-
cuda系列详细教程-花絮
提示:本文是我cuda教程部分代码和内容构成,严禁侵权!
前言
随着人工智能的发展与人才的内卷,很多企业已将深度学习算法的C++部署能力作为基本技能之一。面对诸多arm相关且资源有限的设备,往往想更好的提速,满足更高时效性,必将更多类似矩阵相关运算交给CUDA处理。同时,面对市场诸多教程与诸多博客岑子不起的教程或高昂教程费用,使读者(特别是小白)容易迷糊,无法快速入手CUDA编程,实现工程化。
因此,我将结合我的工程实战经验,我将在本专栏实现CUDA系列教程,帮助读者(或小白)实现CUDA工程化,掌握CUDA编程能力。学习我的教程专栏,你将绝对能实现CUDA工程化,完全从环境安装到CUDA核函数编程,从核函数到使用相关内存优化,从内存优化到深度学习算子开发(如:nms),从算子优化到模型(以yolo系列为基准)部署。最重要的是,我的教程将简单明了直切主题,CUDA理论与实战实例应用,并附相关代码,可直接上手实战。我的想法是掌握必要CUDA相关理论,去除非必须繁杂理论,实现CUDA算法应用开发,待进一步提高,将进一步理解更高深理论。
原文链接–>点击这里
一、核函数index寻找
cuda通过线程执行并行运算,理所当然,我们需要知道如何使用每个线程实现自己的计算逻辑。而线程操作通过索引(index)操作,索引和block与grid挂钩,自然我们需要知晓如何在grid与block中确定索引。为此,我写了索引寻找规律,可以通过公式直接计算,我在此不细说,仅展示以下展示部分代码,其详细内容和附件可点击我的链接。
部分展示代码如下:
1、3d grid与1d block索引
blockSize = blockDim.x(一维 block 的大小) blockId = Dx * Dy * z + Dx * y + x (三维 grid 中 block 的 id,用公式) = gridDim.x * gridDim.y * blockIdx.z + gridDim.x * blockIdx.y + blockIdx.x threadId = threadIdx.x (一维 block 中 thread 的 id) Id = (gridDim.x * gridDim.y * blockIdx.z + gridDim.x * blockIdx.y + blockIdx.x ) * blockDim.x + threadIdx.x- 1
- 2
- 3
- 4
- 5
2、1d grid, 2d block索引
blockSize = blockDim.x * blockDim.y(二维 block 的大小) blockId = blockIdx.x(一维 grid 中 block id) threadId = Dx * y + x (二维 block 中 thread 的 id) = blockDim.x * threadIdx.y + threadIdx.x Id = blockIdx.x * (blockDim.x * blockDim.y) + blockDim.x * threadIdx.y + threadIdx.x- 1
- 2
- 3
- 4
- 5
本内容教程链接–>点击这里
二、kernel函数实例
如上所说,我们知道kernel函数索引寻找方法,我们自然想通过索引实现各种运算,多数为矩阵运算。为此,我写了大量实例cuda代码,并用不同实例说明其cuda编码规律,我将以其中一个实例矩阵加法代码作为展示,此代码使用多种途径求其结果,其详细内容和附件代码可点击我的链接。
__global__ void gpu_matrix_plus_thread(int* a, int* b, int* c) { //方法一:通过id方式计算 //grid为2维度,block为2维度,使用公式id=blocksize * blockid + threadid int blocksize = blockDim.x*blockDim.y; int blockid = gridDim.x*blockIdx.y+blockIdx.x; int threadid = blockDim.x*threadIdx.y+threadIdx.x; int id = blocksize * blockid + threadid; c[id] = a[id] + b[id]; } __global__ void gpu_matrix_plus1(int* a, int* b, int* c, int m, int n) { //方法二:通过row与col的方式计算-->通过变换列给出id int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; c[row*n + col] = a[row*n + col] + b[row*n + col]; } __global__ void gpu_matrix_plus2(int* a, int* b, int* c, int m, int n) { //方法三:通过row与col的方式计算-->通过变换行给出id int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; c[row + col*m] = a[row + col*m] + b[row + col*m]; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
本内容教程链接–>点击这里
三、性能优化(内存)
既然我们已可自如实现自己计算逻辑,那么我么也需兼顾运行效率,运行速度提升可通过更好pipeline逻辑实现,也可通过内存方式实现,而逻辑架构因人而异,我将不在细说,内存实现可通过对cuda内存理解便可掌握。为此,我也写了内存相关实例代码,介绍其内存使用方法,如纹理内存、共享内存等,我将以纹理内存代码作为展示,其更多详细内容和附件代码可点击我的链接。
