-
为什么MySQL索引选择B+树而不使用B树?
为什么mysql索引选择B+树而不使用B树?
1. 关于mysql查询效率:

2. 关于分块读取:
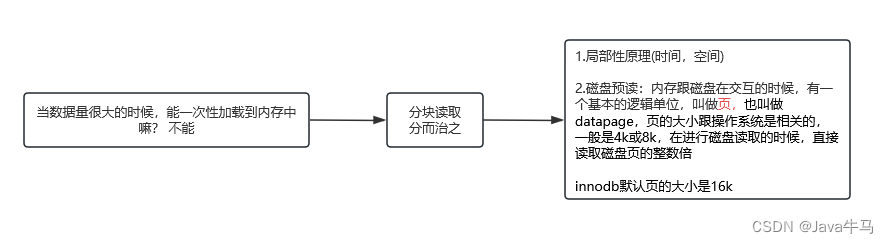
3. 关于数据格式存储:
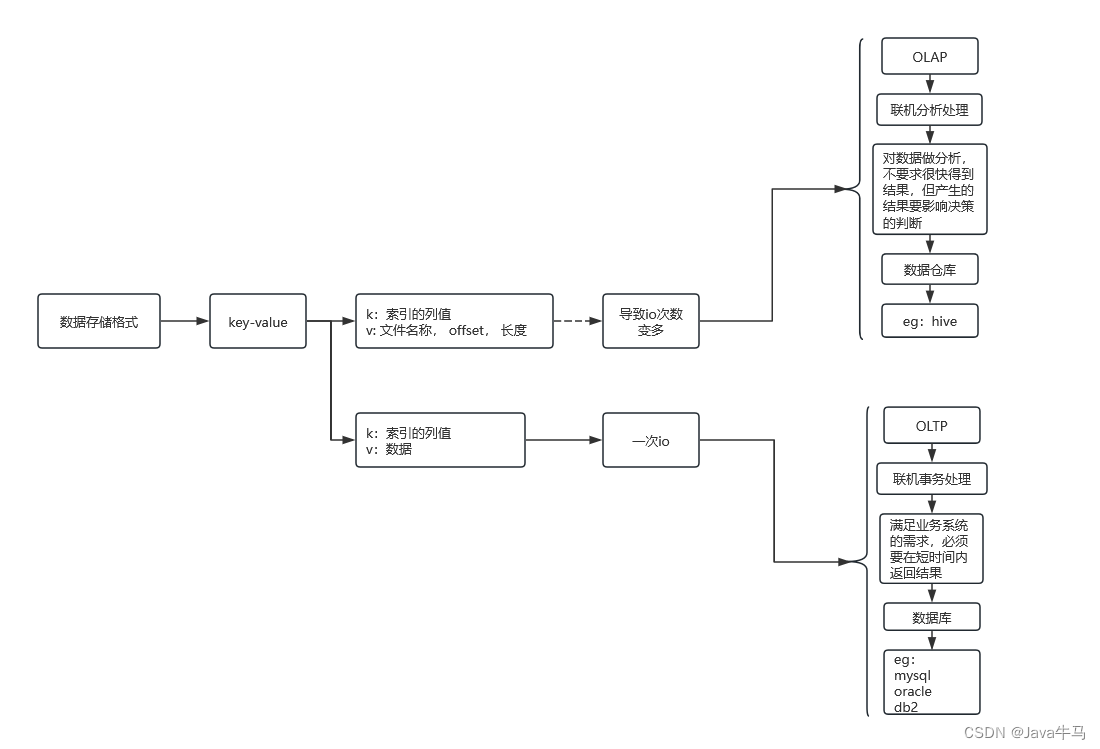
4. 关于合适的数据结构:哈希表,树
哈希表:
分析:-
- 哈希表是散列表,存储在其中的数据是无序的, 所以当进行范围查询的时候,需要挨个便利,效率较低;
-
- 存储过程中会出现哈希碰撞,哈希冲突,必须要设计应能优良的哈希算法;
-
- 存储的过程中,可能会造成存储空间的浪费;
-
- mysql的 memory 存储引擎是 哈希索引;mysql的 innodb 中有一个特性叫做 自适应hash;
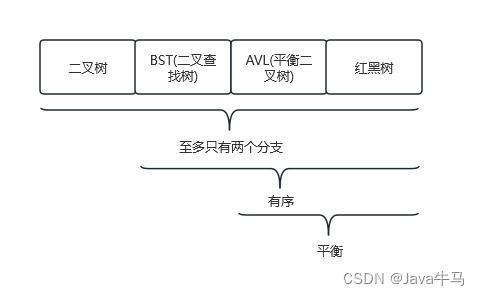
树
数据结构在线动态展示:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
如:一个二叉树:单个节点只存储一条数据,单个节点至多有两个子节点。
随着数据量的增加,树的层数自然也要增加,而树的层数的增加会导致io次数的增加(每层一次io),为了存储更多的数据而不增加io次数,引入了多叉树,即B树。B树
如下:我们选择了一个度为4(每个节点至多存储3条数据)的B树,同样的数据量的存储,我们的树的层数由原本的4层,变成了2层,减少了io查询次数。
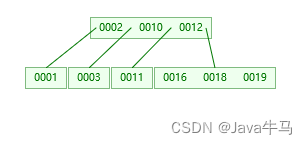
那么,随之而来的又有一个问题,三层的b树能存储多少条数据呐?B树的存储结构:每个节点可存储多条数据,且存储了对应的键值,指针和数据。
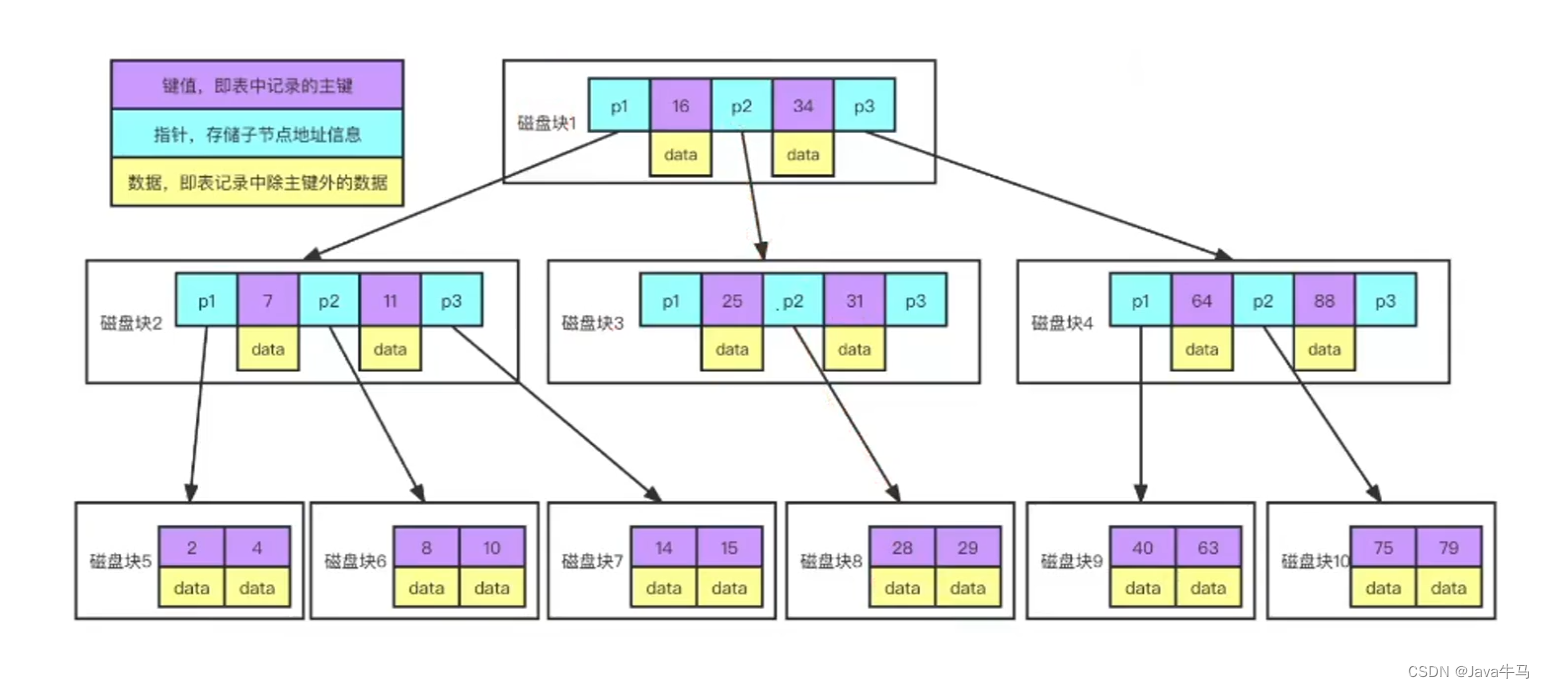
分析:
innodb默认页的大小是16k,每个树的节点除了存储数据之外,还包含键值和指针,我们假设理想模式下,一个数据是1k,那么第一层最多最多存储16条数据;第二层,就是第一层的16个指针对应第二层的16个节点,我们也假设每个节点最多存储16条,那么第二层至多存储数据也就是16 * 16条;第三层,就是第二层的16 * 16个指针,我们也假设每个节点最多存储16条,那么第三层至多存储就是16 * 16 * 16条数据,综上,三层B树最多能存储的数据就是 16 + 16 * 16 + 16 * 16 * 16 = 4368,而实际上一定是小于这个数的,所以三层的B树至多也就存储4000多条数据;4000条数据显然不满足我们平时数据库的存储使用,那么怎么才能存储更多的数据呐?B树继续加层数?