-
C语言 - 数组
目录
我们原来要存放一个整数, 就会:
- int a = 1;
- int b = 2;
- int c = 3;
那么如果要存放1~10, 或者要存放1~100呢? 如果创建10或100个变量就不方便了, 于是就有了数组的概念.
什么是数组? 数组是一组相同类型元素的集合.
那么C语言的数组形式是什么呢, 我们一起来看.
1. 一维数组的创建和初始化
1.1 数组的创建
数组的创建方式:
- type_t arr_name [const_n];
- // type_t 是数组的元素类型
- // arr_name 是数组的数组名
- // const_n 是一个常量表达式, 用来指定数组的大小
数组创建的实例:
- int arr[10];
- char ch[5];
- double data1[20];
- double data2[15+5];
注: 数组创建,在C99标准之前,
[]中要给一个常量或者常量表达式才可以,不能使用变量。在C99之后,数组的大小可以是变量,这是为了支持变长数组。- //下面的代码只能在支持C99标准的编译器上编译
- int n = 10;
- scanf("%d", &n);
- int arr2[n];//这种数组是不能初始化
1.2 数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化).
数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
- //不完全初始化,剩余的元素默认初始化为0
- int arr[10] = { 1,2,3 };
- int arr1[10] = { 1,2,3,4,5,6,7,8,9,0 };
- int arr2[] = { 1,2,3 };
但是对于下面的代码要区分,内存中如何分配。
- char ch1[10] = { 'a', 'b', 'c' };
- //a b c 0 0 0 0 0 0 0
- char ch2[10] = "abc";
- //a b c \0 0 0 0 0 0 0
- char ch3[] = { 'a', 'b', 'c' };
- char ch4[] = "abc";
1.3 一维数组的使用
对于数组的使用我们之前介绍了一个操作符:
[],下标引用操作符。它其实就数组访问的操作符.- int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
- // 0 1 9
当我们去访问上面这个数组的时候, 需要知道它在内存中的情况.
这段代码对应的是在内存中的栈区找了一块连续的空间, 在里面放了1~10.

那么我们可以通过下标引用操作符+下标编号来访问数组中的元素.
printf("%d\n", arr[4]);如果要打印数组的每个元素:
- int main()
- {
- int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
- int i = 0;
- int sz = sizeof(arr) / sizeof(arr[0]);
- //顺序打印
- for (i = 0; i < sz; i++)
- {
- printf("%d ", arr[i]);
- }
- //逆序打印
- for (i = sz - 1; i >= 0; i--)
- {
- printf("%d ", arr[i]);
- }
- return 0;
- }
总结:
1. 数组是使用下标来访问的,下标是从0开始
2. 数组的大小可以通过计算得到。1.4 一维数组在内存中的存储
在上面的代码中加入:
- for (i = 0; i < sz; i++)
- {
- printf("&arr[%d] = %p\n", i, &arr[i]);
- }
可以看到数组的,每个元素的地址:

观察输出的结果,可以知道,随着数组下标的增长,元素的地址,也在有规律的递增.
由此我们得出: 数组在内存中是连续存放的.
那么我们同样也是可以通过调试在内存窗口中看到数组arr在内存中的分布情况.

2. 二维数组的创建和初始化
二维数组相较于一维数组能够存放更多的数据. 它存在的原因就是因为相同的数据是可能会出现很多组. 像这种多组整数需要存储的话就可以考虑二维数组.
2.1 二维数组的创建
- int arr[3][4]; // 第一个[]表示行, 第二个[]表示列. 3行4列.
- char arr[3][5];
- double arr[2][4];
可以看到在数组名后有两个
[], 对于第一行它表示的是三行四列的元素, 就像一个表格一样.
我们知道一维数组是一行, 而二维数组是有多行. 其实这就是一个概念.比如说要存放下面这几组数据:
1 2 3 4
2 3 4 5
3 4 5 6那么我们就可以创建如上文第一行代码的那样一个数组.
2.2 二维数组的初始化
- int arr1[3][4] = {1,2,3,4,2,3,4,5,3,4,5,6};
- int arr2[3][4] = { {1,2}, {3, 4}, {5, 6}};
- int arr3[][4] = { 1,2,3,4,5,6};//二维数组如果有初始化,行可以省略,列不能省略

