-
YOLOv5、YOLOv8改进:RepVGG结构
1.简介
论文参考:最新RepVGG结构: Paper
我们所说的“VGG式”指的是:
-
没有任何分支结构。即通常所说的plain或feed-forward架构。
-
仅使用3x3卷积。
-
仅使用ReLU作为激活函数。

主要创新点为结构重参数化。在训练时,网络的结构是多分支进行的,而在推理时则将分支的参数进行重参数化,合为一个分支来进行的,所以推理的速度要比多分支网络快很多,并且精度也比单分支的网络更高。
1.1 RepVGG Block
整个RepVGG网络结构很简单,就是不断地堆叠RepVGG Block,所以了解了RepVGG Block就基本了解了整个RepVGG网络结构。下图中,左图为stride=2进行下采样时的RepVGG Block结构,右图为stride=1时的RepVGG Block结构。可以看到一般不进行下采样时,RepVGG Block有三个分支,分别是卷积核为3x3的主分支、卷积核为1x1的shortcut分支和只含BN层的shortcut分支。

这里有几个问题,
一、为什么多分支结构的精度会比单分支高?
二、为什么单分支结构会比多分支结构速度快了将近一倍?
先来说第一个问题,为什么多分支结构的精度会比单分支高?因为之前的模型像Inception系列、ResNet以及DenseNet等模型,我们能够发现这些模型都并行了多个分支。至少根据现有的一些经验来看,并行多个分支一般能够增加模型的表征能力。在论文的表6中,作者也做了个简单的消融实验,证明了增加分支是能够提升精度的。

接着是第二个问题,为什么单分支结构会比多分支结构速度快了将近一倍?根据论文
3.1章节的内容可知,采用单路模型会更快、更省内存并且更加的灵活。更快:主要是考虑到模型在推理时硬件计算的并行程度以及MAC(memory access cost),对于多分支模型,硬件需要分别计算每个分支的结果,有的分支计算的快,有的分支计算的慢,而计算快的分支计算完后只能干等着,等其他分支都计算完后才能做进一步融合,这样会导致硬件算力不能充分利用,或者说并行度不够高。而且每个分支都需要去访问一次内存,计算完后还需要将计算结果存入内存(不断地访问和写入内存会在IO上浪费很多时间)。
但是这里的说法又有一个问题,在结构重参数化之前,最耗时的是3x3卷积的时间,1x1卷积和恒等映射的时间比较短,需要等3x3的卷积时间结束之后,才继续走下一个模块,所以应该可以理解成,重参数化之前的时间其实就是一个3x3卷积操作的时间加上三个分支融合的时间呢?然而在重参数化之后,3x3卷积还是存在的,所以总的时间还是3x3卷积的时间,也就是说,结构重参数化之后所节省的时间仅仅只是一个三分支融合的时间,但是为什么最后的结果却节省了将近一倍的时间,这里不太理解。

更省内存:在论文的图3当中,作者举了个例子,如图(A)所示的Residual模块,假设卷积层不改变channel的数量,那么在主分支和shortcut分支上都要保存各自的特征图或者称Activation,那么在add操作前占用的内存大概是输入Activation的两倍,而图(B)的Plain结构占用内存始终不变。
更加灵活:作者在论文中提到了模型优化的剪枝问题,对于多分支的模型,结构限制较多剪枝很麻烦,而对于Plain结构的模型就相对灵活很多,剪枝也更加方便。
除此之外,在多分支转化成单路模型后很多算子进行了融合(比如Conv2d和BN融合),使得计算量变小了,而且算子减少后启动kernel的次数也减少了(比如在GPU中,每次执行一个算子就要启动一次kernel,启动kernel也需要消耗时间)。而且现在的硬件一般对3x3的卷积操作做了大量的优化,转成单路模型后采用的都是3x3卷积,这样也能进一步加速推理。
1.2结构重参数化
在了解了RepVGG Block后就到了这篇文章最重要的、也是最核心的部分,结构重参数化。也就是如何将三个分支的内容最后融合到一个主分支当中。
这个过程主要分为两步,
一、将三个分支中的卷积算子和BN算子都融合为卷积算子(一个卷积核加一个偏置的形式)
二、将三个分支上的卷积算子都化为3x3卷积核和偏置的形式,相加得到最终的主分支上的结果。
下图就能完美体现这两个过程融合Conv2d和BN,将三个分支上的卷积算子和BN算子都转化为卷积算子(包括卷积核和偏置)
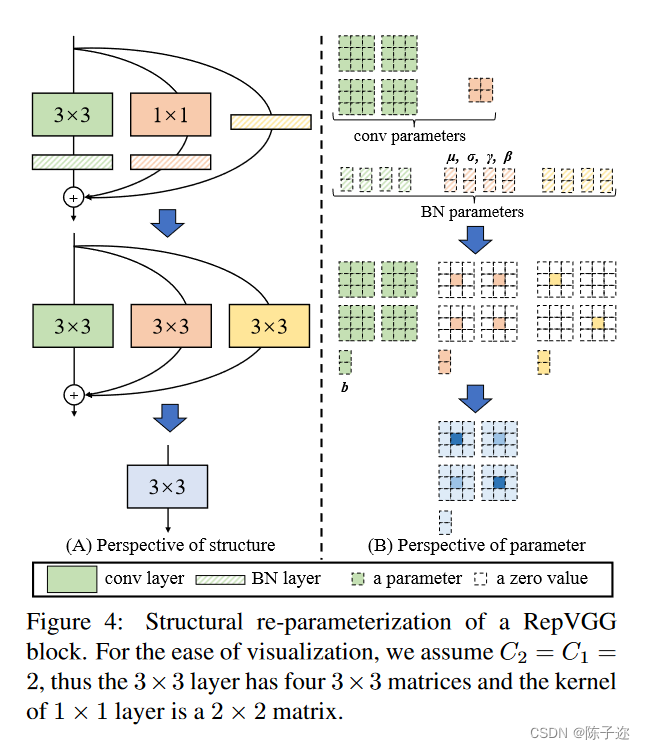
因为Conv2d和BN两个算子都是做线性运算,所以可以融合成一个算子。如果不了解卷积层的计算过程以及BN的计算过程的话建议先了解后再看该部分的内容。这里还需要强调一点,融合是在网络训练完之后做的,所以现在讲的默认都是推理模式,注意BN在训练以及推理时计算方式是不同的。
2.在YOLOv7中加入RepVGG模块
2.1YOLOv7的yaml配置文件
- 代码
- # YOLOv7 🚀, GPL-3.0 license
- # parameters
- nc: 80 # number of classes
- depth_multiple: 0.33 # model depth multiple
- width_multiple: 1.0 # layer channel multiple
- # anchors
- anchors:
- - [12,16, 19,36, 40,28] # P3/8
- - [36,75, 76,55, 72,146] # P4/16
- - [142,110, 192,243, 459,401] # P5/32
- # yolov7 backbone by yoloair
- backbone:
- # [from, number, module, args]
- [[-1, 1, Conv, [32, 3, 1]], # 0
- [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
- [-1, 1, Conv, [64, 3, 1]],