多一层就多一次io,代价比较高,不适合;那么,还有另外一种方案,就是每个节点存储尽可能多的数据,因此引入了B+树:
B+树
如下:度为4(每个节点至多存储3条数据)的B+树,同样数据量的存储
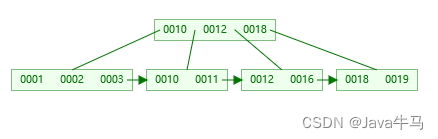
B+树的存储结构:上层节点只存储指针和键值,最底层叶子节点存储键值和数据,并且叶子节点之间是链式环结构。与B树相比,上层节点可以存储更多的数据,且叶子节点的范围查询或分页查询效率更高。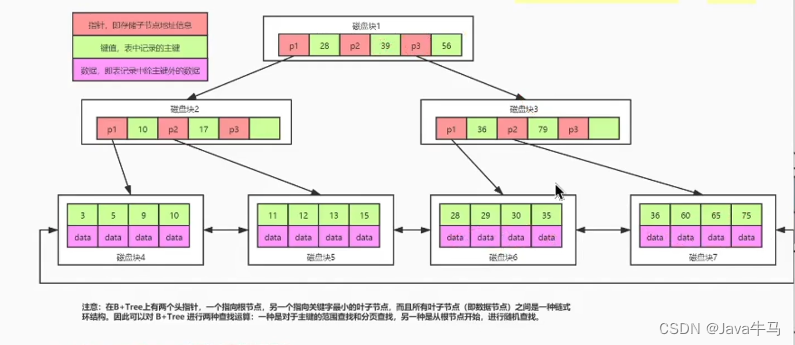
那么,三层的B+树能存储多少条数据呐?分析:
指针和键值的大小肯定远小于数据的大小,假设指针+键值占用10Byte,innodb默认页的大小是16k,那么第一层磁盘块能存储的指针+键值就是16 * 1024 / 10 = 1600(约等于),假设第一层1600个 指针 指向第二层1600个子节点,第二层的每个子节点一样至多存储指针+键值16 * 1024 / 10 = 1600(约等于),那么第二层总共存储的指针+键值总数就是 1600 * 1600,第三层假设只存储数据,每条数据1k,每个节点至多可以存储16条数据,第二层的1600 * 1600个指针对应第三层的1600 * 1600个子节点,那合起来就是 1600 * 1600 * 16 = 4096 0000条数据;
不同的数据类型,肯定会影响存储的数据量,一般结论是:
3层B+树大概可以存:
主键为bigint:约2000w
主键为int:约4000w因此,与B树相比,B+树显然可以存储更多的数据量;
5. 问题总结:
-
- 一般innodb索引层数有几层?
解析:
一般情况下,3-4层,因为3-4层的B+树足以支撑千万级别的数据存储;
- 一般innodb索引层数有几层?
-
- 索引列的键(key)值怎么选?
解析:
innodb非叶子节点的存储是 指针+键值,指针一般变化不大,所以索引列要尽可能选择占用空间小的字段,因为占用越小,单个节点能存储的 指针+键值 自然就更多,存储的数据自然就更多。
