-
大数据学习(1)-Hadoop
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博>主哦🤞
Hadoop是一个开源的分布式计算平台,用于处理大规模数据集。Hadoop的核心组件包括:
HDFS(Hadoop Distributed File System)
MapReduce和Yarn。
Hadoop的运行机制基于分布式计算的概念,即将大规模的计算任务分解为多个小任务,并在多台计算机上并行处理。Hadoop集群由多个节点组成,包括一个NameNode和若干个DataNode。NameNode负责管理文件系统的元数据,而DataNode负责存储实际的数据。
Hadoop的运行过程包括以下几个步骤:
- 数据准备:将待处理的数据上传到HDFS中,可以使用Flume、Sqoop等工具将数据从其他系统导入到HDFS。
- 编写MapReduce程序:使用Java语言编写MapReduce程序,将计算任务划分为Map阶段和Reduce阶段。
- 提交任务:将编写好的MapReduce程序提交到Yarn中,Yarn负责资源的分配和管理。
- 任务执行:Yarn将MapReduce任务分解为多个小任务,并在集群中的不同节点上并行执行。在Map阶段,数据被划分为若干个小块,并在不同节点上进行处理;在Reduce阶段,Map阶段的输出被收集和汇总,以生成最终的结果。
- 结果输出:处理完成后,结果将输出到HDFS中,可以使用Hive、HBase等工具进行结果查询和分析。
在运行过程中,Hadoop涉及到了多个技术栈,包括:
- HDFS:Hadoop分布式文件系统,用于存储大规模数据。
- MapReduce:Hadoop的核心计算模型,用于处理大规模数据集。
- Yarn:Hadoop的资源管理器,用于管理和分配集群中的计算资源。
- Hive:基于Hadoop的数据仓库工具,提供了类似于SQL的查询语言。
- HBase:基于Hadoop的分布式数据库,用于存储非结构化和半结构化数据。
- Flume:Hadoop的数据采集工具,用于将数据从不同的数据源导入到HDFS中。
- Sqoop:Hadoop的数据导入导出工具,用于在关系型数据库和Hadoop之间进行数据迁移。
Hdfs存储:
HDFS中每个数据节点可以存储的数据量取决于节点的硬盘大小。对于单个节点,其存储容量为磁盘容量减去配置文件(hdfs-site.xml)中的参数值dfs.datanode.du.reserved。对于一个集群,其总容量取决于所有DataNode节点的硬盘大小之和。但是需要注意的是,还需要考虑集群的备份数量。例如,如果备份数量为3,集群总容量为3TB,则实际可以存储的文件容量为1TB。
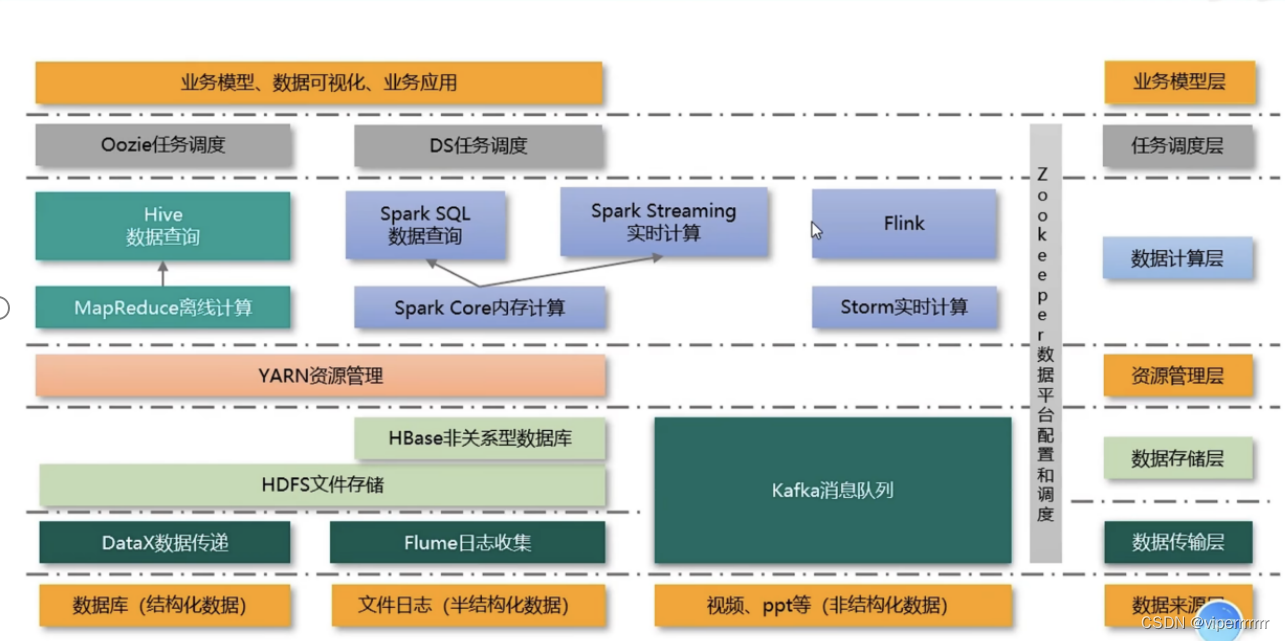
大数据技术栈非常多,但是并不需要全部都懂,了解即可,我也是刚刚开始学习不久,欢迎大家的批评指正。之后会持续更新大数据了!
-
相关阅读:
接口测试常用工具及测试方法(零基础篇)
浏览器——Microsoft Edge
python+vue+elementui医院急诊病房预约系统django
CTF逆向基础
蓝桥杯备战15.完全二叉树的权值
C++11之线程库(Thread、Mutex、atomic、lock_guard、同步)
短视频矩阵-同城霸屏-一站式管理1000+多平台短视频账号
第四章 二叉树
一款新的webshell管理工具
优雅编码之——传统项目中,使用openfeign替换掉项目中的httpclient
- 原文地址:https://blog.csdn.net/weixin_61006262/article/details/133699440