-
CUDA学习笔记2——CUDA程序基本框架
GPU工作模式:
- TCC (Tesla Compute Cluster) :专门为计算任务优化,提供较低的延迟和更直接的GPU内存访问。此模式下,GPU不能用作显示设备。
- WDDM (Windows Display Driver Model) :Windows默认显示驱动模式,用于日常的图形任务。也可以处理计算任务,但可能不如TCC模式高效。
CUDA向量运算
CUDA程序的基本框架为:
头文件包含
常量定义/宏定义
C++ 自定义函数和CUDA核函数声明
int main(void)
{
分配主机与设备内存
初始化主机中的数据
将部分数据从主机拷贝至设备
调用核函数在设备中进行计算
将部分数据从设备拷贝至主机
释放主机与设备内存
}
c++ 自定义函数与CUDA核函数定义例:
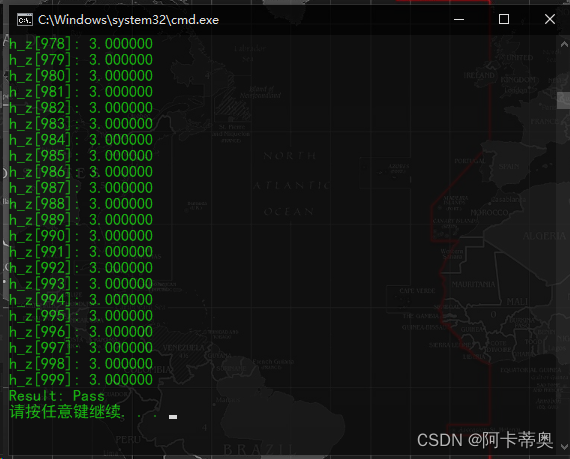
#include#include "cuda_runtime.h" #include #include //cuda内存 x[] + y[] = Z[] //1.分配内存 2.内存拷贝 3.执行核函数 4.内存拷贝 __global__ void vecAdd(const double *x, const double *y,double *z, int count) { const int index = blockDim.x * blockIdx.x + threadIdx.x;//使用索引让每个线程找到其要处理的数据 //t00 t01 t02 //t10 t11 t12 [当前block之前有多少线程] +[当前线程中的排序] //t20 t21 t22 t21 (7) = blockDim(3)*blockIdx(2) + threadIdx(1) if (index < count) { z[index] = x[index] + y[index]; } } void vecAdd_cpu(const double *x, const double *y, double *z, int count) { for (int i = 0; i < count; i++) { z[i] = x[i] + y[i]; } } int main() { const int N = 1000; const int M = sizeof(double) * N; //cup内存分配 double *h_x = (double*)malloc(M); double *h_y = (double*)malloc(M); double *h_z = (double*)malloc(M); double *result_cpu = (double*)malloc(M); //GPU内存分配 double *d_x, *d_y, *d_z; cudaMalloc((void**)&d_x, M); cudaMalloc((void**)&d_y, M); cudaMalloc((void**)&d_z, M); for (int i=0;i<N;++i) { h_x[i] = 1; h_y[i] = 2; } //cpu数据传输到GPU cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice); cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice); //调用核函数 const int block_size = 128; const int gride_size = (N + block_size - 1) / block_size; vecAdd <<< gride_size, block_size>>> (d_x,d_y,d_z,N); //GPU数据传输到cpu cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost); //cpu计算 vecAdd_cpu(h_x, h_y, result_cpu, N); bool error = false; for (int i = 0; i < N; i++) { if (fabs(result_cpu[i]-h_z[i])>(1.0e-10)) { error = true; } printf("h_z[%d]: %f \n", i, h_z[i]); } printf("Result: %s\n", error ? "Errors" : "Pass"); free(h_x); free(h_y); free(h_z); cudaFree(d_x); cudaFree(d_y); cudaFree(d_z); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
cudaError_t cudaMalloc(void **address, size_t size); CUDA中设备内存动态分配
- 第一个参数address 为待分配设备内存的指针,由于内存(地址)本身就是指针,因此待分配内存的指针即为指针的指针。
- 第二个参数size 为待分配内存的字节数。
- 返回值为错误代号,成功为cudaSuccess,失败为错误代号。
cudaError_t cudaFree(void* address) CUDA中释放内存
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, size_t count, enum cudaMemcpyKind kind); CUDA中主机与设备之间数据传递。cuda矩阵运算 例:
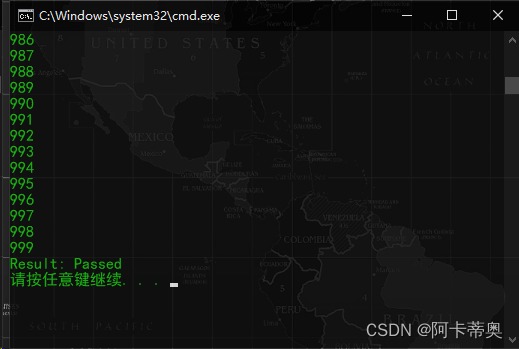