- [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
- [-1, 1, RepVGGBlock, [128, 3, 2]], # 5-P4/16
- [-1, 1, Conv, [256, 3, 2]],
- [-1, 1, MP, []],
- [-1, 1, Conv, [128, 1, 1]],
- [-3, 1, Conv, [128, 1, 1]],
- [-1, 1, Conv, [128, 3, 2]],
- [[-1, -3], 1, Concat, [1]], # 16-P3/8
- [-1, 1, Conv, [128, 1, 1]],
- [-2, 1, Conv, [128, 1, 1]],
- [-1, 1, Conv, [128, 3, 1]],
- [-1, 1, Conv, [128, 3, 1]],
- [-1, 1, Conv, [128, 3, 1]],
- [-1, 1, Conv, [128, 3, 1]],
- [[-1, -3, -5, -6], 1, Concat, [1]],
- [-1, 1, Conv, [512, 1, 1]],
- [-1, 1, MP, []],
- [-1, 1, Conv, [256, 1, 1]],
- [-3, 1, Conv, [256, 1, 1]],
- [-1, 1, Conv, [256, 3, 2]],
- [[-1, -3], 1, Concat, [1]],
- [-1, 1, Conv, [256, 1, 1]],
- [-2, 1, Conv, [256, 1, 1]],
- [-1, 1, Conv, [256, 3, 1]],
- [-1, 1, Conv, [256, 3, 1]],
- [-1, 1, Conv, [256, 3, 1]],
- [-1, 1, Conv, [256, 3, 1]],
- [[-1, -3, -5, -6], 1, Concat, [1]],
- [-1, 1, Conv, [1024, 1, 1]],
- [-1, 1, MP, []],
- [-1, 1, Conv, [512, 1, 1]],
- [-3, 1, Conv, [512, 1, 1]],
- [-1, 1, Conv, [512, 3, 2]],
- [[-1, -3], 1, Concat, [1]],
- [-1, 1, C3C2, [1024]],
- [-1, 1, Conv, [256, 3, 1]],
- ]
- # yolov7 head by yoloair
- head:
- [[-1, 1, SPPCSPC, [512]],
- [-1, 1, Conv, [256, 1, 1]],
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [31, 1, Conv, [256, 1, 1]],
- [[-1, -2], 1, Concat, [1]],
- [-1, 1, C3C2, [128]],
- [-1, 1, Conv, [128, 1, 1]],
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [18, 1, Conv, [128, 1, 1]],
- [[-1, -2], 1, Concat, [1]],
- [-1, 1, C3C2, [128]],
- [-1, 1, MP, []],
- [-1, 1, Conv, [128, 1, 1]],
- [-3, 1, Conv, [128, 1, 1]],
- [-1, 1, Conv, [128, 3, 2]],
- [[-1, -3, 44], 1, Concat, [1]],
- [-1, 1, C3C2, [256]],
- [-1, 1, MP, []],
- [-1, 1, Conv, [256, 1, 1]],
- [-3, 1, Conv, [256, 1, 1]],
- [-1, 1, Conv, [256, 3, 2]],
- [[-1, -3, 39], 1, Concat, [1]],
- [-1, 3, C3C2, [512]],
- # 检测头 -----------------------------
- [49, 1, RepConv, [256, 3, 1]],
- [55, 1, RepConv, [512, 3, 1]],
- [61, 1, RepConv, [1024, 3, 1]],
- [[62,63,64], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
- ]
2.2 common.py配置
在./models/common.py文件中增加以下模块,直接复制即可
- class RepVGGBlock(nn.Module):
- def __init__(self, in_channels, out_channels, kernel_size=3,
- stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
- super(RepVGGBlock, self).__init__()
- self.deploy = deploy
- self.groups = groups
- self.in_channels = in_channels
- padding_11 = padding - kernel_size // 2
- self.nonlinearity = nn.SiLU()
- # self.nonlinearity = nn.ReLU()
- if use_se:
- self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
