-
Python大数据之PySpark(六)RDD的操作
RDD的操作
函数分类
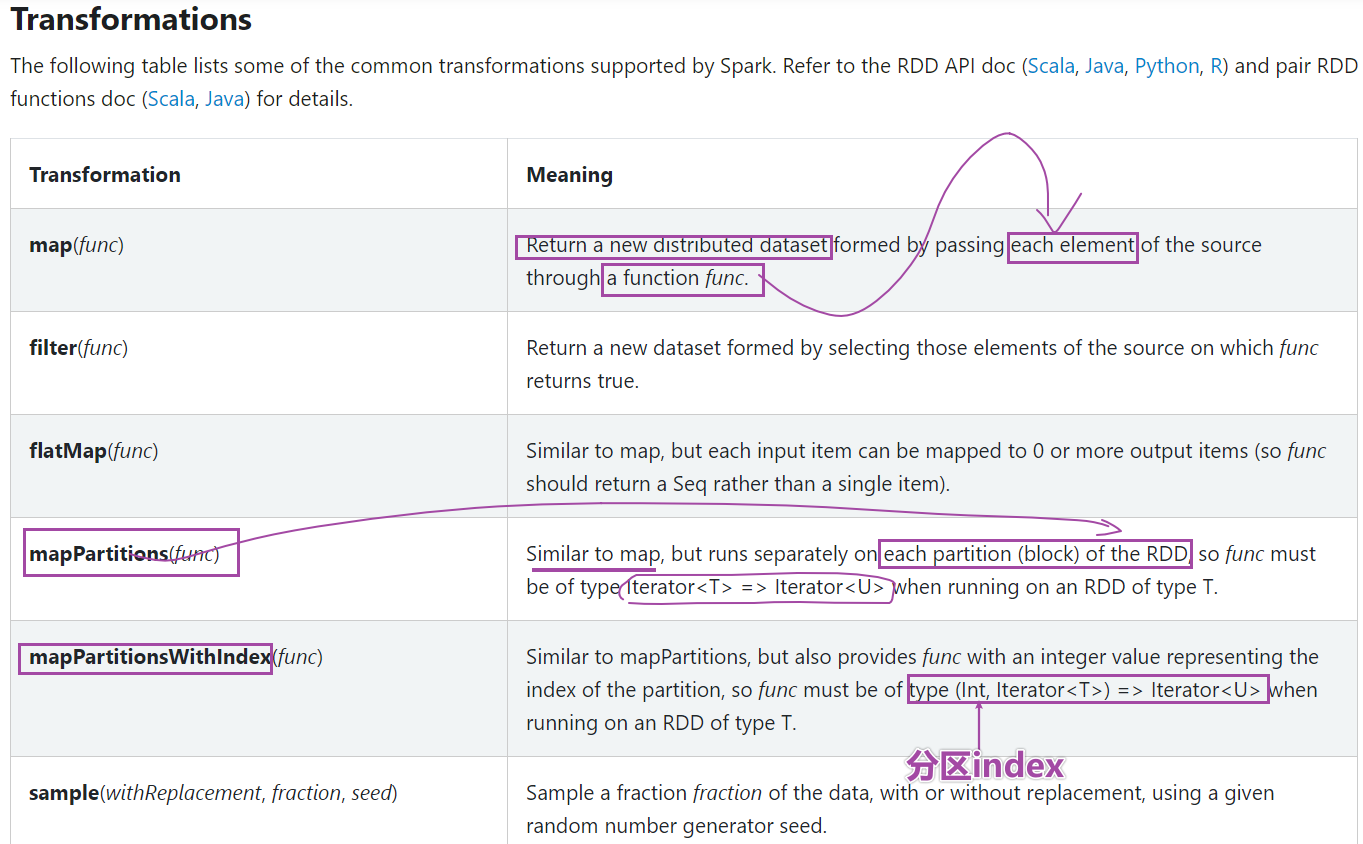
- *Transformation操作只是建立计算关系,而Action 操作才是实际的执行者*。
-

- Transformation算子
- 转换算子
- 操作之间不算的转换,如果想看到结果通过action算子触发
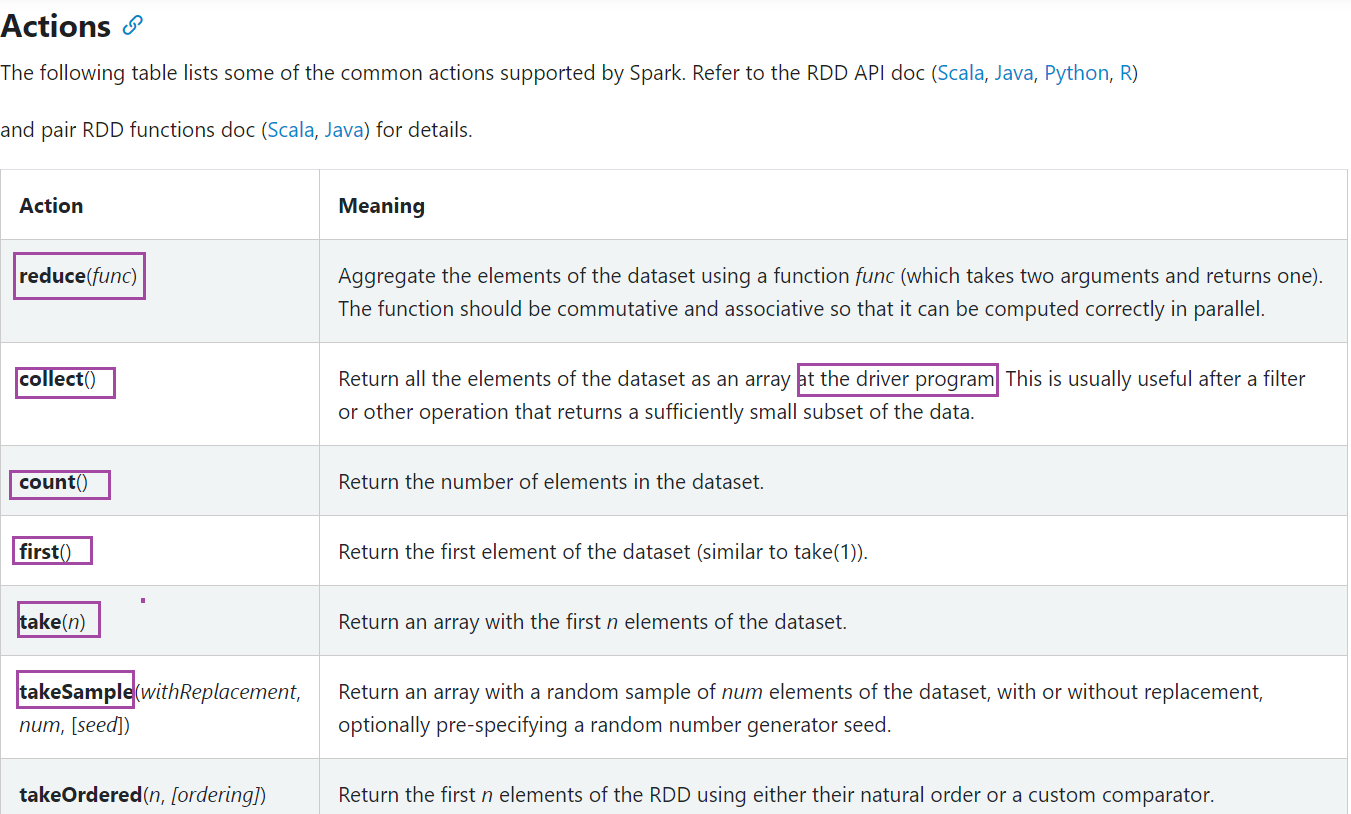
- Action算子
- 行动算子
- 触发Job的执行,能够看到结果信息
Transformation函数
-
值类型valueType
-
map
-
flatMap
-
filter
-
mapValue
双值类型DoubleValueType
- intersection
- union
- difference
- distinct
Key-Value值类型
- reduceByKey
- groupByKey
- sortByKey
- combineByKey是底层API
- foldBykey
- aggreateBykey
Action函数
- collect
- saveAsTextFile
- first
- take
- takeSample
- top
基础练习[Wordcount快速演示]
Transformer算子
- 单value类型代码
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf,SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 ''' if __name__ == '__main__': # 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN")#一般在工作中不这么写,直接复制log4j文件 # 2-map操作 rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6]) rdd__map = rdd1.map(lambda x: x * 2) print(rdd__map.glom().collect())#[2, 4, 6, 8, 10, 12],#[[2, 4, 6], [8, 10, 12]] # 3-filter操作 print(rdd1.glom().collect()) print(rdd1.filter(lambda x: x > 3).glom().collect()) # 4-flatMap rdd2 = sc.parallelize([" hello you", "hello me "]) print(rdd2.flatMap(lambda word: re.split("\s+", word.strip())).collect()) # 5-groupBY x = sc.parallelize([1, 2, 3]) y = x.groupBy(lambda x: 'A' if (x % 2 == 1) else 'B') print(y.mapValues(list).collect())#[('A', [1, 3]), ('B', [2])] # 6-mapValue x1 = sc.parallelize([("a", ["apple", "banana", "lemon"]), ("b", ["grapes"])]) def f(x): return len(x) print(x1.mapValues(f).collect())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 双value类型的代码
