-
【数据分类】基于麻雀搜索算法优化支持向量机的数据分类方法 SSA-SVM分类算法【Matlab代码#61】
【可更换其他群智能算法,
获取资源请见文章第6节:资源获取】
1. 麻雀搜索算法(SSA)
麻雀搜索算法在各个博客网站上均可见,详细介绍此处略。
2. 支持向量机(SVM)
支持向量机(Support Vector Machine,SVM)是一种常用的监督学习算法,用于二分类和多分类问题。它的目标是找到一个超平面或者决策边界,将不同类别的样本点分开,并使得离决策边界最近的样本点的间隔最大化。
SVM的基本思想是将样本点映射到高维空间中,使得在该空间中可以通过一个超平面来分隔不同类别的样本点。对于线性可分的情况,SVM会找到一个最优的超平面,使得两个类别的样本点到该超平面的间隔最大化。对于线性不可分的情况,SVM采用一定的核函数将样本点映射到高维空间中,使得在高维空间中线性不可分的样本点变得线性可分。
SVM的训练过程是一个凸优化问题,目标是最小化模型的结构风险(结构风险最小化原则)。在优化过程中,SVM通过支持向量来确定超平面的位置,支持向量是离超平面最近的样本点。
SVM具有以下优点:
- 在高维空间中的处理能力强,可以处理高维特征空间中的复杂问题。
- 可以通过选择不同的核函数来适应不同类型的数据,比如高斯核函数、多项式核函数等。
- 目标函数是一个凸优化问题,全局最优解可得到保证。
- 由于支持向量的存在,SVM模型具有较好的鲁棒性。
3. SSA-SVM分类模型
本文中的SSA-SVM分类模型的主要步骤如下:
- 将数据样本随机划分,80%作为训练集,20%作为测试集;
- 初始化SSA-SVM分类器参数:种群数量,最大迭代次数,变量维数(此处为2,惩罚因子C和核参数sigma),变量上下限;
- 开始迭代,计算每只麻雀的适应度值,并更新麻雀的位置;
- 迭代结束,得到最优解,包括最优的惩罚因子C和核参数sigma;
- 采用最优的C和sigma参数构建SVM模型,并利用训练数据进行训练;
- 利用训练好的SVM分类模型对测试数据进行分类。
4. 部分代码展示
%% 计时开始 tic %% 清空环境变量 close all clear clc %% 数据提取 % 读取数据 % load 'dataset/breast-cancer-wisconsin.mat' %乳腺癌诊断公共数据集 % load 'dataset/carevaluation.mat' %汽车评估数据集 % load 'dataset/heartdata.mat' %心脏病数据集 % load 'dataset/ionosphere.mat' %“离子层”数据集 % load 'dataset/lymphography.mat' %淋巴造影数据集 % load 'dataset/Parliment1984.mat' %议会或国会的数据集 % load 'dataset/winedata.mat' %葡萄酒数据集 