-
机器人中的数值优化(二十一)—— 伴随灵敏度分析、线性方程组求解器的分类和特点、优化软件
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,下半部分介绍带约束的优化,中间会穿插一些路径规划方面的应用实例
三十三、伴随灵敏度分析
伴随灵敏度分析可以避免冗余信息的计算,在下面的例子中,我们想要求解Ax=b1、Ax=b2 … Ax=bm等一系列方程组,第一种求解思路是将A矩阵进行LU分解, A = L U A=LU A=LU,求逆后可得到 A − 1 = U − 1 L − 1 A^{-1}=U^{-1}L^{-1} A−1=U−1L−1,然后依次将b1~bm代入下式即可得到这一系列方程组的解
x i = U − 1 L − 1 b i x_i=U^{-1}L^{-1}b_i xi=U−1L−1bi

但如果我们事先知道需要使用那些数据,那么我们能不能仅把需要使用的变量求出来?比如我们的目标是求每个xi的平均值ai,比如所有x1的平均值a1,那么我们是不是不需要求出每个xi的具体值,而仅仅需要他们的平均值ai。
a i = c T x i = c T A − 1 b i = b i T A − T c a_{i}=c^{T}x_{i}=c^{T}A^{-1}b_{i}=b_{i}^{T}A^{-T}c ai=cTxi=cTA−1bi=biTA−Tc
之前需要先算 A − 1 b i A^{-1}b_{i} A−1bi 部分,再算 c T A − 1 b i c^TA^{-1}b_i cTA−1bi,现在可以先算 A − T c A^{-T}c A−Tc,再算 b i T A − T c b_i^TA^{-T}c biTA−Tc,我们不需要对每个bi求一个线性方程组了,仅需要求一个方程组 q ≡ A − T c q\equiv A^{-T}c q≡A−Tc,求出 q q q之后,再与bi做一个点积即可, a i = b i T q a_i=b_i^Tq ai=biTq

伴随灵敏度分析的思想是在计算矩阵相乘的时候考虑那个先乘,那个后乘。线性方程组有一个伴随线性方程组,伴随灵敏度分析允许优化一小部分设计参数,而不是全部参数。
假设x是一个线性方程组的解,它的维度很大,它是一个完备的参数,从x可以获得所有我们想要的信息,但我们不能直接处理这么大维度的优化,我们需要设一组设计参数 p = ( p 1 , p 2 , . . . , p M ) \mathbf{p}=(p_{1},p_{2},...,p_{M}) p=(p1,p2,...,pM),我们要算的是一些目标函数 g ( p , x ) g(\mathbf{p},\mathbf{x}) g(p,x)关于参数 p 1 , p 2 , … , p M p_{1},p_{2},\ldots,p_{M} p1,p2,…,pM的梯度
d g d p j = ∂ g ∂ p j + ∑ i = 1 N ∂ g ∂ x i ∂ x i ∂ p j d g d p = g p + g x x p \begin{aligned}\frac{dg}{dp_j}&=\frac{\partial g}{\partial p_j}+\sum_{i=1}^N\frac{\partial g}{\partial x_i}\frac{\partial x_i}{\partial p_j}\\\\\frac{dg}{d\mathbf{p}}&=g_\mathbf{p}+g_\mathbf{x}\mathbf{x_p}\end{aligned} dpjdgdpdg=∂pj∂g+i=1∑N∂xi∂g∂pj∂xi=gp+gxxp

一般认为 ∂ g ∂ p j 和 ∂ g ∂ x i \frac{\partial g}{\partial p_j}和\frac{\partial g}{\partial x_i} ∂pj∂g和∂xi∂g是容易获得的, ∂ x i ∂ p j \frac{\partial x_{i}}{\partial p_{j}} ∂pj∂xi是不知道的
A p j x + A x p j = b p j ⇒ x p j = A − 1 [ b p j − A p j x ] A_{p_j}\mathbf{x}+A\mathbf{x}_{p_j}=b_{p_j}\quad\Rightarrow\quad\mathbf{x}_{p_j}=A^{-1}[b_{p_j}-A_{p_j}\mathbf{x}] Apjx+Axpj=bpj⇒xpj=A−1[bpj−Apjx]