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 ''' if __name__ == '__main__': # 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 # 2-对两个RDD求并集 rdd1 = sc.parallelize([1, 2, 3, 4, 5]) rdd2 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8]) Union_RDD = rdd1.union(rdd2) print(Union_RDD.collect()) print(rdd1.intersection(rdd2).collect()) print(rdd2.subtract(rdd1).collect()) # Return a new RDD containing the distinct elements in this RDD. print(Union_RDD.distinct().collect()) print(Union_RDD.distinct().glom().collect())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- key-Value算子
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 ''' if __name__ == '__main__': # 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 # 2-key和value类型算子 # groupByKey rdd1 = sc.parallelize([("a", 1), ("b", 2)]) rdd2 = sc.parallelize([("c", 1), ("b", 3)]) rdd3 = rdd1.union(rdd2) key1 = rdd3.groupByKey() print("groupByKey:",key1.collect()) #groupByKey: # [('b',# ('c', # ('a', print(key1.mapValues(list).collect())#需要通过mapValue获取groupByKey的值 print(key1.mapValues(tuple).collect()) # reduceByKey key2 = rdd3.reduceByKey(lambda x, y: x + y) print(key2.collect()) # sortByKey print(key2.map(lambda x: (x[1], x[0])).sortByKey(False).collect())#[(5, 'b'), (1, 'c'), (1, 'a')] # countByKey print(rdd3.countByValue())#defaultdict( - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
Action算子
- 部分操作
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 ''' if __name__ == '__main__': # 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 # 2-key和value类型算子 # groupByKey rdd1 = sc.parallelize([("a", 1), ("b", 2)]) rdd2 = sc.parallelize([("c", 1), ("b", 3)]) print(rdd1.first()) print(rdd1.take(2)) print(rdd1.top(2)) print(rdd1.collect()) rdd3 = sc.parallelize([1, 2, 3, 4, 5]) from operator import add from operator import mul print(rdd3.reduce(add)) print(rdd3.reduce(mul)) rdd4 = sc.parallelize(range(0, 10)) # 能否保证每次抽样结果是一致的,使用seed随机数种子 print(rdd4.takeSample(True, 3, 123)) print(rdd4.takeSample(True, 3, 123)) print(rdd4.takeSample(True, 3, 123)) print(rdd4.takeSample(True, 3, 34))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 其他补充算子
