-
反爬虫机制与反爬虫技术(一)
1、网络爬虫的法律与道德问题
网络爬虫在使用过程中需要注意法律和道德问题。以下是一些常见的问题:
- 合法性: 爬虫的行为必须遵守相关法律法规,尊重网站的隐私权和知识产权。不得未经授权地访问和抓取受保护的网页内容
- 访问频率: 爬虫应该合理设置访问频率,避免对网站服务器造成过大负载或影响其他用户的正常访问
- 数据使用: 抓取到的数据应该按照法律和道德准则进行合法和合理的使用,遵守数据保护和隐私规定
在使用网络爬虫时,应当遵守相关规定并尊重网站的权益和用户的隐私
2、反爬虫机制与反爬虫技术
2.1、User-Agent伪装
User-Agent能够通过服务器识别出用户的操作系统及版本、CPU类型、浏览器类型及版本等
一些网站会根据请求头中的Referer和User-Agent信息来判断请求的合法性。部分网站会设置User-Agent白名单,只有在白名单范围内的请求才可以正常访问
因此,在我们爬虫时,需要设置User-Agent伪装成一个浏览器HTTP请求,通过修改User-Agent,可以模拟不同的浏览器或设备发送请求,从而绕过一些简单的反爬虫机制
Referer是HTTP请求头中的一个字段,用于指示请求的来源页面。当Referer为空或不符合预期值时,网站可能会拒绝请求或返回错误的数据
Referer一般指定为爬取网站的主页地址
2.2、代理IP
一些网站通常会根据IP地址来判断请求的合法性,如果同一个IP地址频繁请求,就会被认为是爬虫。使用IP代理可以隐藏真实的IP地址,轮流使用多个IP地址发送请求,可以增加爬虫的隐匿性
代理IP是指通过中间服务器转发网络请求的技术。在爬虫中,使用代理IP可以隐藏真实的访问源,防止被目标网站封禁或限制访问
代理分为正向代理和反向代理。正向代理是由客户端主动使用代理服务器来访问目标网站,反向代理是目标网站使用代理服务器来处理客户端的请求
代理IP的优缺点有:
- 优点:
- 隐藏真实的访问源,保护个人或机构的隐私和安全
- 绕过目标网站的访问限制,如IP封禁、地区限制等
- 分散访问压力,提高爬取效率和稳定性
- 收集不同地区或代理服务器上的数据,用于数据分析和对比
- 缺点:
- 代理IP的质量参差不齐,有些代理服务器可能不稳定、速度慢或存在安全风险
- 一些目标网站会检测和封禁常用的代理IP,需要不断更换和验证代理IP的可用性
- 使用代理IP可能增加网络请求的延迟和复杂性,需要合理配置和调整爬虫程序
- 使用代理IP需要遵守相关法律法规和目标网站的使用规则,不得进行非法活动或滥用代理IP服务
亮数据代理IP:https://www.bright.cn/locations
2.3、请求频率控制
频繁的请求会给网站带来较大的负担,并影响网站的正常运行,因此,网站通常会设置请求频率限制。Python中的time库可以用来控制请求的时间间隔,避免过于频繁的请求
2.4、动态页面处理
一些网站为了防止爬虫,使用了JavaScript来动态生成页面内容,这对于爬虫来说是一个挑战。Python中的Selenium库可以模拟浏览器的行为,执行JavaScript代码,从而获取动态生成的内容
例如在进行数据采集时,很多网站需要进行登录才能获取到目标数据,这时可以使用Selenium库进行模拟登录进行处理
2.5、验证码识别
一些网站为了防止爬虫,会在登录或提交表单时添加验证码。随着反爬的不断发展,逐渐出现了更多复杂的验证码,例如:内容验证码、滑动验证码、图片拼接验证码等
