-
Python爬取小说(requests和BeautifulSoup)
1.用requests和BeautifulSoup爬取起点中文网小说(https://www.qidian.com/free/all/)
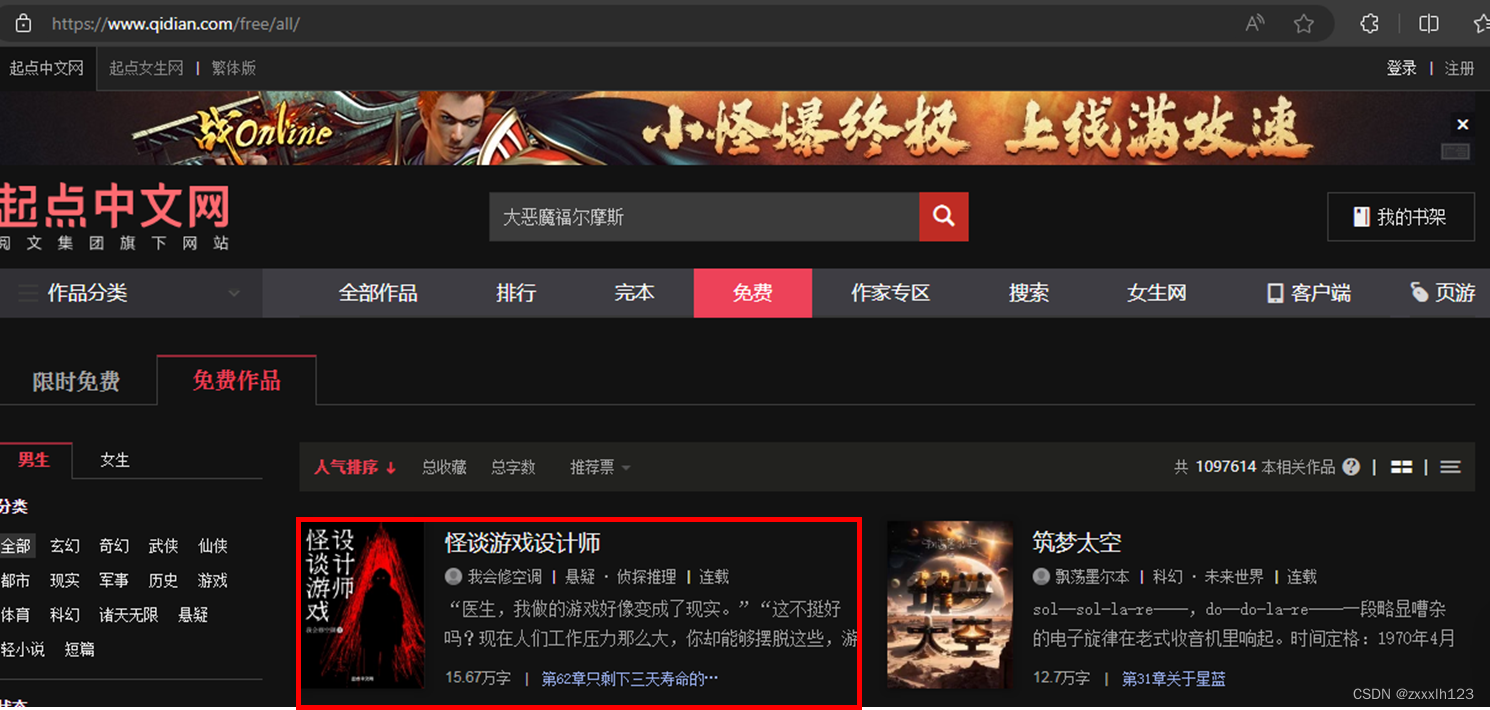
2.选择一篇小说(https://www.qidian.com/book/1037297523/)