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 ''' def f(iterator): # 【1,2,3】 【4,5】 for x in iterator: # for x in 【1,2,3】 x=1,2,3 print 1.2.3 print(x) def f1(iterator): # 【1,2,3】 【4,5】 sum(1+2+3) sum(4+5) yield sum(iterator) if __name__ == '__main__': # 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 # 2-foreach-Applies a function to all elements of this RDD. rdd1 = sc.parallelize([("a", 1), ("b", 2)]) print(rdd1.glom().collect()) # def f(x):print(x) rdd1.foreach(lambda x: print(x)) # 3-foreachPartition--Applies a function to each partition of this RDD. # 从性能角度分析,按照分区并行比元素更加高效 rdd1.foreachPartition(f) # 4-map---按照元素进行转换 rdd2 = sc.parallelize([1, 2, 3, 4]) print(rdd2.map(lambda x: x * 2).collect()) # 5-mapPartiton-----按照分区进行转换 # Return a new RDD by applying a function to each partition of this RDD. print(rdd2.mapPartitions(f1).collect()) # [3, 7]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
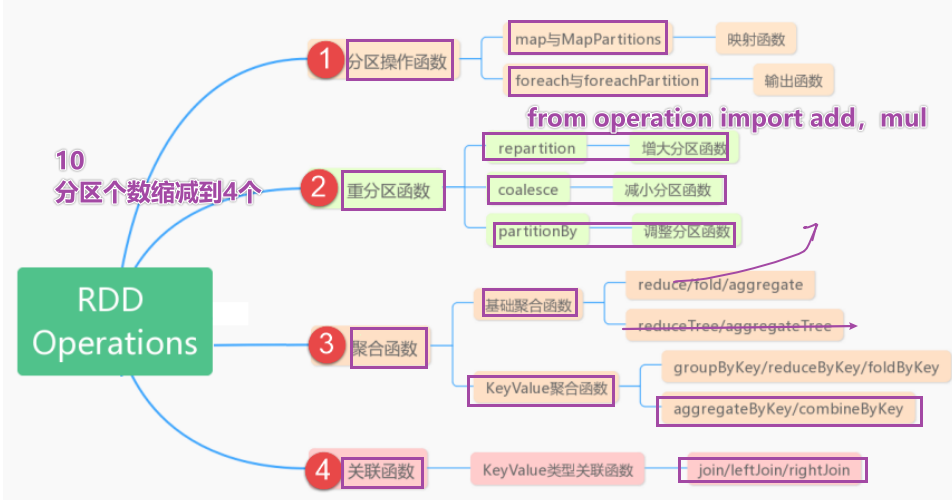
重要函数
基本函数
- 基础的transformation
- 和action操作
分区操作函数
- mapPartition
- foreachPartition
重分区函数
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 alt+6 可以调出来所有TODO, TODO是Python提供了预留功能的地方 ''' if __name__ == '__main__': #TODO: 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 #TODO: 2-执行重分区函数--repartition rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3) print("partitions num:",rdd1.getNumPartitions()) print(rdd1.glom().collect())#[[1, 2], [3, 4], [5, 6]] print("repartition result:") #TODO: repartition可以增加分区也可以减少分区,但是都会产生shuflle,如果减少分区的化建议使用coalesc避免发生shuffle rdd__repartition1 = rdd1.repartition(5) print("increase partition",rdd__repartition1.glom().collect())#[[], [1, 2], [5, 6], [3, 4], []] rdd__repartition2 = rdd1.repartition(2) print("decrease