-
java面试题
1.Spring、SpringMVC、SpringBoot
1.1 Spring如何解决循环依赖, 二级缓存能不能解决循环依赖, 为什么要用三级缓存
1.1.1 什么是循环依赖
循环依赖其实就是循环引用, 简单来说, 就是两个或两个以上的bean互相持有对象, 形成闭环. 例如A依赖于B, B依赖于C, 而C又依赖于A
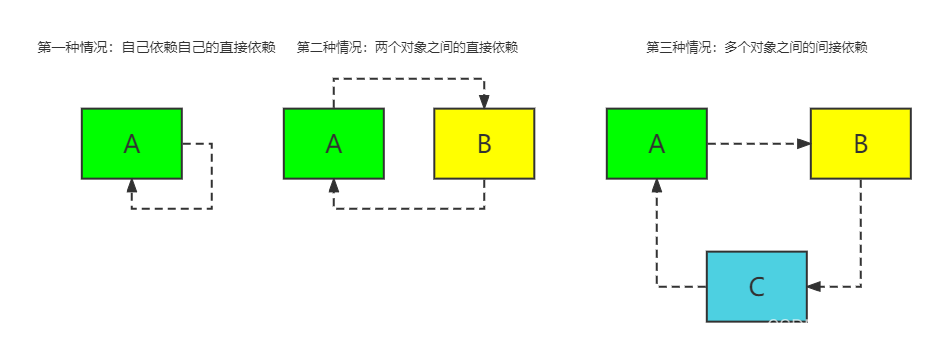
1.1.2 Spring解决循环依赖的思想
Spring单例对象的初始化主要分为三个步骤:
- 实例化: 其实就是调用对象的构造方法实例化对象
- 属性注入: 对bean的依赖属性进行填充
- 初始化: 属性注入成功后, 执行自定义初始化
循环依赖主要发生在第一、第二步骤, 也就是构造器循环依赖和属性循环依赖
Spring解决循环依赖也是从bean的初始化过程着手的, 对于单例来说, 在Spring容器整个生命周期内, 有且只有一个对象, 所以很容易想到这个对象应该存在Cache中, Spring为了解决单例的循环依赖, 使用了三级缓存
1.1.3 三级缓存
所谓三级缓存, 其实就是存放不同状态下的bean
- singletonObjects 一级缓存
用于保存实例化、注入、初始化完成的bean实例 - earlySingletonObjects 二级缓存
用于保存实例化完成的bean实例(这个bean中的属性还没被赋值) - singletonFactories 三级缓存
用于保存bean创建工厂,以便于后面扩展有机会创建代理对象。
下面的代码就是我们获取bean的逻辑
protected Object getSingleton(String beanName, boolean allowEarlyReference) { Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this.singletonObjects) { singletonObject = this.earlySingletonObjects.get(beanName); if (singletonObject == null && allowEarlyReference) { ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } return singletonObject; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
上面的代码需要解释两个参数:
- allowEarlyReference: 是否允许从singletonFactories中通过getObject拿到对象
- isSingletonCurrentlyInCreation:
判断当前单例bean是否正在创建中,也就是没有初始化完成(比如A的构造器依赖了B对象所以得先去创建B对象,
或则在A的populateBean过程中依赖了B对象,得先去创建B对象,这时的A就是处于创建中的状态。)
Spring解决循环依赖的诀窍是依赖于singletonFactories这个三级缓存
三级缓存的类型是ObjectFactory, 它是一个泛型接口, 只有一个方法

1.1.4 通过代码了解bean的创建过程
AbstractAutowireCapableBeanFactory#doCreateBean 我们一起来看下源码

如果bean是单例, 同时允许从singletonFactories获取bean,并且当前bean正在创建中, ,那么就把beanName放入三级缓存(singletonFactories)中:

这段代码发生在createBeanInstance之后,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行初始化的第二步和第三步),但是已经能被人认出来了(根据对象引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来让大家认识,让大家使用。1.1.5 Spring初始化bean的过程如下

- 首先尝试从一级缓存中获取serviceA实例,发现不存在并且serviceA不在创建过程中;
- serviceA完成了初始化的第一步(实例化:调用createBeanInstance方法,即调用默认构造方法实例化);
- 将自己(serviceA)提前曝光到singletonFactories中;
- 此时进行初始化的第二步(注入属性serviceB),发现自己依赖对象serviceB,此时就尝试去get(B),发现B还没有被实create,所以走create流程;
- serviceB完成了初始化的第一步(实例化:调用createBeanInstance方法,即调用默认构造方法实例化);
- 将自己(serviceB)提前曝光到singletonFactories中;
- 此时进行初始化的第二步(注入属性serviceA)
- 于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀);
- B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中;
- 此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中;
知道了这个原理时候,肯定就知道为啥Spring不能解决“A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题了!因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
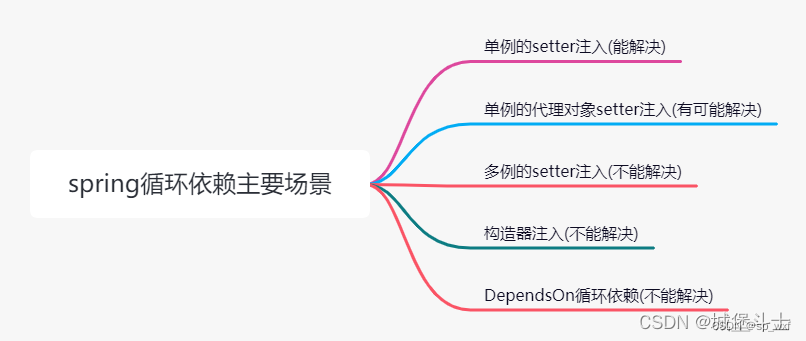
1.1.6 循环依赖的N种场景
1.1.7 总结
Spring解决循环依赖是通过三级缓存, 核心思想是将bean的实例化和属性赋值这两个过程剥离
我们先来简单了解一下三级缓存:
一级缓存: 保存实例化、注入、初始化完成的bean实例
二级缓存: 保存实例化完成的bean实例
三级缓存: 用于保存bean创建工厂,以便于后面扩展有机会创建代理对象

