-
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf 文字提取如果pdf里文字是可以复制的是可以识别的,如果pdf里是纯图片类型的pdf是不能识别提取其中文字的
1、pdfplumber
安装: pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com- 1
- 2
- 3
代码:
import pdfplumber with pdfplumber.open(r"C:\Users\loong\Downloads\数字人研究报告.pdf") as pdf: num_pages = len(pdf.pages) print(num_pages) for page_num in range(num_pages): page = pdf.pages[page_num] text = page.extract_text() print(text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
原内容

识别结果:
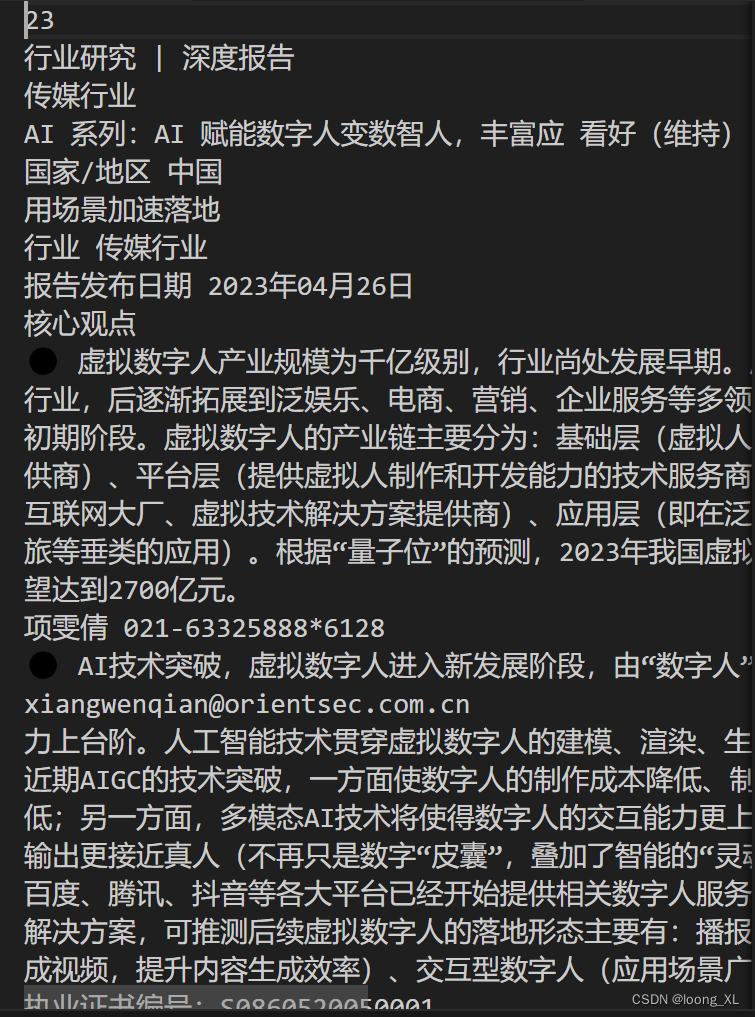
2、PyPDF2
安装: pip install PyPDF2- 1
- 2
- 3
代码:
import PyPDF2 from tqdm import tqdm pdftext = "" with open(r"C:\Users\loong\Desktop\****.pdf", "rb") as pdfFileObj: pdfReader = PyPDF2.PdfReader(pdfFileObj) for page in tqdm(pdfReader.pages): pdftext += page.extract_text() print(pdftext)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、PyMuPDF pdf2img
前面pdf如果文字实在读取不行,可以先转成图片,再ocr提取文字
1)pdfplumber pdf2img
with pdfplumber.open(r"C:\Users\loon***.pdf") as pdf: for i, page in enumerate(pdf.pages): im = page.to_image(resolution=150) im.save("./imgs1/page-{}.png".format(i+1), format="png")- 1
- 2
- 3
- 4
2)PyMuPDF pdf2img
pip install PyMuPDF- 1
pdf转图片代码(PyMuPDF现版本接口有变化):
参考:https://blog.csdn.net/weixin_63676550/article/details/130442949import datetime import os import fitz # fitz就是pip install PyMuPDF def pyMuPDF_fitz(pdfPath, imagePath): startTime_pdf2img = datetime.datetime.now() # 开始时间 print("imagePath=" + imagePath) pdfDoc = fitz.open(pdfPath) for pg in range(pdfDoc.page_count): page = pdfDoc[pg] rotate = int(0) # 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。 # 此处若是不做设置,默认图片大小为:792X612, dpi=96 zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224) zoom_y = 1.33333333 mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate) pix = page.get_pixmap(matrix=mat, alpha=False) if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在 os.makedirs(imagePath) # 若图片文件夹不存在就创建 pix.save(imagePath + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内 endTime_pdf2img = datetime.datetime.now() # 结束时间 print('pdf2img时间=', (endTime_pdf2img - startTime_pdf2img).seconds) if __name__ == "__main__": # 1、PDF地址 pdfPath = r"C:\Users\loong\Des***能.pdf" # 2、需要储存图片的目录 imagePath = './imgs' pyMuPDF_fitz(pdfPath, imagePath)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
-
相关阅读:
【Mac】破解死循环,成功安装 Homebrew、curl、wget,快速配置 zsh
C++ - 红黑树 介绍 和 实现
MySQL进阶查询
10kb的照片尺寸怎么弄?几个步骤轻松搞定!
RAW、RGB 、YUV三种图像格式理解
认识物联网
Npm——常用指令
基于threejs的商品VR展示平台的设计与实现思路
JS进阶——深入面向对象
《向量数据库指南》——完善产品拼图,GBASE南大通用发布向量数据库
- 原文地址:https://blog.csdn.net/weixin_42357472/article/details/133675091