partition",rdd__repartition2.glom().collect())#decrease partition [[1, 2, 5, 6], [3, 4]] #TODO: 3-减少分区--coalese print(rdd1.coalesce(2).glom().collect())#[[1, 2], [3, 4, 5, 6]] print(rdd1.coalesce(5).glom().collect())#[[1, 2], [3, 4], [5, 6]] print(rdd1.coalesce(5,True).glom().collect())#[[], [1, 2], [5, 6], [3, 4], []] # 结论:repartition默认调用的是coalese的shuffle为True的方法 # TODO: 4-PartitonBy,可以调整分区,还可以调整分区器(一种hash分区器(一般打散数据),一种range分区器(排序拍好的)) # 此类专门针对RDD中数据类型为KeyValue对提供函数 # rdd五大特性中有第四个特点key-value分区器,默认是hashpartitioner分区器 rdd__map = rdd1.map(lambda x: (x, x)) print("partitions length:",rdd__map.getNumPartitions())#partitions length: 3 print(rdd__map.partitionBy(2).glom().collect())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 代码:
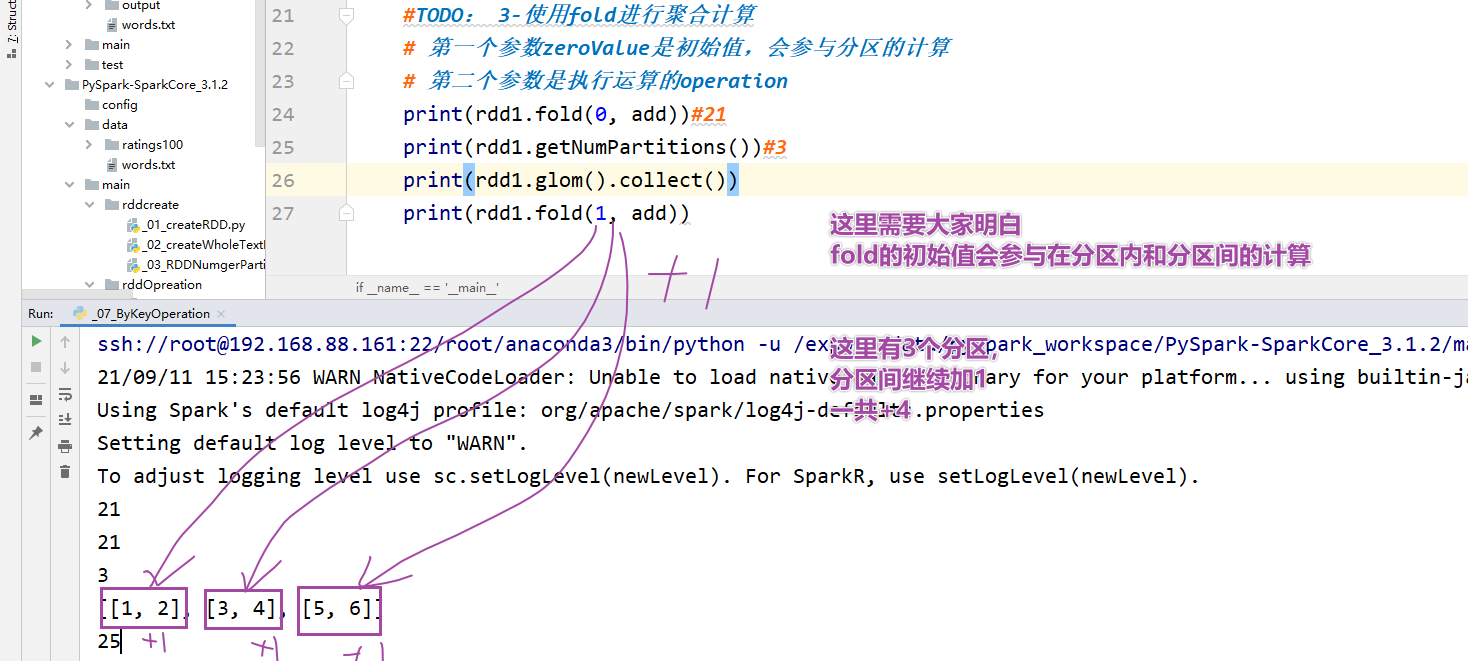
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 alt+6 可以调出来所有TODO, TODO是Python提供了预留功能的地方 ''' def addNum(x,y): return x+y if __name__ == '__main__': # TODO: 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 # TODO: 2-使用reduce进行聚合计算 rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3) from operator import add # 直接得到返回值-21 print(rdd1.reduce(add)) # TODO: 3-使用fold进行聚合计算 # 第一个参数zeroValue是初始值,会参与分区的计算 #第二个参数是执行运算的operation print(rdd1.fold(0, add)) # 21 print(rdd1.getNumPartitions()) # 3 print(rdd1.glom().collect()) print("fold result:", rdd1.fold(10, add)) # TODO: 3-使用aggreate进行聚合计算 # seqOp分区内的操作, combOp分区间的操作 print(rdd1.aggregate(0, add, add)) # 21 print(rdd1.glom().collect()) print("aggregate result:", rdd1.aggregate(1, add, add)) # aggregate result: 25 # 结论:fold是aggregate的简化版本,fold分区内和分区间的函数是一致的 print("aggregate result:", rdd1.aggregate(1, addNum, addNum)) # aggregate result: 25- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
* byKey类的聚合函数 * **groupByKey----如何获取value的数据?------答案:result.mapValue(list).collect** * **reduceByKey** * foldBykey- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