Python提供了一些强大的图像处理库,例如Pillow、OpenCV等,可以用来自动识别验证码,从而实现自动化爬取
3、反爬虫案例:豆瓣电影Top250爬取
本案例将使用User-Agent伪装、代理IP、请求频率控制反爬虫技术,动态页面处理和验证码识别将在后续的文章中使用
动态页面处理与验证码识别见文章:反爬虫机制与反爬虫技术(二)
3.1、爬取目标
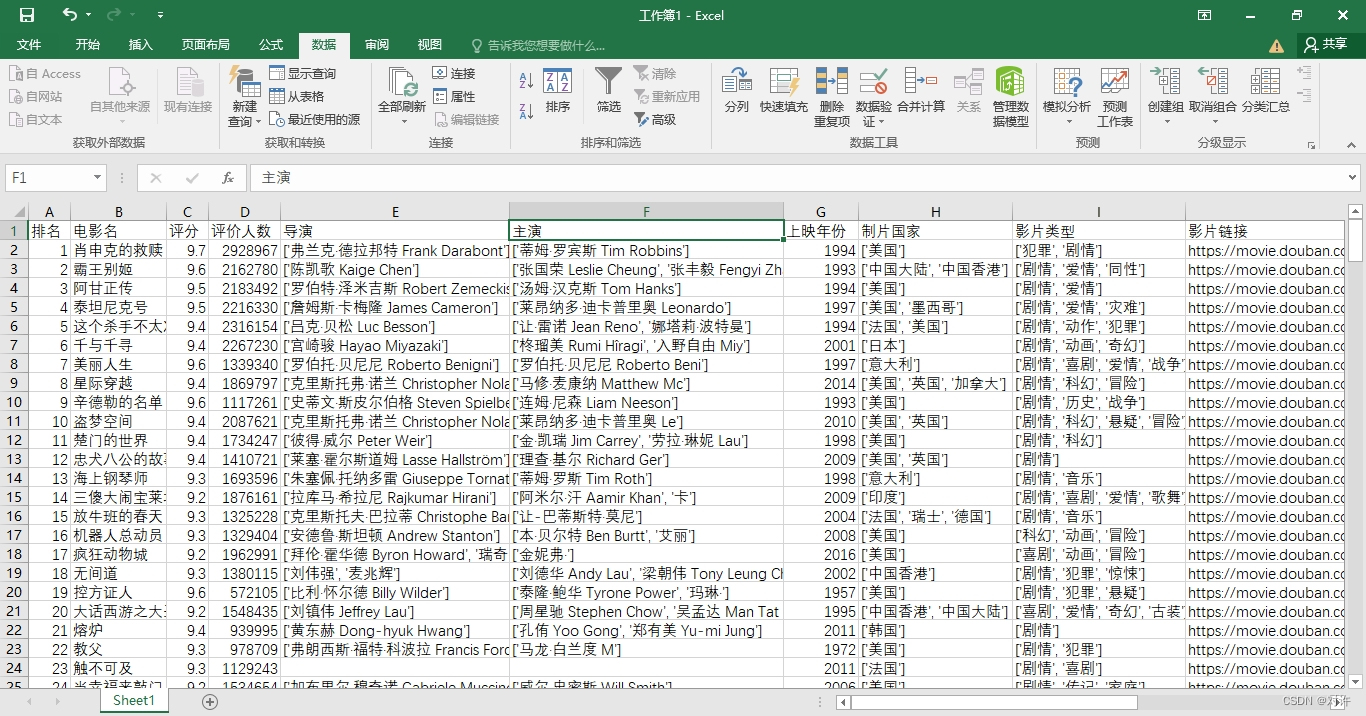
爬取目标: 豆瓣电影Top250排行榜
爬取字段: 排名、电影名、评分、评价人数、制片国家、电影类型、上映时间、主演、影片链接
效果展示:
豆瓣电影:https://movie.douban.com/
豆瓣电影Top250:https://movie.douban.com/top250
3.2、库(模块)简介
import numpy as np import pandas as pd import requests from bs4 import BeautifulSoup from lxml import etree import re import time- 1
- 2
- 3
- 4
- 5
- 6
- 7
相关模块的详细介绍及使用见文章:Python网络爬虫基本库
3.3、翻页分析

通过观察浏览器地址栏,发现页面间网址存在如下规律:第1页:https://movie.douban.com/top250?start=0&filter=
第2页:https://movie.douban.com/top250?start=25&filter=
第3页:https://movie.douban.com/top250?start=50&filter=
… …
# 构造每页的网页链接 urls = [rf'https://movie.douban.com/top250?start={ str(i * 25)}&filter=' for i in range(10)]- 1
- 2
- 3
3.4、发送请求
def get_html_str(url: str): # 请求头模拟浏览器 headers = { 'User-Agent': 'Mozilla/5.0', 'Referer': 'https://www.douban.com'} # 代理IP proxies = { "http": "http://183.134.17.12:9181"} # 发送请求- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
相关阅读:
亚马逊婴儿摇椅ASTMF2167-19标准测试,儿童CPC认证
sparksql的SQL风格编程
kubernetes pod podsecurityPolicies(PSP)
杂谈 跟编程无关的事情21
现代 CSS 解决方案:数学函数 Round
739. 每日温度【单调栈】
21天经典算法之直接插入排序
Servlet -个人理解笔记
VB.net:VB.net编程语言学习之基于VS软件利用VB.net语言实现对SolidWorks进行二次开发的简介、案例应用之详细攻略
全球产业链:脑机接口产业链
- 原文地址:https://blog.csdn.net/weixin_55629186/article/details/133611980