-
Unicode与UTF-8
软件开发中乱码问题经常遇到,Unicode,UTF-8, ASCII等都是高频词语,不过具体是啥意思其实都不清楚。这个周末研究了一下,略有了解,记录一下。
Unicode
Unicode本身是纯理论的东西,和具体计算机实现无关。它就是要给全世界的文字符号进行统一的编码。注意,是所有的文字符号,也就是除了正常的各国文字外,还包括包括了各式各样的符号,这样的话,理论上符号的数量是无上限的,虽然目前已经编码的符号还是有限的。
比如:英文字母
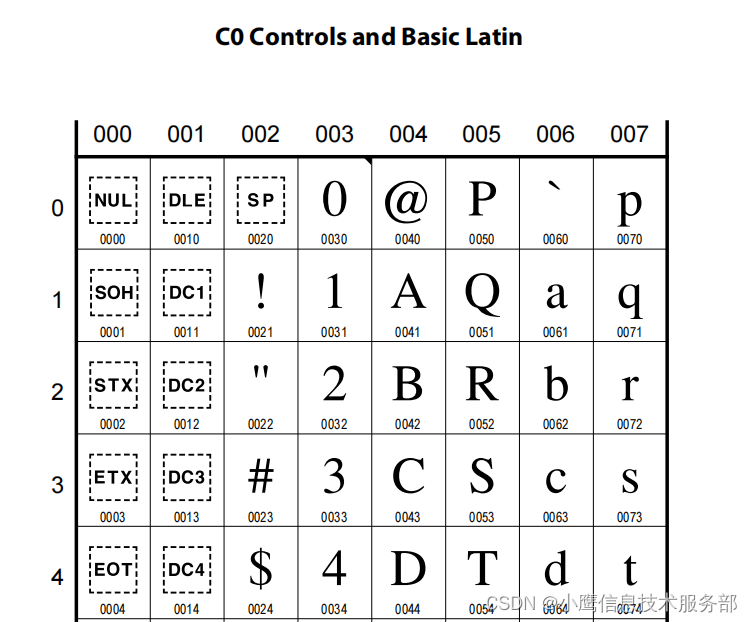
比如:汉字

比如:象棋相关

任何一个文字符号都有一个自己的编码,或者数字,称为“代码点(Code Point)”, 表示方法为:
U+XXXX
例如字母A的代码点是U+0041. 再次注意,目前为止这都是还是纯理论,和具体计算机无关。
按此,所有的字符及其Unicode编码构成的集合就叫Unicode字符集(Unicode Charactor Set, UCS)。
早期的版本有UCS-2, 用两个字节(BYTE)编码,最多能表示65535个字符。每个代码点的长度是16位。
后来UCS-2不够用了,因此出了UCS-4版本。UCS-4增加了两个字节,采用4个字节编码(最高位固定为0,因此实际用31位。UCS-4在结构上有一个分层关系,大致如下:
第一层:组(Group)
用最高字节分成 128组(最高字节的最高位固定为0,所以最高字节有128个)
第二层:平面(Plane)
对于每个组,再用次高字节分为256个平面
第三层:行(Row) / 码位(Cell)
对于每个平面,根据第三个字节分为256行,根据第四个字节分为256个码位。
总结如下图:

UCS-4中还有一些规定比如BMP,PUA之类的概念这里就不作记录了。
以上都是纯理论的部分,没有设计Unicode在计算机中的实现。需要注意的是,Unicode的实现方式和编码方式不一定等价。一个 字符的Unicode编码是确定 的,但在实际存储和传输过程中,不同的系统平台设计可能是不一致的,还有处于节省空间的目的 ,对Unicode编码的实现方式也可能不同。
UTF
Unicode编码的实现方式,称为Unicode转换格式(Unicode Transformation Format),简称UTF, 到这里,UTF这次词出现了,离日常接触的内容就比较近了。Unicode实现方式主要有UTF-8、UTF-16、UTF-32等,分别以不同的字节数作为编码单位:
UTF-8: 字节(BYTE,1个字节)
UTF-16: 字(WORD,2个字节)
UTF-16: 双字(DWORD, 4个 字节)
看到BYTE/WORD/DWORD这些 词,就能联想到一些具体的点了,例如注册表中的值,例如 C++中的数据类型。
UTF-8
下面记录一下UTF-8的具体实现:
UTF-8以字节为单位对Unicode进行编码,这里的单位是指程序在解析二进制流时的最小单元,在UTF-8中,程序是以一个字节一个字节地解析文本。UTF-8具体实现如下:
Unicde编码(Hex)所处范围
UTF-8字节流(Binary)
000000 ~ 00007F
0xxxxxxx
000080 ~ 0007FF
110xxxxx 10xxxxxx
000800 ~ 00FFFF
1110xxxx 10xxxxxx 10xxxxxx
010000 ~ 10FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
从表格可以看出,UTF-8的特点是对不同范围的字符(也就是Unicode码点)使用不同长度的编码。
对于码点在0x00 ~ 0x7F的字符,UTF-8与ASCII编码相同。UTF-8编码的最大长度是4个字节,4字节模板有21个x, 也就是可以容纳21位二进制数。同时,Unicode的最大码点0x10FFFF也只有21位。
举例:中文字符 "电",怎样从Unicode实现为UTF-8?
查询得知,"电"的Unicde码是0x7535 (在线 Unicode 编码转换 | 菜鸟工具)
0x7535落在000800 ~ 00FFFF这个范围 ,也就是表格 第三行,使用三字节模板:
1110xxxx 10xxxxxx 10xxxxxx
0x7535写成二进制是 0111010100110101, 根据模板分一下组就是:
0111 010100 110101, 填入模板:
11100111 10010100 10110101,写成十六进制就是:
E7 94 B5,用工具验证一下:
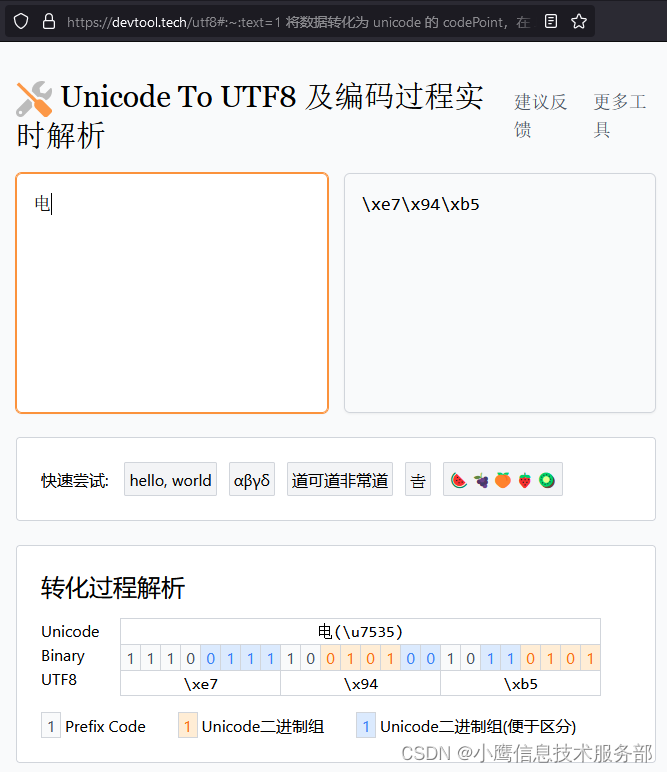
正确。
好了,Unicode与UTF-8的学习暂时告一段落。
-
相关阅读:
30天Python入门(第十四天:深入了解Python中的高阶函数))
Flutter Android & IOS 获取通讯录联系人列表
ubuntu中,执行arm-linux-gcc 出现 命令未找到的解决办法,本人亲测有效,可以尝试!!!!!
ASP.NET Core - 依赖注入(三)
大数据Flink(九十八):SQL函数的归类和引用方式
rpm打包新手入门
未在本地计算机上注册“Microsoft .ACE. OLEDB .12.0”提供程序
java第二讲:运算符与流程控制
【Java进阶】学好常用类,code省时省力(一)
电脑数据恢复软件分享,需要的快收藏
- 原文地址:https://blog.csdn.net/zhouyingge1104/article/details/133246758