-
aggregateByKey
-
CombineByKey:这是一个更为底层实现的bykey 聚合算子,可以实现更多复杂功能
-

-
案例1:
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 alt+6 可以调出来所有TODO, TODO是Python提供了预留功能的地方 ''' ''' 对初始值进行操作 ''' def createCombiner(value): #('a',[1]) return [value] # 这里的x=createCombiner得到的[value]结果 def mergeValue(x,y): #这里相同a的value=y=1 x.append(y)#('a', [1, 1]),('b', [1]) return x def mergeCombiners(a,b): a.extend(b) return a if __name__ == '__main__': # TODO: 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 # TODO: 2-基础数据处理 from operator import add rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)]) # [(a:[1,1]),(b,[1,1])] print(sorted(rdd.groupByKey().mapValues(list).collect())) # 使用自定义集聚合函数组合每个键的元素的通用功能。 # - `createCombiner`, which turns a V into a C (e.g., creates a one-element list) # 对初始值进行操作 # - `mergeValue`, to merge a V into a C (e.g., adds it to the end ofa list) # 对分区内的元素进行合并 # - `mergeCombiners`, to combine two C's into a single one (e.g., merges the lists) # 对分区间的元素进行合并 by_key_result = rdd.combineByKey(createCombiner, mergeValue, mergeCombiners) print(sorted(by_key_result.collect()))#[('a', [1, 1]), ('b', [1])]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 案例2
# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re ''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 alt+6 可以调出来所有TODO, TODO是Python提供了预留功能的地方 ''' ''' 对初始值进行操作 [value,1],value指的是当前学生成绩,1代表的是未来算一下一个学生考了几次考试 ("Fred", 88)----------[88,1] ''' def createCombiner(value): # return [value, 1] ''' x代表的是 [value,1]值,x=[88,1] y代表的相同key的value,比如("Fred", 95)的95,执行分区内的累加 ''' def mergeValue(x, y): return [x[0] + y, x[1] + 1] ''' a = a[0] value,a[1] 几次考试 ''' def mergeCombiners(a, b): return [a[0] + b[0], a[1] + b[1]] if __name__ == '__main__': # TODO: 1-创建SparkContext申请资源 conf = SparkConf().setAppName("mini2").