3.查看小说的卷章和每章对应的章节
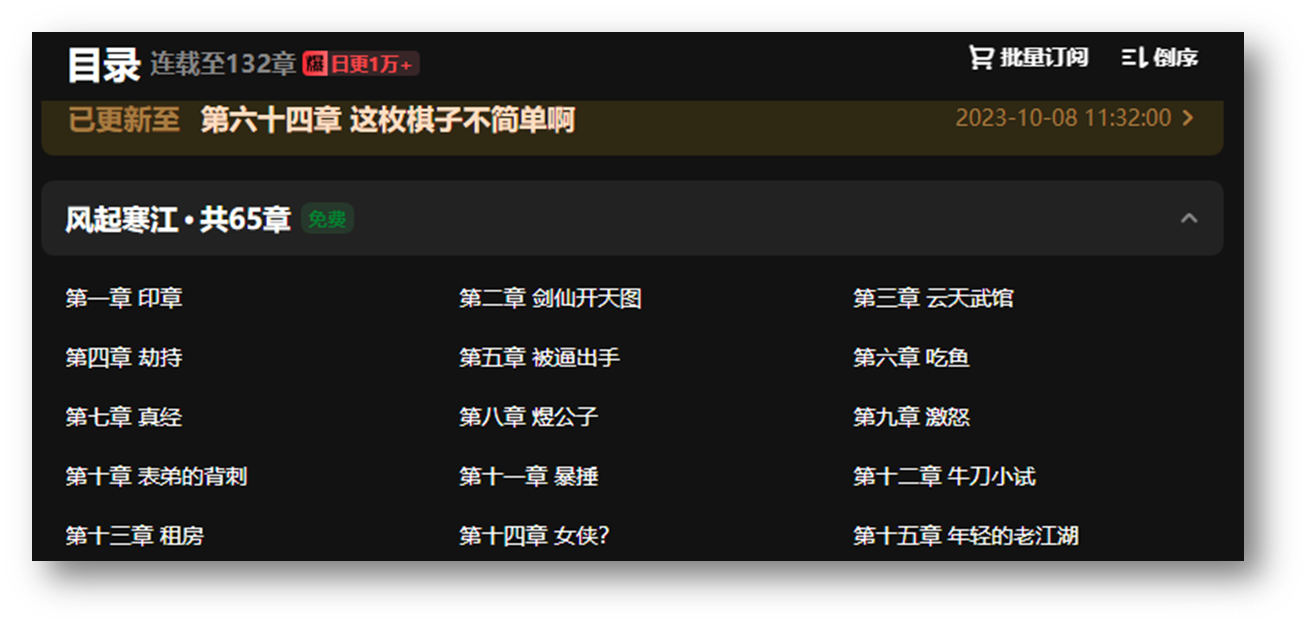
4.Chrome浏览器,使用F12,打开开发者模式,查看章节对应代码细节

5.查看卷章结构,并创建文件夹
#卷章结构 volums_names = [a.text.strip() for a in soup.find_all('h3', class_='volume-name')]- 1
- 2
- 3

#创建文件夹存卷章 def create_folders(base_path, folder_names): for folder_name in folder_names: try: # 使用os.makedirs()创建文件夹,如果它不存在 older_path = os.path.join(base_path, folder_name) os.makedirs(folder_name) print("文件夹 {}'创建成功!".format(folder_name)) except OSError as e: print("创建文件夹 {}失败!!!".format(folder_name))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