- 索引列的键(key)值怎么选?
-
- 创建表的时候,主键是否需要自增?
解析:
需要,因为如果不自增,会带来索引维护成本的提高,造成叶分裂,而自增只需要在后面有序排列,因此,在满足业务场景的前提下,能自增尽量设置成自增;
- 创建表的时候,主键是否需要自增?
-
- 一张表可以有多少个索引?
解析:
理论上来说没有索引个数的限制,但并不是索引越多越好。
- 一张表可以有多少个索引?
-
- 一个索引对应一棵树还是多个索引对应多棵树?
解析:
一个索引一棵树
- 一个索引对应一棵树还是多个索引对应多棵树?
-
- 索引的叶子节点要存放数据,当多个索引存在的时候,数据放几份?
解析:
一份
- 索引的叶子节点要存放数据,当多个索引存在的时候,数据放几份?
-
- 如果数据存储一份,其他索引的叶子节点存储什么数据?
解析:
官方文档写的是 primary key,翻译过来的话是 主键,但是回答 聚簇索引的列值 更为准确;
因为,在innodb的存储引擎中,mysql在数据插入的时候,必须要选择某一个索引列绑定在一起,如果有主键,选择主键,如果没有主键,就会选择唯一键,如果没有唯一键,那么mysql会自动生成一个6字节的rowId来进行存储。
- 如果数据存储一份,其他索引的叶子节点存储什么数据?
聚簇索引:跟数据绑定存储的称之为聚簇索引;
非聚簇索引:没有跟数据绑定存储的称之为非聚簇索引;
如:
一个表中有 id,name, age, gender, address等字段,其中id为主键,name为普通索引;
那么,id就是聚簇索引,name就是非聚簇索引。 -
-
相关阅读:
matlab判断下列级数的收敛性
【Docker】三、docker网络通信机制
Unity编辑扩展:功能篇之Json数据编辑器
开源视频监控服务器Shinobi
网络安全行业需要工匠精神吗?
06-散列(Hash)基础分析
dreamweaver家乡主题网页设计 DIV布局个人介绍网页模板代码 DW学生个人网站制作成品下载 HTML5期末大作业
安科瑞微电网智慧能源平台【能源规划、协调控制、经济运行】
掌控变量(C语言变量初步详解)
Transformer12
- 原文地址:https://blog.csdn.net/weixin_44958006/article/details/133612870