可以看到, arr1第一行为1234, 第二行为2345, 第三行为3456. 因为我们前面已经限定了一行能放四个元素, 所以当第一行放了四个元素之后紧接着后面的初始化内容又找了四个给第二行, 再找四个给到第三行.
所以能看到如上图所示的现象.
那么如果初始化的数字不够数的时候, 会在后面初始化成0, 也如上图arr2和arr3所示.2.3 二维数组的使用

二维数组的使用也是通过下标的方式.
- #include
- int main()
- {
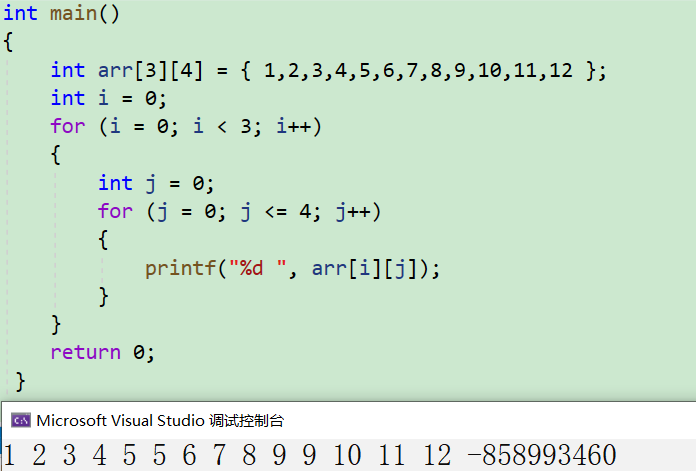
- int arr[3][4] = { 1,2,3,4,2,3,4,5,3,4,5,6 };
- int i = 0;
- for (i = 0; i < 3; i++)
- {
- int j = 0;
- for (j = 0; j < 4; j++)
- {
- printf("%d ", arr[i][j]);
- }
- printf("\n");
- }
- return 0;
- }
运行结果:

2.4 二维数组在内存中的存储
前面在我们假想中的二维数组是多行多列的一个存在, 但是实际上在内存中并不是使用行列这种样子的存储方式, 而是连续的存储.
我们来进行验证, 打印二维数组每个元素的地址:
- #include
- int main()
- {
- int arr[3][4] = { 1,2,3,4,2,3,4,5,3,4,5,6 };
- int i = 0;
- for (i = 0; i < 3; i++)
- {
- int j = 0;
- for (j = 0; j < 4; j++)
- {
- printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
- }
- }
- return 0;
- }
输出结果:

通过地址的变化可以观察出: 二维数组在内存中也是连续存放的.
于是, 我们可以进一步这样理解二维数组.
int arr[3][4];
理解为从第一个元素开始向后的连续12个空间, 看成是一个连续的一维数组, 有12个元素.
其实最终, 该代码与
int arr2[12];
在内存中的布局是一样的.可以把二维数组理解为: 一维数组的数组.
3. 数组越界
数组的下标是有范围限制的。
数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的。
所以程序员写代码时,最好自己做越界的检查。

二维数组的行和列也可能存在越界。
4. 数组作为函数参数
往往我们在写代码的时候,会将数组作为参数传个函数,比如: 我要实现一个冒泡排序函数将一个整形数组排序.
冒泡排序的核心思想: 两个相邻的元素进行比较
代码思路:

4.1 冒泡排序函数的设计
4.1.1 关于冒泡排序函数的错误设计
- int main()
- {
- //数组
- //把数组的数据排成升序
- int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
- //0 1 2 3 4 5 6 7 8 9
- int sz = sizeof(arr) / sizeof(arr[0]);
- //冒泡排序的算法,对数组进行排序
- bubble_sort(arr);
- int i = 0;
- for (i = 0; i < sz; i++)
- {
- printf("%d ", arr[i]);
- }
- return 0;
- }
- void bubble_sort(int arr[])
- {
- //趟数
- int sz = sizeof(arr) / sizeof(arr[0]);
- int i = 0;
- for (i = 0; i < sz - 1; i++)
- {
- //一趟冒泡排序
- int j = 0;
- for (j = 0; j < sz - 1 - i; j++)
- {
- if (arr[j] > arr[j + 1])
- {
- //交换
- int tmp = arr[j];
- arr[j] = arr[j + 1];
- arr[j + 1] = tmp;
- }
- }
- }
- }
执行上述代码之后, 会出问题, 并不能正确的将数据进行排序.
我们进行调试:
在调试到bubble_sort()中发现sz变成了1, 但是我们期望是10, 此时往下1-1=0, 并没有进行任何的对数据排序就退出了这个函数, 所以当整个程序执行完会发现并没有将数据进行排序就输出.