6.章节结构
chapter_names = [a.text.strip() for a in soup.find_all('a', class_='chapter-name')]- 1
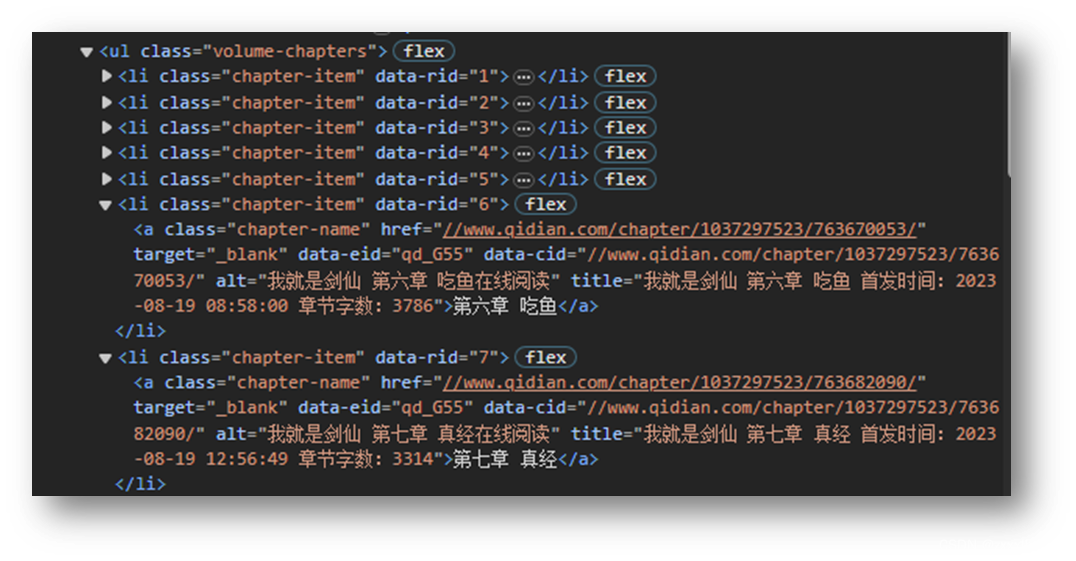

7.章节内容所在页面URL,缺少https:
data_cids = [a['data-cid'] for a in soup.find_all('a', class_='chapter-name')]- 1

8.提取章节内容
def getchacontents(chapter_id,headers): response = requests.get('https:' + chapter_id, headers = headers) pattern = r'(.*?)
' matches = re.findall(pattern, response.text, re.DOTALL) result = '\n'.join(matches)# 使用换行符拼接文本 return result- 1
- 2
- 3
- 4
- 5
- 6
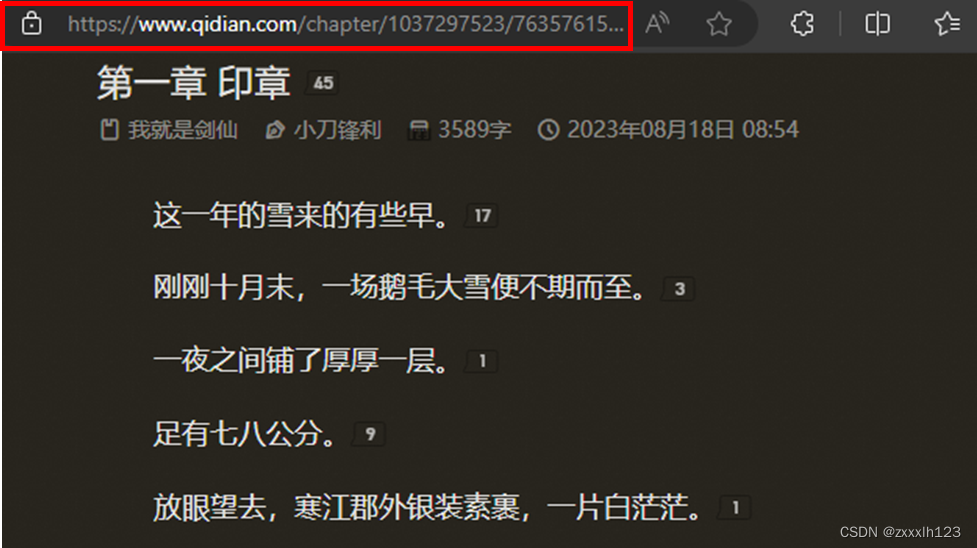
9.获取章节内容写入txt文件,并将文件存入对应的卷章文件夹
#将章节内容写入文件,存入对应的文件夹 def save2file(filepath, filename , content): filename = filename.replace(“/”,“-”)#文件名称不可出现- try: if not os.path.exists(filepath): os.makedirs(filepath) #文件存储地址 file_path = os.path.join(filepath, filename + '.txt') #爬取内容写入文件 with open(file_path,'a',encoding ='utf-8') as f: f.write(content +'\n') f.close() print('{}写入成功'.format(filename)) except Exception as e: print('{}写入失败!!!'.format(filename))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

