-
深度学习DAY3:FFNNLM前馈神经网络语言模型
1 神经网络语言模型NNLM的提出
文章:自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT)
https://www.cnblogs.com/robert-dlut/p/9824346.html语言模型不需要人工标注语料(属于自监督模型),所以语言模型能够从无限制的大规模语料中,学习到丰富的语义知识。

1.1 n-gram模型问题:
①模型高度依赖训练语料,泛化能力差,也就是不同文本之间的n-gram差异很大
②模型估算概率时遇到的数据稀疏,平滑后效果也不好
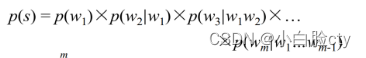
- 点—— 用n-gram语料库训练出来的每个词序列的出现的概率
- 平滑曲线——所有词序列概率相乘所得的P(S),也就是有这些词序列所组成的句子的出现概率
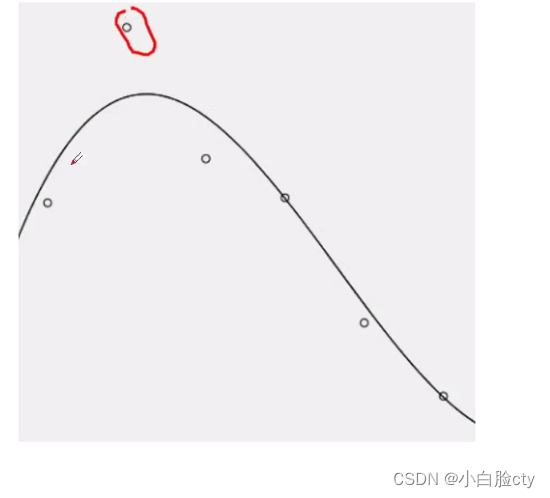
- 离散点与曲线的距离——点1是词序列1的概率,但是离散词序列点1没在平滑曲线L上面,也就是n-gram模型会将该离散词序列1附近的另一个词序列2(在平滑曲线上)的概率作为离散词序列点1的概率去建立模型。而词序列2不一定在语料库中有出现
因此,n-gram所建立的模型对某个句子进行预测时,会有较大的概率损失。
这是无论怎么平滑都无法避免的,因为建立模型的概率点是离散的。
特别是差异很大的异常点,会对模型的结果造成比较大的影响
③n元模型无法建立长期联系
④n-gram以离散符号为统计单元,无法体现语义相似性

由于数据是离散的,如果特别能没有在语料库出现过,而能在语料库中的出现概率很大但是特别能和能意思相近,那么根据n-gram的计算原理,两个已经意思相近的句子的出现概率可能一个为0,一个很大,而实际上两个句子的出现概率差不多,因此会有很大的概率损失误差。1.2 NNLM 的提出
神经网络NN
为了解决这个问题,我们在将神经网络(NN)引入到了连续空间的语言建模中。NN 包括前馈神经网络(FFNN)、循环神经网络(RNN)、卷积神经网络(CNN)可以自动学习特征和连续的表征。因此,人们希望将 NN 应用于 LM,甚至其他的 NLP 任务,从而考虑自然语言的离散性、组合性和稀疏性。
n-gram学出了离散词序列出现频率点,而深度学习的神经网络语言模型直接学习出了平滑曲线
也就是不同于n-gram里面的平滑曲线是“模糊的拟合”,深度学习的平滑曲线是“更细粒度的拟合”。
NNLM可以联系长期上下文
2 前馈神经网络FFNN
别称多层感知器(multilayer perceptrons)
2.1 包含两层隐藏层的前馈神经网络

- 每一个箭头都带着权重,表示其输入变量的重要程度
- 隐藏层中每个圆圈代表一个神经元,神经元对应着某个函数,通常都是一个非线性函数σ(sigmoid最常用,也有换成ReUL、tanh的),该类非线性函数在NN中被称为激活函数。
- 隐藏层的结果会通过线性加权组合变成下一个层的输入
- 输出层神经元的个数取决的任务的分类类别个数
- 一些层是没有线性激活函数的,比如sigmoid函数
2.2 神经元
每个神经元都是一个函数。

