-
Linux和Hadoop的学习
1. Linux的常用快捷键
复制:Ctrl+shift+C
粘贴:Ctrl+shift+V
TAB:补全命令
编写输入:i
退出编写:esc
保存并退出:shift+:2. Hadoop集群部署问题汇总
1.常见出错点:
- 权限未正确设置
- 配置文件错误
- 未格式化
2.解决问题思路:看日志log
步骤1:
cd /export/server/hadoop/logs/
步骤2:(也可以查看secondarynamenode的日志,视情况而定)
tail -100 hadoop-hadoop-namenode-node1.log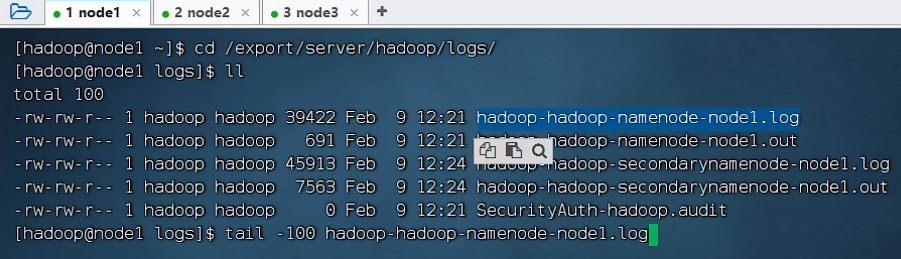
3.错误举例
问题1:Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password)
这是免密互通没有设置成功,可以通过ssh [节点]来查看是具体哪个节点没有设置成功,然后就对应的节点的免密通信进行重新设置。第一步:切换到需要设置免密通信的用户
su - [用户]- 1
第二步:生成公钥私钥
ssh-keygen -t rsa -b 4096- 1
第三步:将SSH公钥信息复制给对应服务器
ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3- 1
- 2
- 3
Hive问题的集合
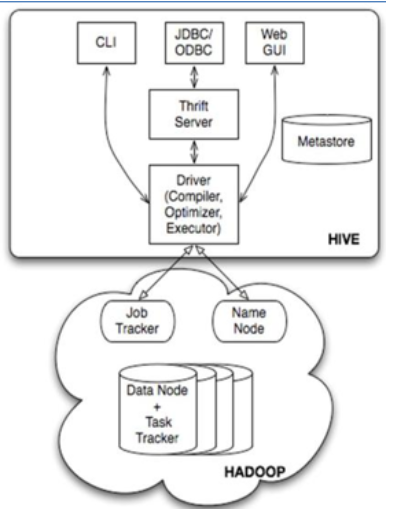
1. 什么是hive?
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
hive架构
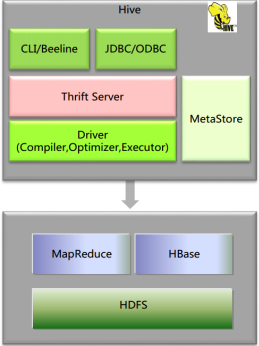
MetaStore:元数据(hive中的表的存在hdfs上的存储位置、这些表中有那些列、Partition(分区)、BUCKETS(分桶)),元数据的存储是存储在关系型数据库中的。
Driver:管理HiveQL执行的生命周期,贯穿Hive任务整个执行期间(包括:Compiler、Optimizer、Executor)
Compiler:将HQL转换为Map/Reduce任务(编译器)
Optimizer:优化HiveQL生成的执行计划和MapReduce任务进行优化(优化器)
Executor:执行Map/Reduce任务(执行器)
ThriftServer:提供thrift接口,将Hive作为一个服务端(服务器)其它访问(通过JDBC/ODBC访问)的机器作为客服端
Clients:Hive客户端,为用户访问提供接口。-
hive如何将结构化的数据文件映射为一张数据库表?
结构化的数据 -------> 数据库的表


-
提供类SQL查询功能
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。使用者只要会写SQL就行,不用掌握Mapreduce的原理。 -
优点
①可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
②延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
③容错
良好的容错性,节点出现问题SQL仍可完成执行。 -
缺点
不适合联机事务处理(OLTP) ,不适合对实时性要求高的数据分析场景。
联机事务处理(OLTP) 和 联机分析处理(OLAP)
OLTP是对数据库联机的日常操作,通常是对一条记录的査询和修改,要求快速响应用户的请求,对数据的安全性、完整性及事物吞吐量要求很高。
OLAP是对数据的査询和分析操作,通常是对海量历史数据的査询和分析,要访问的数据量非常大,査询和分析操作十分复杂。。
OLTP要求系统必须具有很高的响应速度,而OLAP对系统响应速度的要求较为宽松2. 怎么解决数据倾斜?
-
相关阅读:
GO语言篇之unsafe
C/C++语言100题练习计划 90——10 进制转 x 进制(进制转换实现)
宿主机与开发板网络共享
公开课|“技术+法律”隐私计算如何助力数据合规
共享自习室管理系统功能设计与实现
下一代 无线局域网--强健性
JVM内存模型
nacos -分布式事务-Seata** linux安装jdk ,mysql5.7启动nacos配置ideal 调用接口配合 (保姆级细节教程)
实现寻找自守数的算法(Java)
Go语言学习笔记——错误处理
- 原文地址:https://blog.csdn.net/qq_43349542/article/details/133625143