二级缓存的作用- 作为一个临时容器, 缓存实例化的bean
- 保证从工厂中获取的bean是同一个
三级缓存为什么可以提前暴露?
AOP除了后置处理(默认) , 还有一个提前处理, 简单来说AOP有两个入口, 通过提前处理就可以在实例化后, 属性赋值之前, 完成对bean的AOP, 将最终的bean存储到二级缓存中为什么不能只使用二级缓存?
二级缓存是为了存储bean的实例化对象,它无法感知bean是否需要进行aop(实例化>属性赋值>后置处理)参考内容:
spring如何解决循环依赖
spring为什么要使用三级缓存解决循环依赖
spring三级缓存之为大多数合理而设计1.2 IOC的启动过程
IOC容器的启动过程分为两个步骤
- 容器的启动阶段
- bean的初始化阶段

Spring中, 最基础的容器接口方法都是由BeanFactory定义的, 而BeanFactory的实现类采用了延迟加载, 而ApplicationContext在启动容器时就完成了所有bean的初始化1.2.1 IOC容器的初始化阶段
这个阶段主要是根据程序中定义的xml或者注解等bean的声明方式, 通过解析和加载后, 生成BeanDefinition, 然后将BeanDefinition注册到IOC容器中去
通过注解或者xml声明的bean都会解析得到一个BeanDefinition实体, 这个实体里会包含Bean的一些定义和基本的一些属性, 最终将BeanDefinition保存到一个map集合中, 从而去完成IOC的一个初始化, IOC容器的作用就是对这个bean的注册信息进行处理和维护

1.2.2 bean的初始化阶段
这个阶段会做两件事, 一是通过反射去实例化bean, 完成bean的依赖注入, 二是bean的使用, 通常我们通过@Autowired从IOC容器中获取指定bean的实例
1.3 SpringBoot如何实现自动配置?
SpringBoot的启动类上有一个@SpringBootApplication注解, 这个注解是SpringBoot项目必不可少的注解.自动配置的原理也跟这个注解有千丝万缕的关系
@SpringBootApplication是一个复合注解, 在其中有一个注解@EnableAutoConfiguration, 顾名思义: 开启自动配置

这个注解也是一个派生注解, 其中的关键功能是下面两个- @AutoConfigurationPackage
- @Import({AutoConfigurationImportSelector.class})
一、@AutoConfigurationPackage

static class Registrar implements ImportBeanDefinitionRegistrar, DeterminableImports { /** * 根据传入的元注解信息获取所在的包, 将包中组件类封装为数组进行注册, */ @Override public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) { register(registry, new PackageImports(metadata).getPackageNames().toArray(new String[0])); } @Override public Set<Object> determineImports(AnnotationMetadata metadata) { return Collections.singleton(new PackageImports(metadata)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
AutoConfigurationPackages将主配置类( @SpringBootApplication )所在的包及其子包里面的所有组件扫描到IOC容器中
二、@Import({AutoConfigurationImportSelector.class})
我们先来了解下SpringBoot加载配置类的方式- 使用注解@ComponentScan
- 使用注解@Import
- 导入普通类
- 导入选择器 ImportSelevtor
- 导入注册器 ImportBeanDefinitionRegistrar
为什么不用@ComponentScan?
这里不会使用@ComponentScan, 因为使用它很不方便, 开发人员需要记住所有三方jar包中的package名称, 写入到程序中为什么不导入普通类?
这比使用@ComponetScan还差劲, 因为需要记住第三方Jar包中的具体类名为什么不导入注册器?
也不恰当, BeanDefinition注册器的设计目标是对@Bean方法的一个补充, 从名字就可以看出, 它针对的是BeanDefinition层面的

1.3.1 AutoConfigurationImportSelector
AutoConfigurationImportSelector的selectImports()方法通过SpringFactoriesLoader.loadFactoryNames()扫描所有具有META-INF/spring.factories的jar包。
spring-boot-autoconfigure-x.x.x.x.jar里就有一个这样的spring.factories文件。
参考内容:
Spring Boot面试杀手锏————自动配置原理
SpringBoot自动配置原理
[spring三级缓存之为大多数合理而设计 -
相关阅读:
C# 背景与前景
vscode git 拉取报错 在签出前,请清理存储库工作树
vue--vuerouter缓存路由组件
UE4 AI行为树实现随机和跟随移动
react实现时钟翻牌效果
三、MyBatis-Plus 自动填充和乐观锁
mysql 查询在一张表不在另外一张表的记录
Eureka
Jenkins汉化设置
Axios在vue项目中的基本用法
- 原文地址:https://blog.csdn.net/qq_24099547/article/details/133746903