/核心代码,在gpu端执行的kernel, __global__ void Textureone(unsigned int* listTarget, int size) { unsigned int texvalue = 0; int index = blockIdx.x * blockDim.x + threadIdx.x; //通过线程ID得到数组下标 if (index < size) texvalue= tex1Dfetch(texone, index)*100; //通过索引获得纹理值再乘100 listTarget[index] = texvalue; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
本内容教程链接–>点击这里
四、原子操作
在 CUDA 中,原子操作是一种用于确保多个线程同时访问同一内存地址时的同步机制。原子操作可以确保只有一个线程可以访问内存地址,并且可以避免数据竞争和不确定的结果。我将已实例代码展示原子操作,以下为原子操作实例,其更多详细内容和附件代码可点击我的链接。
部分原子操作代码如下:
_global__ void kernel(int* data) { int tid = threadIdx.x + blockIdx.x * blockDim.x; // 对共享内存中的数据执行原子加操作 atomicAdd(&data[tid], 1); } int main() { int size = 1024; int* data = new int[size]; int* d_data; cudaMalloc(&d_data, size * sizeof(int)); cudaMemcpy(d_data, data, size * sizeof(int), cudaMemcpyHostToDevice); kernel<<<1, size>>>(d_data); cudaMemcpy(data, d_data, size * sizeof(int), cudaMemcpyDeviceToHost); cudaFree(d_data); delete[] data; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
本内容教程链接–>点击这里
五、流stream
单流数据与核函数实战应用
计算host_a与host_b对应值之和,我们采用单个流对数据分成N块,
在数据位置使用流,也在kernel位置使用流,模拟数据位置与kernel位置流的使用情景。
代码如下:int stream_apply1() { int N = 32; const int FULL_DATA_SIZE = N * 2; //获取设备属性 cudaDeviceProp prop; int deviceID; cudaGetDevice(&deviceID); cudaGetDeviceProperties(&prop, deviceID); //检查设备是否支持重叠功能 if (!prop.deviceOverlap) { printf("No device will handle overlaps. so no speed up from stream.\n"); return 0; } //启动计时器 cudaEvent_t start, stop; float elapsedTime; cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start, 0); //创建一个CUDA流 cudaStream_t stream; cudaStreamCreate(&stream); int* host_a, * host_b, * host_c; int* dev_a, * dev_b, * dev_c; //在GPU上分配内存 cudaMalloc((void**)&dev_a, N * sizeof(int)); cudaMalloc((void**)&dev_b, N * sizeof(int)); cudaMalloc((void**)&dev_c, N * sizeof(int)); //在CPU上分配页锁定内存 cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault); cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault); cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault); //主机上的内存赋值 for (int i = 0; i < FULL_DATA_SIZE; i++) { host_a[i] = i; host_b[i] = 10000 * i; } for (int i = 0; i < FULL_DATA_SIZE; i += N) { cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream); cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream); kernel_one << <FULL_DATA_SIZE / 32, 32, 0, stream >> > (dev_a, dev_b, dev_c); cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream); } // wait until gpu execution finish cudaStreamSynchronize(stream); cudaEventRecord(stop, 0); cudaEventSynchronize(stop); cudaEventElapsedTime(&elapsedTime, start, stop); std::cout << "消耗时间: " << elapsedTime << std::endl; cout << "输入数据host_a" << endl; for (int i = 0; i < FULL_DATA_SIZE; i++) { std::cout << host_a[i] << "\t"; } cout << "\n输入数据host_b" << endl; for (int i = 0; i < FULL_DATA_SIZE; i++) { std::cout << host_b[i] << "\t"; } cout << "\n输出结果host_c" << endl; for (int i = 0; i < FULL_DATA_SIZE; i++) {std::cout << host_c[i] << "\t"; } getchar(); // free stream and mem cudaFreeHost(host_a); cudaFreeHost(host_b); cudaFreeHost(host_c); cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); cudaStreamDestroy(stream); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
本内容教程链接–>点击这里
六、cuda处理nms编码
大量算法的后处理逻辑均会使用NMS算法去重,然CPU算法较慢,为此我写了cuda的NMS算法处理,以下将部分展示,其详细代码可点击我的链接。
部分代码如下:
// 定义CUDA核函数,用于执行NMS算法 __global__ void nms_kernel(nms_box* boxes, int* indices, int* num_indices, float nms_thr) { /* boxes:输入nms信息,为结构体 indices:输入为列表序列,记录所有box,如[0,1,2,3,4,5,...],后续将不需要会变成-1。 num_indices:记录有多少个box数量 float nms_thr:nms的阈值,实际为iou阈值 */ int i = blockIdx.x * blockDim.x + threadIdx.x; if (i >= *num_indices) { return; } int index = indices[i]; if (index == -1) { return; } nms_box box = boxes[index]; for (int j = i + 1; j < *num_indices; j++) { int other_index = indices[j]; if (other_index == -1) { continue; } nms_box other_box = boxes[other_index]; float iou_value = iou(box, other_box); printf("iou value:%f\n", iou_value); if (iou_value > nms_thr) { indices[j] = -1; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
不同nms结果图示:
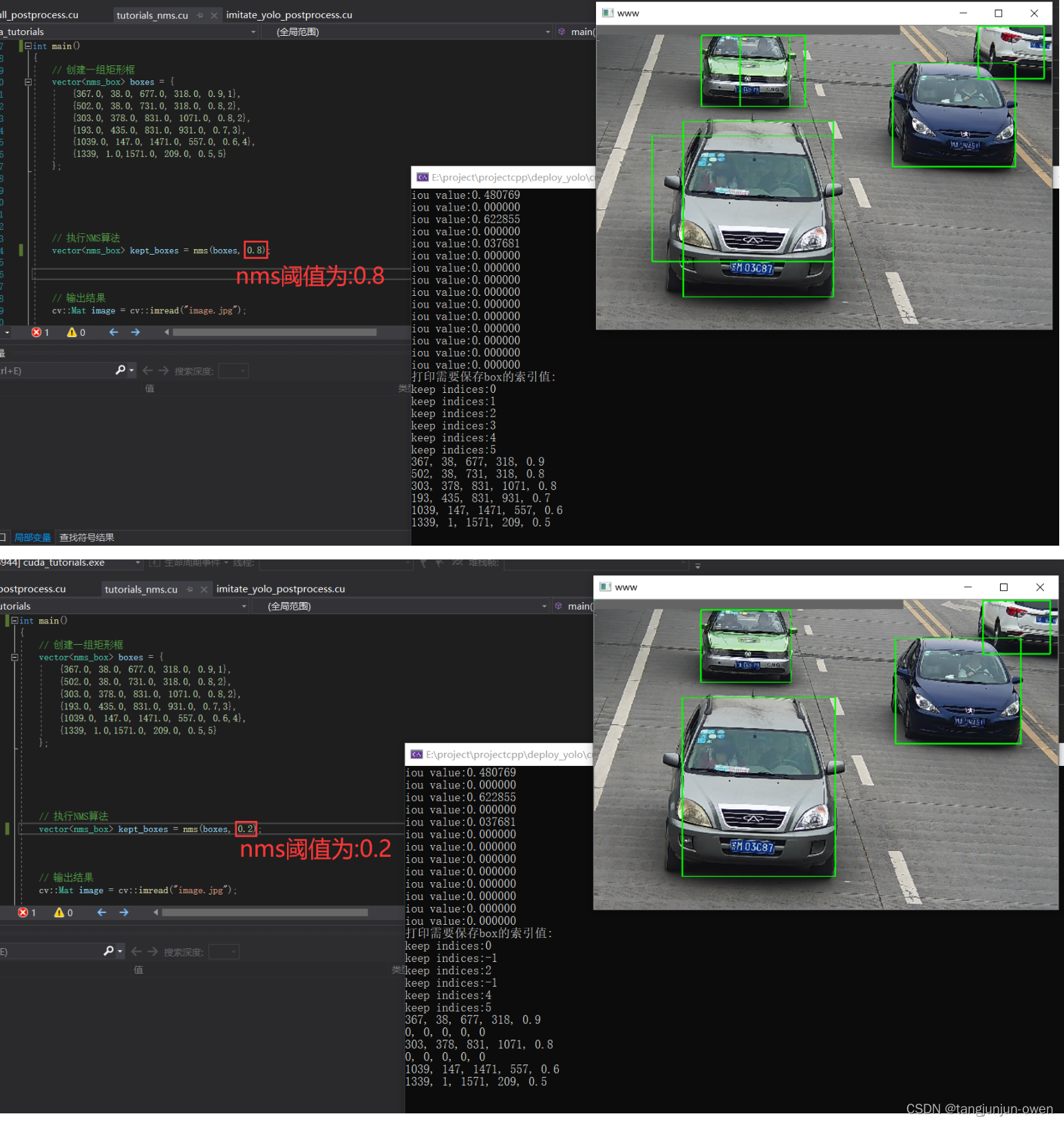
七、cuda处理yolo算法输出编码
在tensorrt部署中,yolo算法输出在gpu设备上且数据较为庞大(如:640输入将有25200*(class_num+5)*batch数据),使用cpu处理,需将值从gpu端复制host端,复制过程会花费很多时间。因此,我为此我写了cuda的yolo输出数据处理,以下将部分展示,其详细代码可点击我的链接。
代码如下:
__global__ void decode_yolo_kernel(float* prob, float* parray, int max_objects, int cls_num, float conf_thr, int* d_count) { int idx = blockDim.x * blockIdx.x + threadIdx.x; int tmp_idx = idx * (cls_num + 5); float left = prob[tmp_idx + 0]; float top = prob[tmp_idx + 1]; float right = prob[tmp_idx + 2]; float bottom = prob[tmp_idx + 3]; float conf = prob[tmp_idx + 4]; float class_score = prob[tmp_idx + 5]; float tmp_conf = conf * class_score; int class_id = 0; for (int j = 0; j < cls_num; j++) { int cls_idx = tmp_idx + 5 + j; if (tmp_conf < conf * prob[cls_idx]) { class_id = j; tmp_conf = conf * prob[cls_idx]; } } if (tmp_conf < conf_thr) { return; } int index = atomicAdd(d_count, 1); if (index >= max_objects) { return; } int out_index = index * 6; parray[out_index + 0] = left; parray[out_index + 1] = top; parray[out_index + 2] = right; parray[out_index + 3] = bottom; parray[out_index + 4] = tmp_conf; parray[out_index + 5] = class_id; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
代码解释:
目的:简化模拟yolo输出结果于cuda核函数中处理
假设:置信度阀值为0.45,类别为2,最大目标数为3,
下图数据说明:左边为核函数实现代码展示;右边每一含为一个目标预测结果,分别表示box值[x,y,w,h]、置信度conf、类别预测值[c1_score,c2_score];右下角为cuda核函数选择目标结果,其中conf为类别score*conf;
实现方法:利用核函数与原子操作完成目标筛选。
运行结果如下:

本内容教程链接–>点击这里八、cuda处理yolo算法整个过程
在tensorrt部署中,yolo算法输出使用gpu处理已在上面涉及,然如何去重box与yolo整套后处理呢?为此,我也写了基于cuda处理yolo的整个过程,以下将部分代码展示,其详细代码可点击我的链接。
代码如下:
void imitate_yolo_postprocess_convert() { const int block = 32; /*************************************************开始cuda计算***********************************************/ cudaStream_t stream; cudaStreamCreate(&stream); h_count = 0; cudaMemcpy(d_count, &h_count, sizeof(int), cudaMemcpyHostToDevice); //初始化记录有效变量d_count与h_count int grid = (anchor_output_num + block - 1) / block; decode_yolo_kernel << < grid, block, 0, stream >> > (gpu_input, gpu_output, max_object, cls_num, conf_thr, d_count); cudaMemcpy(&h_count, d_count, sizeof(int), cudaMemcpyDeviceToHost); if (h_count > max_object) { h_count = max_object; }; /****************************************打印模型输出输出数据结果--》通过置信度已过滤不满足要求和给出类别**********************************/ float* host_decode = nullptr; // 保存gpu处理的变量 cudaMallocHost((void**)&host_decode, sizeof(float) * max_object * 6); cudaMemcpy(host_decode, gpu_output, sizeof(float) * max_object * 6, cudaMemcpyDeviceToHost); std::cout << "\n\n打印输出结果-gpu_output\n" << endl; if (h_count == 0) { std::cout << "\n无检测结果" << endl; } for (int i = 0; i < h_count; i++) { int idx = i * 6; std::cout << "x1:" << host_decode[idx] << "\ty1:" << host_decode[idx + 1] << "\tx2:" << host_decode[idx + 2] << "\ty2:" << host_decode[idx + 3] << "\tconf:" << host_decode[idx + 4] << "\tclass_id:" << host_decode[idx + 5] << endl; } /******************************************************************************************************************************/ int grid_max = (max_object + block - 1) / block; data_format_convert << < grid_max, block, 0, stream >> > (d_boxes, gpu_output, h_count); // gpu_output格式为[x1,y1,conf,cls_id] /****************************************将数据转换为带有nms_box格式数据******************************************************/ nms_box* h_boxes_format = nullptr; cudaMallocHost(&h_boxes_format, anchor_output_num * sizeof(nms_box)); cudaMemcpy(h_boxes_format, d_boxes, anchor_output_num * sizeof(nms_box), cudaMemcpyDeviceToHost); std::cout << "\n\n打印格式转换输出-h_boxes_format\n" << endl; if (h_count == 0) { std::cout << "\n无检测结果" << endl; } for (int i = 0; i < h_count; i++) { nms_box bb = h_boxes_format[i]; std::cout << "x1:" << bb.x1 << "\ty1:" << bb.y1 << "\tx2:" << bb.x2 << "\ty2:" << bb.y2 << "\tconf:" << bb.score << "\tclass_id:" << bb.cls_id << endl; } /******************************************************************************************************************************/ cudaMemcpy(d_nms_indices, h_nms_indices_init, max_object * sizeof(int), cudaMemcpyHostToDevice); //初始化nms处理的索引-->很重要 /****************************************查看d_nms_indices数据******************************************************/ int* d_nms_indices_visual = nullptr; cudaMallocHost(&d_nms_indices_visual, max_object * sizeof(int)); cudaMemcpy(d_nms_indices_visual, d_nms_indices, max_object * sizeof(int), cudaMemcpyDeviceToHost); std::cout << "\n\nd_nms_indices:\n" << endl; for (int i = 0; i < max_object; i++) { std::cout << "\t" << d_nms_indices_visual[i] << endl; } /******************************************************************************************************************************/ nms_yolo_kernel << <grid_max, block >> > (d_boxes, d_nms_indices, h_count, nms_thr); /*******将yolo的gpu上结果转host端,然后保存结果处理-->最终结果保存在keep_boxes中**********/ cudaMemcpy(h_boxes, d_boxes, anchor_output_num * sizeof(nms_box), cudaMemcpyDeviceToHost); cudaMemcpy(h_nms_indices, d_nms_indices, max_object * sizeof(int), cudaMemcpyDeviceToHost); //保存处理后的indice vector<nms_box> keep_boxes(h_count); for (int i = 0; i < h_count; i++) { if (h_nms_indices[i] > -1) { keep_boxes[i] = h_boxes[i]; } } /****************************************查看nms处理后的-d_nms_indices******************************************************/ std::cout << "nms处理后,保留box索引,-1表示排除obj,>-1表示保存obj" << endl; for (int i = 0; i < max_object; i++) { std::cout << h_nms_indices[i] << "\t"; } /**********************************************************************************************/ /****************************************随便一张图为背景-显示结果于图上******************************************************/ cv::Mat image = cv::imread("image.jpg"); for (nms_box box : keep_boxes) { cv::Point p1(box.x1, box.y1); cv::Point p2(box.x2, box.y2); cv::rectangle(image, p1, p2, cv::Scalar(0, 255, 0), 4, 1, 0);//矩形的两个顶点,两个顶点都包括在矩形内部 } cv::resize(image, image, cv::Size(600, 400), 0, 0, cv::INTER_NEAREST); cv::imshow("www", image); cv::waitKey(100000); cv::destroyAllWindows(); /**********************************************************************************************/ }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
注:以上代码有删减,完整代码可点击链接
结果显示如下:

本内容教程链接–>点击这里九、yolo的tensorrt部署(前后处理的cpu版与gpu版)
cpu版本的tensorrt推理方法:
void doInference(Parameters_yolo& cfg, IExecutionContext& context, float* input, float* output) { const ICudaEngine& engine = context.getEngine(); // Pointers to input and output device buffers to pass to engine. // Engine requires exactly IEngine::getNbBindings() number of buffers. //assert(engine.getNbBindings() == 2); void* buffers[2]; // In order to bind the buffers, we need to know the names of the input and output tensors. //Note that indices are guaranteed to be less than IEngine::getNbBindings() const int inputIndex = engine.getBindingIndex(cfg.input_blob_name); const int outputIndex = engine.getBindingIndex(cfg.output_blob_name); // Create GPU buffers on device cudaMalloc(&buffers[inputIndex], cfg.batchSize * 3 * cfg.input_h * cfg.input_w * sizeof(float)); cudaMalloc(&buffers[outputIndex], cfg.batchSize * cfg.output_size * sizeof(float)); // Create stream cudaStream_t stream; CHECK(cudaStreamCreate(&stream)); // DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host CHECK(cudaMemcpyAsync(buffers[inputIndex], input, cfg.batchSize * 3 * cfg.input_h * cfg.input_w * sizeof(float), cudaMemcpyHostToDevice, stream)); context.enqueue(cfg.batchSize, buffers, stream, nullptr); //推理 CHECK(cudaMemcpyAsync(output, buffers[outputIndex], cfg.batchSize * cfg.output_size * sizeof(float), cudaMemcpyDeviceToHost, stream)); // 将gpu的buffers值赋值给host cudaStreamSynchronize(stream); // Release stream and buffers,销毁 cudaStreamDestroy(stream); CHECK(cudaFree(buffers[inputIndex])); CHECK(cudaFree(buffers[outputIndex])); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
cuda版本的tensorrt推理方法:
//gpu上推理方法 void Inferencegpu(Parameters_yolo& cfg, cudaStream_t& stream, IExecutionContext& context, void** buffers, float* output) { context.enqueue(cfg.batchSize, buffers, stream, nullptr); //cudaDeviceSynchronize();//阻塞host端,直到所有的CUDA调用完成 cudaStreamSynchronize(stream); //阻塞host端,直到流里的CUDA调用完成。 CHECK(cudaMemcpyAsync(output, buffers[1], cfg.batchSize * cfg.output_size * sizeof(float), cudaMemcpyDeviceToHost, stream)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
说明:
上2个小节我展示了代码,明显看出基于cuda模型推理更简单,他们区别如下:
①、基于cuda继承cuda对图像处理,需串联stream执行推理,而无cuda无需继承stream,可自行建立或使用默认流;
②、基于cuda对gpu_buffer构建于初始化,而无cuda则在本函数中;
③、基于cuda需将stream流入下一个环节,不能销毁stream,而无cuda不需要,直接销毁;
我个人认为无cuda可以学习基于cuda部分进行优化,我将不在细说,读者可自己摸索。本内容教程链接–>点击这里
总结
本教程所使用列子均有代码呈现,并大多开源。同时,教程所罗列代码均是更好理解cuda相关内容,便于读者内容理解代码、代码理解内容、快速上手。回归主题,本教程采用纯粹cuda方式部署tensorrt的yolo算法,并与采用host方式部署tensorrt的yolo算法做了比较,意透过综合模型告知读者cuda使用方法,也意告知读者cuda惊人效果。最后,也希望读者品读与支持!
-
相关阅读:
从零学算法289
【Spring Cloud实战】消费者直接调用提供者(案例)
MyBatis的各种查询功能
云计算与虚拟化
树状数组-
说一下CSS浮动
【MySQL】数据库进阶之索引内容详解(上篇 索引分类与操作)
4.力扣c++刷题-->删除有序数组中的重复项 II
一文搞懂《前后端动态路由权限》
华为防火墙基础自学系列 | 证书申请方式
- 原文地址:https://blog.csdn.net/weixin_38252409/article/details/132787763