10.整体代码
import requests import json import os import re from bs4 import BeautifulSoup import random #提取章节内容 def getchacontents(chapter_id,headers): response = requests.get('https:' + chapter_id, headers = headers) pattern = r'(.*?)
' matches = re.findall(pattern, response.text, re.DOTALL) result = '\n'.join(matches)# 使用换行符拼接文本 return result #创建文件夹存卷章 def create_folders(base_path, folder_names): for folder_name in folder_names: try: # 使用os.makedirs()创建文件夹,如果它不存在 older_path = os.path.join(base_path, folder_name) os.makedirs(folder_name) print("文件夹 {}'创建成功!".format(folder_name)) except OSError as e: print("创建文件夹 {}失败!!!".format(folder_name)) #将章节内容写入文件,存入对应的文件夹 def save2file(filepath, filename , content): filename = filename.replace("/","-") try: if not os.path.exists(filepath): os.makedirs(filepath) #user_home = os.path.expanduser("~") file_path = os.path.join(filepath, filename + '.txt') #file_path = os.path.join(filepath,filename +'.txt') with open(file_path,'a',encoding ='utf-8') as f: f.write(content +'\n') f.close() print('{}写入成功'.format(filename)) except Exception as e: print('{}写入失败!!!'.format(filename)) #防止被禁,随机返回list_中某个User_Agent设置值 def get_User_Agent(): list_ = ['Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',\ 'Mozilla/5.0 (Windows NT 10.0;Win64;x64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',\ 'Mozilla/5.0 (Windows NT 6.3;Win64;x64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',\ 'Mozilla/5.0 (Windows NT 6.2;Win64;x64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',\ 'Mozilla/5.0 (Windows NT 6.1;Win64;x64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',\ 'Mozilla/5.0 (Windows NT 6.3;WOW64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/401.0.2225.0 Safari/537.36',\ 'Mozilla/5.0 (Windows NT 6.2;WOW64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/401.0.2225.0 Safari/537.36',\ 'Mozilla/5.0 (Windows NT 6.1;WOW64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/401.0.2225.0 Safari/537.36'] return list_[random.randint(0,len(list_)-1] def main(): headers = {'User-Agent':get_User_Agent()} response = requests.get('https://www.qidian.com/book/1037297523/',headers = headers) # 使用BeautifulSoup解析HTML soup = BeautifulSoup(response.text, 'html.parser') # 查找所有章节名称和章节对应网页 volums_names = [a.text.strip() for a in soup.find_all('h3', class_='volume-name')] chapter_names = [a.text.strip() for a in soup.find_all('a', class_='chapter-name')] data_cids = [a['data-cid'] for a in soup.find_all('a', class_='chapter-name')] # 指定要创建文件夹的基本路径 base_path = '/Users/xinxin/Desktop' create_folders(base_path ,volums_names) i = 0; j = 0;m = 0 for chapter_name in chapter_names: result = getchacontents(data_cids[chapter_names.index(chapter_name)], headers) save2file(base_path + '/' +volums_names[j] , chapter_name, result) i += 1;m += 1 print(' -----写入{}已完成{}/{}----'.format(volums_names[j],m,volums_names[j][6:8])) if i == volums_names[0][6:8]: j += 1;m = 0 elif i == volums_names[0][6:8] + volums_names[0][6:8]: j += 1;m =1 print("小说爬取完毕") if __name__=='__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85

-
相关阅读:
C++后端开发(2.2.3)——POSIXAPI解析
CTC 技术介绍概述——啃论文系列
关于el-upload看这一篇就够了
useLayoutEffect和useEffect的区别
java微博 8 CSS
NLP涉及技术原理和应用简单讲解【一】:paddle(梯度裁剪、ONNX协议、动态图转静态图、推理部署)
自动化测试岗花20K招人,到最后居然没一个合适的,招两个应届生都比他们强吧
P1160 队列安排题解【STL双向链表】
阅读llama源码笔记_1
Maven项目创建步骤详解_smart tomcat使用介绍_Servlet项目初识(Servlet_1)
- 原文地址:https://blog.csdn.net/zxxxlh123/article/details/133682981