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件 # TODO: 2-基础数据处理 from operator import add # 这里需要实现需求:求解一个学生的平均成绩 x = sc.parallelize([("Fred", 88), ("Fred", 95), ("Fred", 91), ("Wilma", 93), ("Wilma", 95), ("Wilma", 98)], 3) print(x.glom().collect()) # 第一个分区("Fred", 88), ("Fred", 95) # 第二个分区("Fred", 91), ("Wilma", 93), # 第三个分区("Wilma", 95), ("Wilma", 98) # reduceByKey reduce_by_key_rdd = x.reduceByKey(lambda x, y: x + y) print("reduceBykey:", reduce_by_key_rdd.collect()) # [('Fred', 274), ('Wilma', 286)] # 如何求解平均成绩? # 使用自定义集聚合函数组合每个键的元素的通用功能。 # - `createCombiner`, which turns a V into a C (e.g., creates a one-element list) # 对初始值进行操作 # - `mergeValue`, to merge a V into a C (e.g., adds it to the end ofa list) # 对分区内的元素进行合并 # - `mergeCombiners`, to combine two C's into a single one (e.g., merges the lists) # 对分区间的元素进行合并 combine_by_key_rdd = x.combineByKey(createCombiner, mergeValue, mergeCombiners) print(combine_by_key_rdd.collect()) # [('Fred', [274, 3]), ('Wilma', [286, 3])] # 接下来平均值如何实现--('Fred', [274, 3])---x[0]=Fred x[1]= [274, 3],x[1][0]=274,x[1][1]=3 print(combine_by_key_rdd.map(lambda x: (x[0], int(x[1][0] / x[1][1]))).collect())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 面试题:

- 关联函数
AI副业实战手册:http://www.yibencezi.com/notes/253200?affiliate_id=1317(目前40+工具及实战案例,持续更新,实战类小册排名第一,做三个月挣不到钱找我退款,交个朋友的产品)
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢感觉这辈子,最深情绵长的注视,都给了手机⭐
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12453356.html -
相关阅读:
基于DJYOS的IIC驱动编写指导手册
MySQL统计函数count详解
【计算机基础】CPU概述及CPU的内部结构
eS6常用语法
修改了Excel默认打开方式后仍然使用WPS打开的解决办法
暑假leetcode剑指offer每日一题打卡-第二十天-剑指 Offer 49. 丑数(middle)
systemverilog学习 === 随机化约束(完结)
九州云亮相全球边缘计算大会,深耕边缘领域赋能产业未来新生态
解析字符串拼接的两种情况
ElasticSearch(二)
- 原文地址:https://blog.csdn.net/xianyu120/article/details/133655708