我们使用矩阵相乘交换顺序的思想,把解m次 N 2 N^2 N2复杂度的方程组,转换为解一次就可以了

应用示例一:
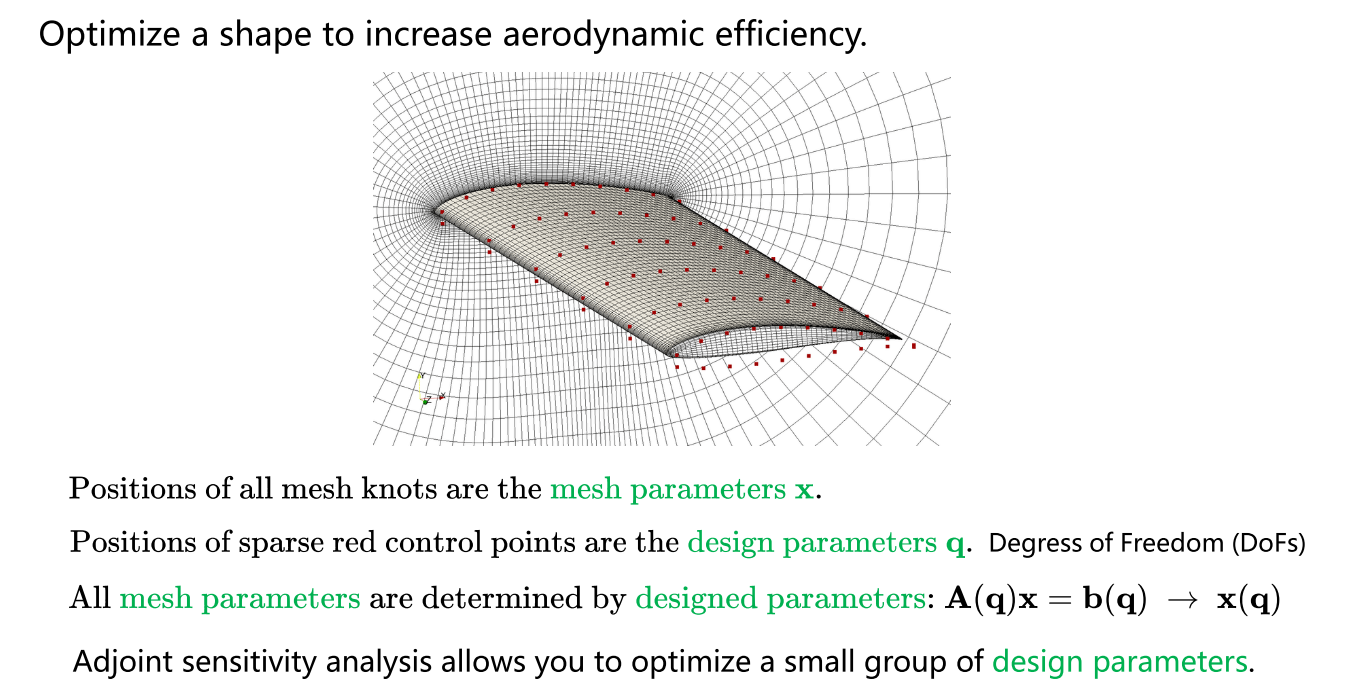
应用示例二:
当路径上选取的优化点变密集后,安全性会更好,那么我们能不能,不选取那么多的优化点,而同样使其有较好的安全性
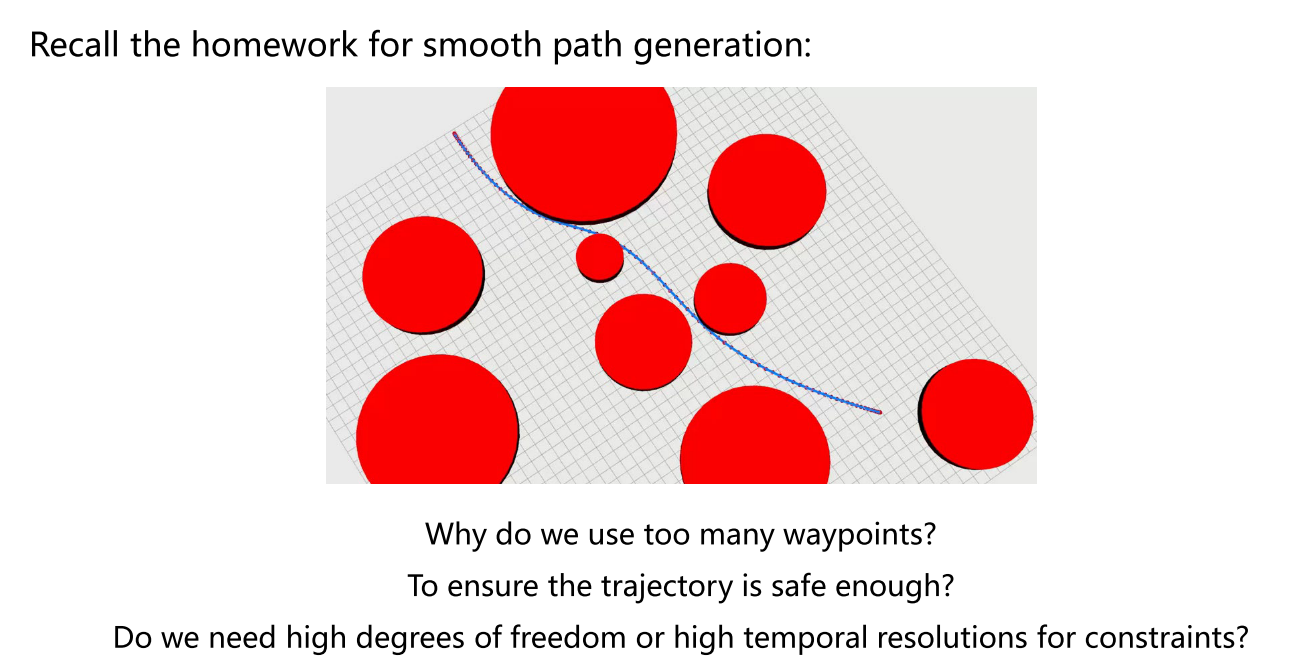
对于任意阶样条,我们可以解耦线段的数目和约束的数目。所有的路径点和持续时间都是我们轨迹的设计参数(决策变量)。样条系数是由路点确定的线性方程组的解。
A ( T ) c ( p , T ) = b ( p ) \mathbf{A(T)c(p,T)=b(p)} A(T)c(p,T)=b(p)
A和b构成了样条系数的线性方程组。这很自然地符合伴随敏感性分析的模型。

