-
Transformer学习
这里写目录标题
Seq2Seq

语音翻译为何不直接用语音辨识+机器翻译?
因为有的语言没有文字,比如将狗叫翻译出来。
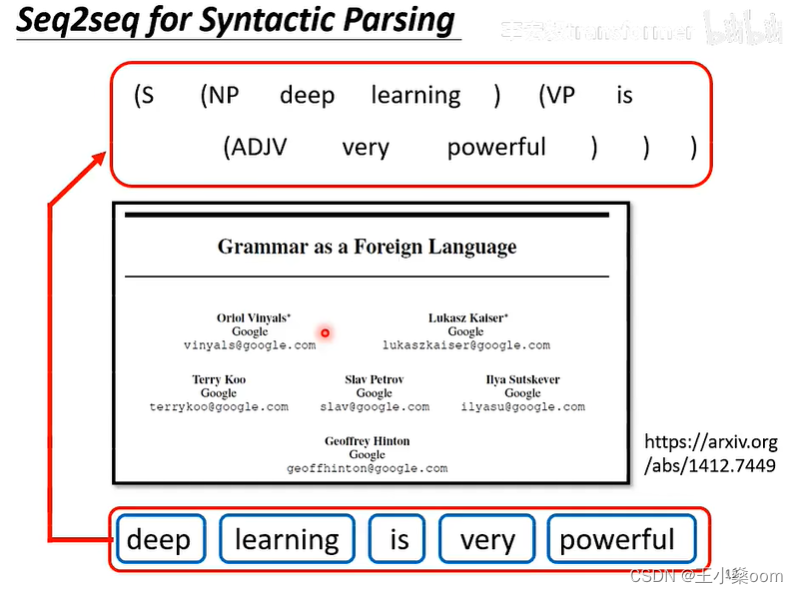
语法分析
将任务转化成翻译任务,硬训一发,效果不错。
文章归类问题

目标检测

Transformer
Encoder结构

multi-head attention block
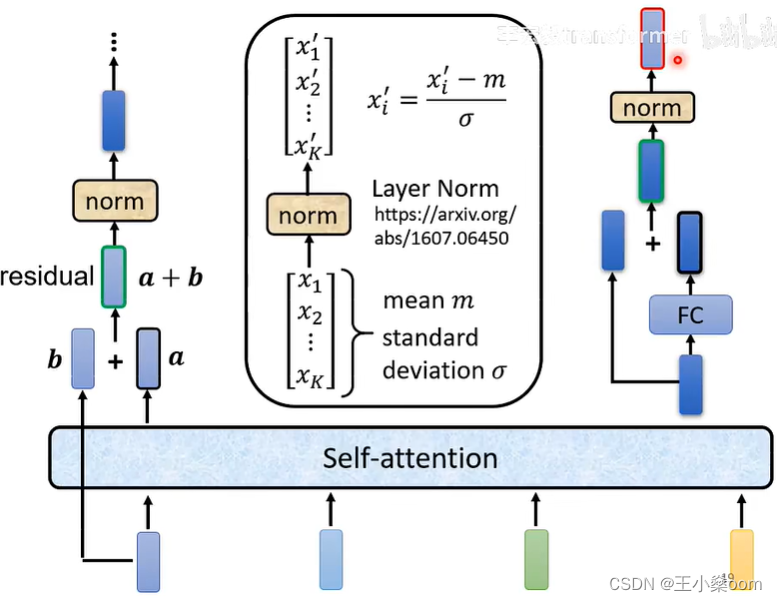
为何batch-norm 不如 layer-norm?
https://arxiv.org/abs/2003.07845
https://zhuanlan.zhihu.com/p/428620330Decoder结构
decoder流程

decoder结构
encoder和decoder基本一样,decoder多了一个masked mutil-head attention

decoder比encoder多了一个masked self-attention,why?
因为decoder计算每次都依赖前一个节点的输出,所以a_n只能看到1~n个节点的输出

decoder如何决定自己输出的长度?
增加一个停止token,一般来会跟begin用一个符号

Decoder-Non-autoregressive(NAT)

NAT decoder如何决定输出长度?
- 训练一个分类器用来预测输出长度
- 输出一个固定的较长的长度,通过END tocken来截取最终输出
优势
- AT decoder需要一个一个输出,NAT可以一次输出整个
- 较容易控制输出长度,比如在语音合成的应用
劣势
NAT的表现通常不如AT。原因:multi-modality
Transformer结构