2.2.1 公式:
y = σ( Σ(Wi * Xi) + b)
输入:x
输出:y
权重:Xi对应权重Wi
激活函数σ:sigmoid、tanh、ReLU参数b:表示偏置/阈值,b是一个常数。b与加权求和值相加,然后再经过激活函数。这有助于调整神经元的灵敏度和响应特定类型的输入。
在神经元网络中,偏置是一种可学习的参数,用于调整神经元的激活值。
意义:
调整神经元的激活函数在输入为零时的截距位置。2.2.2 神经元处理步骤:
1 对输入加权求和,加上偏置b
得到初步的点估计值
h =(Σ(W * X)+b)
意义:
-
特征加权重要性:权重(weights)表示了每个输入特征的重要性,它们决定了每个特征在神经元的决策中所占的比重。通过适当调整权重,神经元可以学习到哪些特征对于问题的解决更为关键,从而提高网络的性能。
-
偏置项引入平移:偏置项(bias)是一个常数,它的作用是引入一个平移,允许神经元在没有任何输入信号时也能发出非零的响应。这对于模型的表达能力很重要,因为它允许神经元不仅仅依赖于输入的线性组合,还能引入非线性决策。
实例:
房价预测
假设我们正在构建一个神经网络来预测房价。我们有三个 输入特征:房屋面积(Area)、卧室数量(Bedrooms)、和附近学校的评分(School_Rating)。每个特征都有对应的权重,用来衡量它们在预测房价中的重要性。
- 权重1(w1)对应房屋面积,表示房屋面积对房价的影响程度。
- 权重2(w2)对应卧室数量,表示卧室数量对房价的影响程度。
- 权重3(w3)对应附近学校的评分,表示学校评分对房价的影响程度。
假设偏置项(b)为-10000,这意味着即使所有输入特征都为零,房价预测也不会降到零,因为偏置项引入了一个平移。这是因为即使房屋没有面积、没有卧室、学校评分为零,房价仍然有一个基本价值。
通过对这些输入进行加权求和,加上偏置项,神经元可以计算一个房价的初始估计值。然后,这个初始估计值将被送入激活函数,例如线性激活函数、Sigmoid函数或ReLU函数,以引入非线性性质并产生最终的房价预测。
2 激活函数映射——引入非线性性质
将h的值通过激活函数σ映射到一个特定的输出范围内的一个值,通常是[0, 1]或[-1, 1]
σ(h)
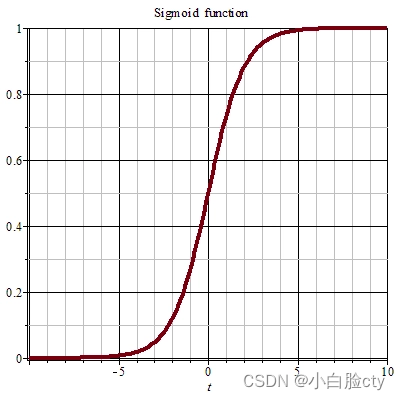
意义:引入非线性性质,使神经网络能够适应更加复杂的数据模式和问题。例子
二元分类
假设我们有一个二元分类问题,要根据一些特征来预测一封电子邮件是垃圾邮件(标记为1)还是非垃圾邮件(标记为0)。神经网络的最后一层输出单元通常需要产生一个在[0, 1]范围内的值,表示某封邮件属于垃圾邮件的概率。这时,Sigmoid激活函数非常适合用于最后一层,因为它可以将加权求和值映射到[0, 1]之间的范围。
例如,如果某封邮件的加权求和值为0,经过Sigmoid激活后,输出为0.5,表示该邮件属于垃圾邮件和非垃圾邮件的概率相等。如果加权求和值远远大于0,例如10,经过Sigmoid激活后,输出接近于1,表示邮件极有可能是垃圾邮件。反之,如果加权求和值远远小于0,例如-10,经过Sigmoid激活后,输出接近于0,表示邮件很可能是非垃圾邮件。
这样,我们可以利用Sigmoid函数将连续的加权求和值映射到概率值,方便进行分类决策。
③
3 前馈神经网络语言模型FFNNLM
(Feed Forward Neural Language Model )
前馈神经网络语言模型(FFNNLM)由 Bengio 等人于 2003 年提出,它通过学习一个单词的分布式表征(将单词表征为一个被称为「嵌入」的低维向量)来克服维数诅咒。FFNNLM 的性能要优于 N 元语言模型。
该语言模型使用了一个三层前馈神经网络来进行建模。其中有趣的发现了第一层参数,用做词表示不仅低维紧密,而且能够蕴涵语义,也就为现在大家都用的词向量(例如word2vec)打下了基础
Word2Vec是Google公司于2013年发布的一个开源词向量工具包。该项目的算法理论参考了Bengio 在2003年设计的神经网络语言模型。由于此神经网络模型使用了两次非线性变换(tanh、softmax),网络参数很多,训练缓慢,因此不适合大语料。Mikolov团队对其做了简化,实现了Word2Vec词向量模型。 ——《NLP汉语自然语言处理原理与实践》
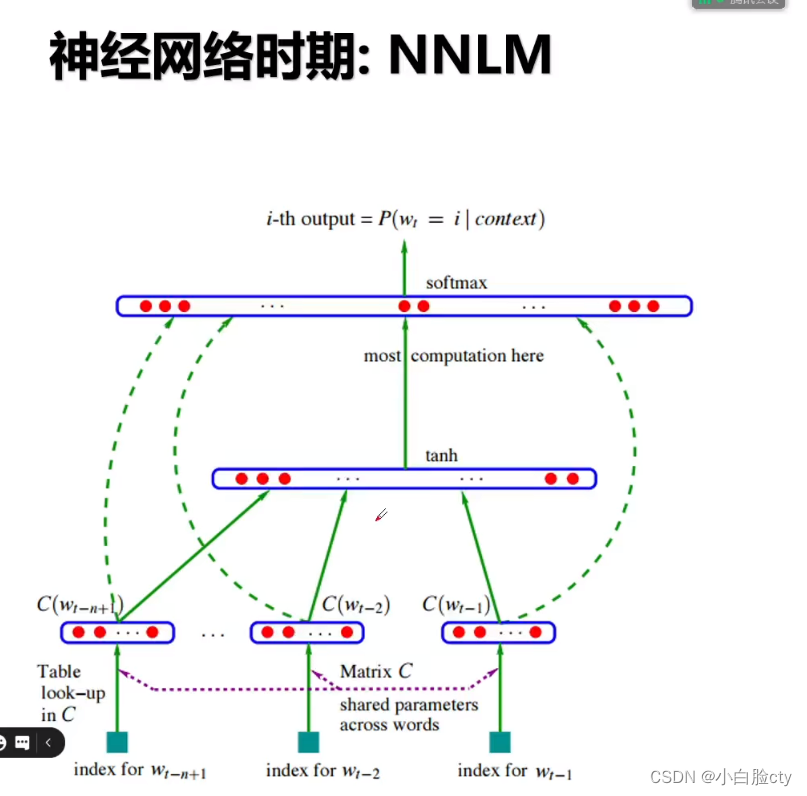

