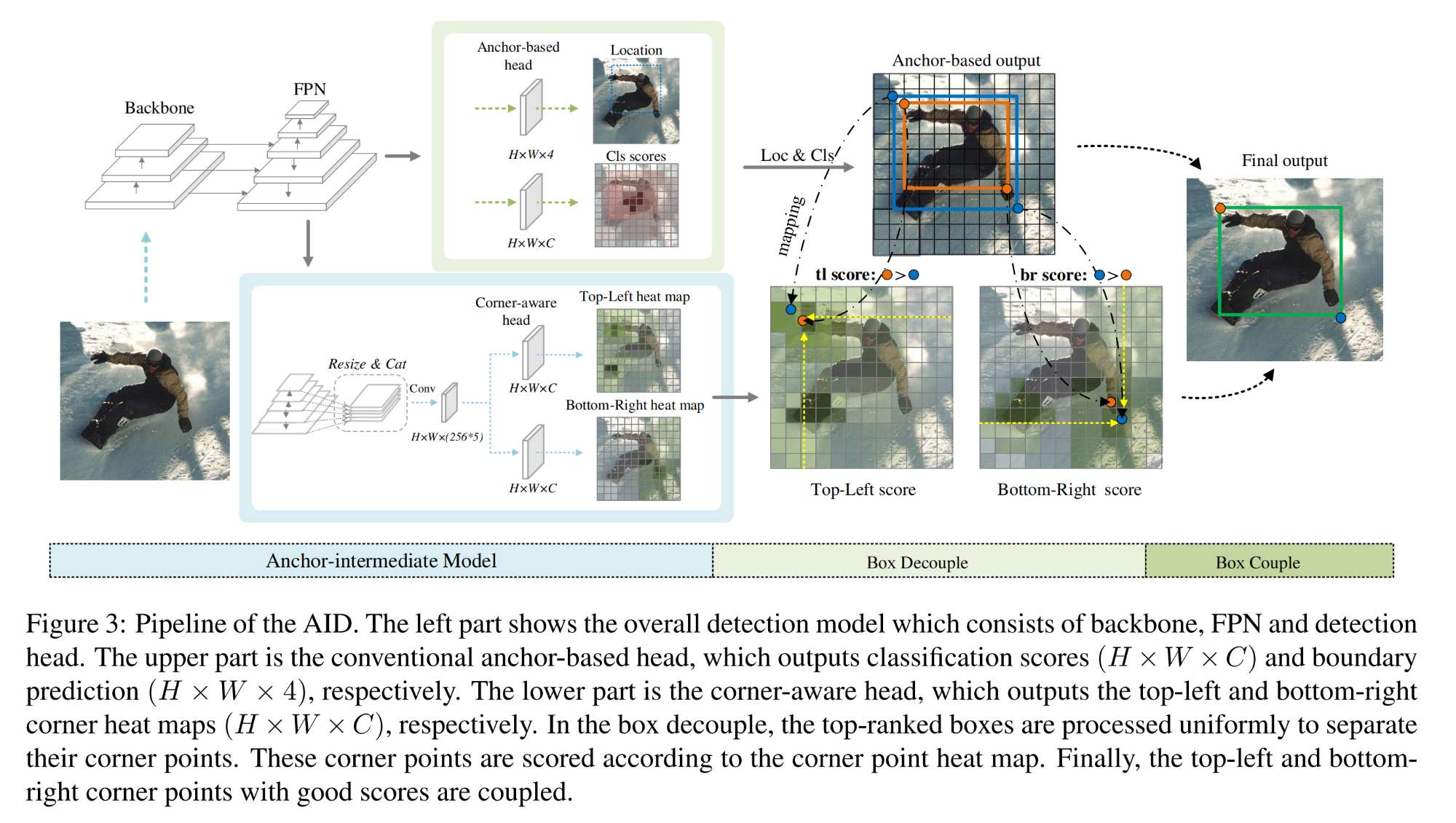
2.【目标检测】Anchor-Intermediate Detector: Decoupling and Coupling Bounding Boxes for Accurate Object Detection
-
开源代码(即将开源):https://github.com/YilongLv/AID
3.【目标检测】How to effectively train an ensemble of Faster R-CNN object detectors to quantify uncertainty

4.【目标检测】HalluciDet: Hallucinating RGB Modality for Person Detection Through Privileged Information
-
代码即将开源

5.【语义分割】Towards Dynamic and Small Objects Refinement for Unsupervised Domain Adaptative Nighttime Semantic Segmentation
-
工程主页:DSRNSS
-
代码即将开源

6.【目标跟踪】Lightweight Full-Convolutional Siamese Tracker

7.【3D目标检测】Towards Fair and Comprehensive Comparisons for Image-Based 3D Object Detection
-
开源代码(即将开源):https://github.com/OpenGVLab/3dodi

8.【点云】Bidirectional Knowledge Reconfiguration for Lightweight Point Cloud Analysis

9.【点云3D目标检测】Uni3DETR: Unified 3D Detection Transformer

10.【点云3D目标检测】Fully Sparse Long Range 3D Object Detection Using Range Experts and Multimodal Virtual Points

11.【医学图像分割】Cross-head mutual Mean-Teaching for semi-supervised medical image segmentation

12.【医学图像分割】A Simple and Robust Framework for Cross-Modality Medical Image Segmentation applied to Vision Transformers

13.【医学图像分割:3D】HartleyMHA: Self-Attention in Frequency Domain for Resolution-Robust and Parameter-Efficient 3D Image Segmentation

14.【多模态】FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing

15.【多模态】Interpreting CLIP's Image Representation via Text-Based Decomposition

16.【多模态】UReader: Universal OCR-free Visually-situated Language Understanding with Multimodal Large Language Model

17.【多模态】Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data

18.【多模态】Symmetrical Linguistic Feature Distillation with CLIP for Scene Text Recognition

19.【多模态】HowToCaption: Prompting LLMs to Transform Video Annotations at Scale

20.【多模态】Rephrase, Augment, Reason: Visual Grounding of Questions for Vision-Language Models

21.【自动驾驶:深度估计】Federated Self-Supervised Learning of Monocular Depth Estimators for Autonomous Vehicles

22.【轨迹预测】SocialCircle: Learning the Angle-based Social Interaction Representation for Pedestrian Trajectory Prediction

23.【图像检索】Sentence-level Prompts Benefit Composed Image Retrieval
-
开源代码(即将开源):https://github.com/chunmeifeng/SPRC

论文已打包,点击进入—>下载界面
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
-
相关阅读:
Python基础入门篇【3】--变量与关键字
Linux网卡状态查看
外语配音软件“布谷鸟配音“和ffmepg转换软件的使用以及SYD_Calculator提取文件到C语言
spring-cloud-alibaba-dubbo-issues1805修复
代码随想录58——单调栈:739每日温度、 496下一个更大元素I
Vue 2.0——数据与方法(官方文档解读)
C#通过Process调用Python脚本
搭建网课查题公众号教程 内含接口
springboot和springcloudAlibaba的版本对应关系
物联网工业串口转WiFi模块 无线路由WiFi模块的选型
- 原文地址:https://blog.csdn.net/zhangkai950121/article/details/133772198