这是函数程序的编写中非常常见的错误.
4.1.2 关于冒泡排序函数的正确设计
- //形参是数组的形式
- void bubble_sort(int arr[],int sz)
- {
- //趟数
- int i = 0;
- for (i = 0; i < sz - 1; i++)
- {
- //一趟冒泡排序
- int j = 0;
- for (j = 0; j < sz - 1 - i; j++)
- {
- if (arr[j] > arr[j + 1])
- {
- //交换
- int tmp = arr[j];
- arr[j] = arr[j + 1];
- arr[j + 1] = tmp;
- }
- }
- }
- }
- int main()
- {
- //数组
- //把数组的数据排成升序
- int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
- //0 1 2 3 4 5 6 7 8 9
- int sz = sizeof(arr) / sizeof(arr[0]);
- //冒泡排序的算法,对数组进行排序
- bubble_sort(arr, sz);
- int i = 0;
- for (i = 0; i < sz; i++)
- {
- printf("%d ", arr[i]);
- }
- return 0;
- }
- //形参是指针的形式
- void bubble_sort(int* arr,int sz)
- {
- //趟数
- int i = 0;
- for (i = 0; i < sz-1; i++)
- {
- //一趟冒泡排序
- int j = 0;
- for (j=0; j
- {
- if (arr[j] > arr[j + 1])
- {
- //交换
- int tmp = arr[j];
- arr[j] = arr[j + 1];
- arr[j + 1] = tmp;
- }
- }
- }
- }
4.2 数组名是什么?
前面提到, 数组名是数组首元素的地址, 这个说法虽然对, 但是其实并不完全对, 有两个例外.
1.
sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节2.
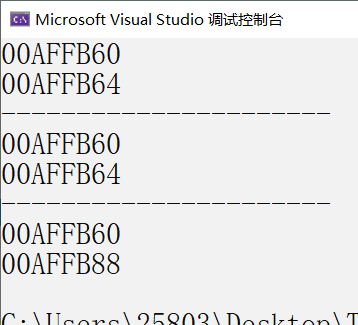
&数组名,这里的数组名表示整个数组,取出的是整个数组的地址- int main()
- {
- int arr[10] = {0};
- printf("%p\n", arr);//arr就是首元素的地址
- printf("%p\n", arr+1);
- printf("----------------------\n");
- printf("%p\n", &arr[0]);//首元素的地址
- printf("%p\n", &arr[0]+1);
- printf("----------------------\n");
- printf("%p\n", &arr);//数组 的地址
- printf("%p\n", &arr+1);
- //int n = sizeof(arr);//40
- //printf("%d\n", n);
- return 0;
- }
执行结果:
对于二维数组的数组名
- #include
- int main()
- {
- int arr[3][4] = {0};
- printf("%d\n", sizeof(arr) / sizeof(arr[0]));//计算行
- printf("%d\n", sizeof(arr[0]) / sizeof(arr[0][0]));//计算列
- int sz = sizeof(arr);
- printf("%d\n", sz); //48
- printf("%p\n", arr);//二维数组的数组名也表示数组首元素的地址(第一行的地址)
- printf("%p\n", arr+1);//第二行
- return 0;
- }
-
相关阅读:
连接工具和idea能查询出数据库数据,项目中查不到数据库数据:解决办法
wgcloud怎么保证数据的安全性
部署LAMP平台
一个函数如何实现return好几个返回值(借鉴学习前辈的文章,链接放文章里了)
【EI会议征稿】第三届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2024)
22、接口与抽象类、匿名类的介绍
手把手教你如何玩转Git
MatLab命令行常用命令记录
spring boot入门与理解MVC三层架构
MU editor IDE编辑器 二次开发记录与踩坑
- 原文地址:https://blog.csdn.net/YeZh1Yong_Cr/article/details/133691415