右上方橙色表格为词向量矩阵,对应下面的"V"
NNLM北语讲解3.2 LSTM-RNNLM长短期记忆循环神经网络模型
Mikolov 等人于 2010 年提出了 RNN 语言模型(RNNLM),理论上可以记忆无限个单词,可以看作"无穷元语法" (∞-gram)。
RNN解决了学习长期依赖问题,能够联系上下文
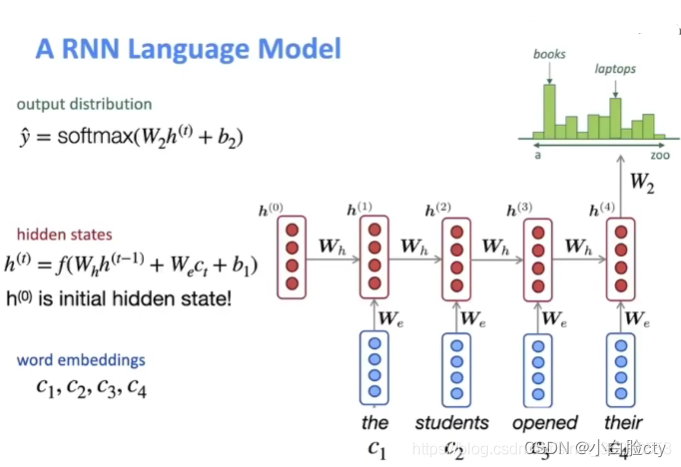
是否三元或者四元甚至更高阶的模型就能覆盖所有的语言现象呢?答案显然是否定的。因为自然语言中,上下文之间的相关性可能跨度非常大,甚至可以从一个段落跨到另一个段落。因此,即使模型的阶数再提高,对这种情况也无可奈何,这就是马尔可夫假设的局限性,这时就要采用其他一些长程的依赖性(Long DistanceDependency)来解决这个问题了。——《数学之美》
参考
语言模型(N-Gram
N-gram的简单的介绍
N-Gram语言模型
语言模型(LM)和循环神经网络(RNNs
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT
【研究前沿】神经网络语言模型综述_单词
NLP:n-gram模型
前馈网络 -
相关阅读:
关于#python#的问题:flask怎么在接口发送响应后紧跟着触发目标函数啊
【编程之路】面试必刷TOP101:链表(11-16,Python实现)
【电源专题】什么是开关稳压器
二面头条、三面拼多多、五面蚂蚁分享面经总结,助你拿大厂offer
[Linux] 网络套接字编程之实现简单的TCP网络程序(下)
租户配置、sql及代码讲解
STL之queue
L1&L2,范数&损失
GAT解读graph attention network
Cadence Allegro学习笔记【原理图篇】
- 原文地址:https://blog.csdn.net/m0_62865498/article/details/133744568