load 'dataset/iris.mat' %% 选定训练集和测试集 labels=Tdata(:,end); % 标签数据 attributesData=Tdata(:,1:end-1); %变量数据 [rows,colms]=size(attributesData); [trainIdx,~,testIdx]=dividerand(rows,0.8,0,0.2); %随机取80%作为训练数据,20%作为测试数据 train_data=attributesData(trainIdx,:); %训练数据 test_data=attributesData(testIdx,:); %测试数据 train_labels=labels(trainIdx); %训练数据的标签 test_labels=labels(testIdx); %测试数据的标签 data.train_labels=train_labels; data.train_data=train_data; data.test_labels=test_labels; data.test_data=test_data; %% 群智能算法参数设置 SearchAgents_no=30; % 种群数量 lb=0.01; % 变量取值范围下限 ub=100; % 变量取值范围上限 dim=2; % 变量维数 Max_iteration=50; % 最大迭代次数 %% 调用群智能算法进行寻优 [fMin,bestX,SSA_curve]=SSA(SearchAgents_no,Max_iteration,lb,ub,dim,data);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
5. 仿真结果展示
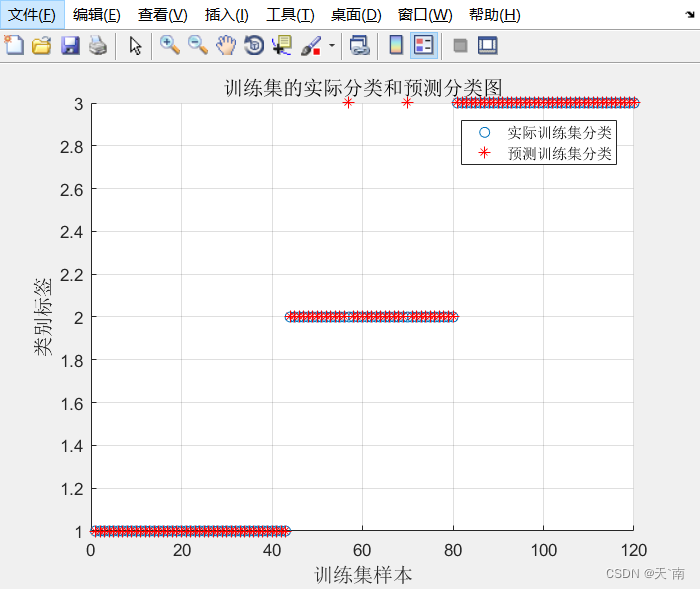
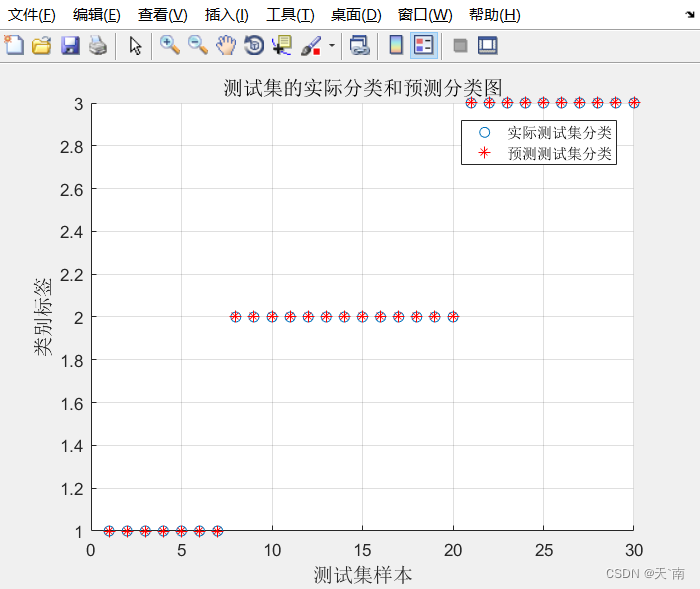
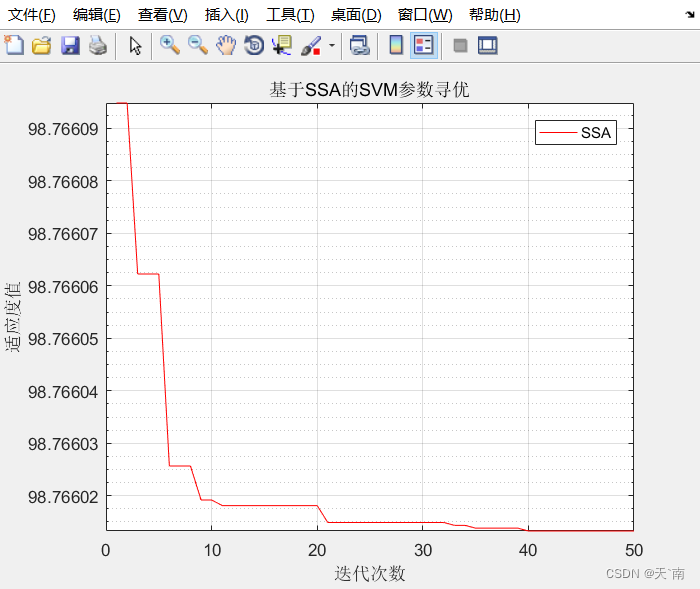
6. 资源获取
可更换其他群智能算法,可以获取完整代码资源。👇👇👇👀名片
-
相关阅读:
工厂车间安灯呼叫系统实现生产过程的可视化管理
Redis 6.0学习指南
Lambda表达式实现方式、标准格式、练习、省略模式、注意事项及和匿名内部类的区别
可用于高质量回测的 MetaTrader 历史数据导入及转换教程
国内大模型五虎
顺序表的实现(增删查改)
【微信小程序】选择宝——选择困难症的拯救者
Spring5学习笔记01--BeanFactory 与 ApplicationContext
TiDB Dashboard 慢查询页面
基于ssm的机场网上订票系统设计与实现-计算机毕业设计源码+LW文档
- 原文地址:https://blog.csdn.net/xiongyajun123/article/details/133716488