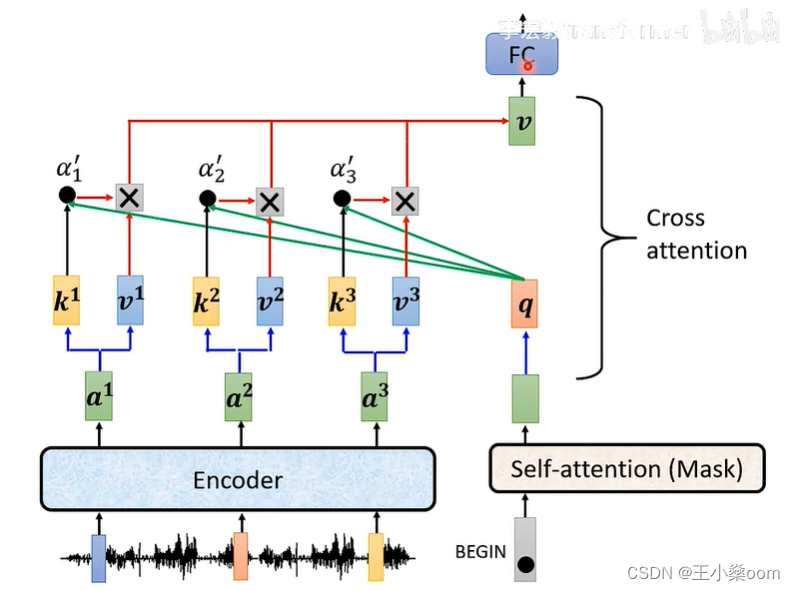
cross attention
训练
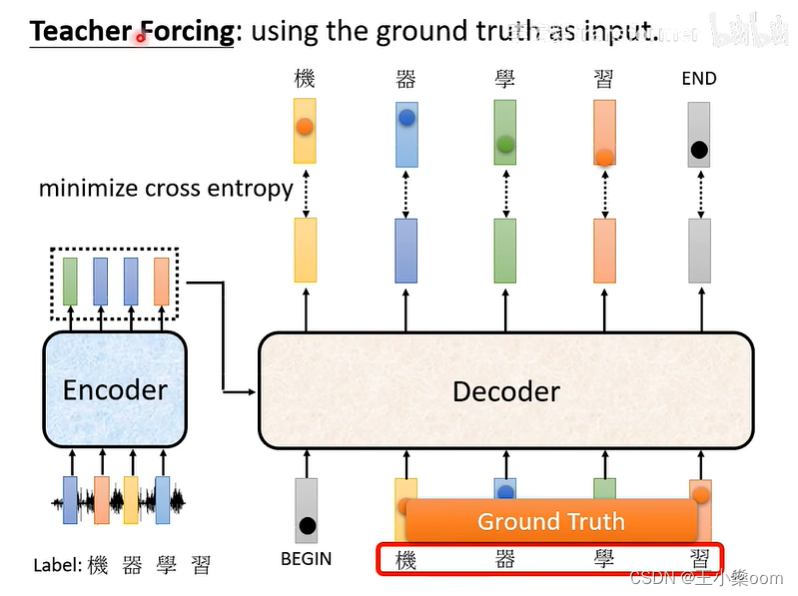
训练和测试的区别

Bert为何不适合文本生成任务
作者:山河动人
链接:https://www.zhihu.com/question/450039091/answer/2952680112
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。1.“Fine-tuning Language Models from Human Preferences” by Zhang et al. (2019):该论文指出,BERT的生成速度相对较慢,并且由于是自回归模型,无法一次生成多个词,这使得在一些生成任务中,BERT的效率可能不如一些并行的生成模型。
2.“Domain Adaptive Text Generation Through Self-Supervision” by Li et al. (2020):该论文指出,BERT是在大规模无监督数据上进行预训练的,因此在生成任务中可能无法捕捉到一些特定领域或任务的细微差异。
3.“Assessing the Ability of Transformer-Based Language Models to Generate Contextually Relevant Text” by Hossain et al. (2020):该论文指出,BERT的生成质量取决于输入的上下文,因此在输入上下文较少或不完整的情况下,它可能无法产生合理的生成结果。
4.“Text Generation with Exponential Memory Self-Attention” by Grave et al. (2019):该论文指出,BERT缺乏对生成任务中先前生成的单词的记忆,因此在生成长文本时,可能会出现不连贯的问题。该论文提出了一种新的自注意力机制,能够在一定程度上解决这个问题。
5.BERT在生成任务中表现欠佳的限制:Zhang, X., Han, X., Huang, T., & Liu, X. (2021). On the Weaknesses of the Transformer-XL Language Model for Data-to-Text Generation. arXiv preprint arXiv:2106.06238.
虽然BERT可以用于一些生成任务,但对于一些需要产生连贯、长文本的生成任务,可能需要更加专门化的生成模型来取代BERT。 -
相关阅读:
rabbitmq代码
web概述08
判断非线性负载是否合格的方法可以从以下几个方面进行考虑:
微信小程序ios下,border显示不全兼容问题解决
复盘:细数这些年写文字的成与败
基于SSM的超市会员管理系统
【vim 学习系列文章 12 -- vimrc 那点事】
进销存软件对中小型企业管理有什么作用?
中级工程师职称评审中业绩材料具体有哪些呢?甘建二告诉你
如何向客户推广 API 商品数据接口,如何跟进项目和程序员对接?
- 原文地址:https://blog.csdn.net/Ives_WangShen/article/details/133574731