#include#include "cuda_runtime.h" #include #include #include #define BLOCK_SIZE 16 //cuda矩阵运算 a[][] * b[][] = c[][] //1.分配内存 2.内存拷贝 3.执行核函数 4.内存拷贝 __global__ void gpu_matrix_mult(int *a, int *b, int *c, const int size) { int y = blockDim.y *blockIdx.y + threadIdx.y; int x = blockDim.x*blockIdx.x + threadIdx.x; int tmp = 0; if (x<size && y<size) { for (int step = 0; step < size; step++) { tmp += a[y*size + step] * b[step*size + x]; } c[y*size + x] = tmp; } } void cpu_matrix_mult(int *a, int *b, int *c, const int size) { for (int y = 0; y < size; y++) { for (int x = 0; x < size; x++) { int tmp = 0; for (int step = 0; step < size; step++) { tmp += a[y*size + step] * b[step * size + x]; } c[y * size + x] = tmp; } } } int main() { int matrix_size = 1000; int memsize = sizeof(int) * matrix_size * matrix_size; //cup上分配内存 int *h_a, *h_b, *h_c, *h_cc; cudaMallocHost((void**)&h_a, memsize); cudaMallocHost((void**)&h_b, memsize); cudaMallocHost((void**)&h_c, memsize); cudaMallocHost((void**)&h_cc, memsize); for (int y = 0; y < matrix_size; y++) { for (int x = 0; x < matrix_size; x++) { h_a[y*matrix_size + x] = rand() % 1024; h_b[y*matrix_size + x] = rand() % 1024; } } //GPU上分配内存 int *d_a, *d_b, *d_c; cudaMalloc((void**)&d_a, memsize); cudaMalloc((void**)&d_b, memsize); cudaMalloc((void**)&d_c, memsize); //将cpu数据拷贝到GPU cudaMemcpy(d_a, h_a, memsize, cudaMemcpyHostToDevice); cudaMemcpy(d_b, h_b, memsize, cudaMemcpyHostToDevice); unsigned int grid_rows = (matrix_size + BLOCK_SIZE - 1) / BLOCK_SIZE; unsigned int grid_cols = (matrix_size + BLOCK_SIZE - 1) / BLOCK_SIZE; dim3 dimGrid(grid_cols, grid_rows); //gpu warp 32个线程共享一个物理端 因此尽量为32的整数倍 dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);// x*y*z<=1024 z未定义 默认为1 gpu_matrix_mult << <dimGrid, dimBlock >> > (d_a, d_b, d_c, matrix_size); cudaMemcpy(h_c, d_c, memsize, cudaMemcpyDeviceToHost); cpu_matrix_mult(h_a, h_b, h_cc, matrix_size); bool errors = false; for (int y = 0; y < matrix_size; y++) { printf("%d \n", y); for (int x = 0; x < matrix_size; x++) { if (fabs(h_cc[y*matrix_size + x] - h_c[y*matrix_size + x]) >(1.0e-10)) { errors = true; } } } printf("Result: %s\n", errors ? "Errors" : "Passed"); cudaFreeHost(h_a); cudaFreeHost(h_b); cudaFreeHost(h_c); cudaFreeHost(h_cc); cudaFree(d_a); cudaFree(d_b); cudaFree(d_c); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
-
相关阅读:
输电线路故障诊断(利用随机森林方法实现二分类和多分类)
OneNote 教程,如何在 OneNote 中做笔记?
【笔记】期末的jsp复习之数据库
Linux用户空间与内核空间(理解高端内存)
【学习记录】tensorflow图像数据增强
设计模式 - 单例模式理解及相关问题解决方法
揭秘一线大厂Redis面试高频考点(3万字长文、吐血整理)
【Numpy总结】第七节:Numpy常用的函数(汇总所有函数,收藏这一篇就OK啦~)
【C++】模板初阶 -- 详解
tcp网络编程——2
- 原文地址:https://blog.csdn.net/akadiao/article/details/133674775