三十四、线性方程组求解器的分类和特点

线性方程组求解器可分为两大类或三小类,两大类即直接求解和迭代求解,直接求解可以得到Ax=b的精确解,迭代求解随着迭代次数的增多,所得到的近似解与精确解的误差也逐渐减小。三小类是因为有的求解器会利用矩阵的稀疏结构,而有的求解器不利用,因此,直接法又分为稠密法和稀疏直接法。
(1)稠密法
具有简单数据结构,不需要索引数据结构等特殊的数据结构,采用矩阵的直接表示,主要是O(N3)分解算法
(2)稀疏直接法
当矩阵中有很多0元素时,我们可以仅储存非0元素的位置和具体的值,使其占较少的内存。
因子分解成本取决于问题结构(1D低成本;2D可接受成本;3D高成本;不容易给出一般规则,NP难以排序以获得最佳稀疏性)
(3)迭代法
迭代求取近似解,仅需要知道 y = A x ( m a y b e y = A T x ) y=Ax\mathrm{~(maybe~}y=A^Tx) y=Ax (maybe y=ATx),良好的收敛性取决于预条件。

–
当我们求解Ax=b时,如果是稠密的矩阵,尽可能的根据矩阵的对称性、半正定性、带状结构等特点,以此来挑选不同的稠密求解器,比如使用LAPACK/ScaLAPACK库,或者Eigen库

若,我们知道矩阵的非零元素比零元素少很多,可以选用稀疏直接法中的求解器,看看能不能提前把矩阵预分解

如果问题比较大,如 1 0 5 10^5 105,此时采用稠密法会有问题,可以用CG方法处理正定对称矩阵,还有一系列迭代法可以处理对称不定或非对称的矩阵。

因式分解有很多种方法,比如
L U , L L T / L L H , L D L T / L D L H , Q R , L Q , Q R Z , generalized QR and RQ \begin{aligned}LU,LL^T /LL^H,LDL^T/LDL^H,QR,LQ,QRZ,\end{aligned}\text{generalized QR and RQ} LU,LLT/LLH,LDLT/LDLH,QR,LQ,QRZ,generalized QR and RQ
除了因式分解,还有对称/Hermitian和非对称特征值、奇异值分解、广义特征值与奇异值分解

LU分解其实就是高斯消元法,把一个矩阵进行高斯消元,进行一些行变换
A = P L U A=PLU A=PLU

稀疏LU分解法不仅需要做行变换,还需要做列变换。

Cholesky分解:

稀疏Cholesky分解:

LDL分解:

稀疏矩阵:


稀疏矩阵分解:

稀疏排序会对虚实化的稀疏性产生巨大的影响:

选择产生最小二乘分解的排序的一般问题是困难的,但是,几个简单的启发式方法是非常有效的。例如嵌套排序方法,可以起作用。


迭代法:
三十五、优化软件
1、swMATH
里面包含优化、线性代数、大规模矩阵运算等丰富的资源
链接:https://zbmath.org/software/

2、gamsworld
gamsworld收录了很多的工具,在这里可以找到锥规划等性能测评的手段
链接:https://github.com/GAMS-dev/gamsworld
3、DECISION TREE FOR OPTIMIZATION SOFTWARE
可以根据优化问题的结构,查找某个问题有哪些现有的方案
链接:http://plato.asu.edu/guide.html
4、Mathematical Software
里面包含优化、非线性求解器等丰富的资源
链接:https://arnold-neumaier.at/software.html
5、neos solvers
neos solvers是比较有名的求解器
链接:https://neos-server.org/neos/solvers/index.html

6、netlib
里面几乎包含所有的线性求解办法

7、GAMS
里面包含一些数学库,不仅仅是优化

8、HSL Software
专门的线性方程组求解器,包含很多源代码
链接:https://www.hsl.rl.ac.uk/catalogue/
9、autodiff
收集了一些求微分的方法的网站
10、Local Optimization Software
链接:https://arnold-neumaier.at/glopt/software_l.html
11、Global Optimization Software
链接:https://arnold-neumaier.at/glopt/software_g.html
参考资料:
1、数值最优化方法(高立 编著)
-
相关阅读:
vue2循环的列表商品选择后的商品禁用
模板方法模式:定义算法骨架,子类实现具体步骤
使用 GitHub Actions 编译和发布 Android APK
241.为运算表达式设计优先级
SaaS服务平台软件是什么?
MongoDB实践
解决idea maven 不使用本地库jar包问题
C高级文件相关指令
Mac M1 问题记录
阿里高工带来的20022最新面试总结太香了
- 原文地址:https://blog.csdn.net/qq_44339029/article/details/132393092