- else:
- self.se = nn.Identity()
- if deploy:
- self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
- stride=stride,
- padding=padding, dilation=dilation, groups=groups, bias=True,
- padding_mode=padding_mode)
- else:
- self.rbr_identity = nn.BatchNorm2d(
- num_features=in_channels) if out_channels == in_channels and stride == 1 else None
- self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
- stride=stride, padding=padding, groups=groups)
- self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
- padding=padding_11, groups=groups)
- # print('RepVGG Block, identity = ', self.rbr_identity)
- def switch_to_deploy(self):
- if hasattr(self, 'rbr_1x1'):
- kernel, bias = self.get_equivalent_kernel_bias()
- self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
- kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
- padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
- self.rbr_reparam.weight.data = kernel
- self.rbr_reparam.bias.data = bias
- for para in self.parameters():
- para.detach_()
- self.rbr_dense = self.rbr_reparam
- # self.__delattr__('rbr_dense')
- self.__delattr__('rbr_1x1')
- if hasattr(self, 'rbr_identity'):
- self.__delattr__('rbr_identity')
- if hasattr(self, 'id_tensor'):
- self.__delattr__('id_tensor')
- self.deploy = True
- def get_equivalent_kernel_bias(self):
- kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
- kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
- kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
- return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
- def _pad_1x1_to_3x3_tensor(self, kernel1x1):
- if kernel1x1 is None:
- return 0
- else:
- return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
- def _fuse_bn_tensor(self, branch):
- if branch is None:
- return 0, 0
- if isinstance(branch, nn.Sequential):
- kernel = branch.conv.weight
- running_mean = branch.bn.running_mean
- running_var = branch.bn.running_var
- gamma = branch.bn.weight
- beta = branch.bn.bias
- eps = branch.bn.eps
- else:
- assert isinstance(branch, nn.BatchNorm2d)
- if not hasattr(self, 'id_tensor'):
- input_dim = self.in_channels // self.groups
- kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
- for i in range(self.in_channels):
- kernel_value[i, i % input_dim, 1, 1] = 1
- self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
- kernel = self.id_tensor
- running_mean = branch.running_mean
- running_var = branch.running_var
- gamma = branch.weight
- beta = branch.bias
- eps = branch.eps
- std = (running_var + eps).sqrt()
- t = (gamma / std).reshape(-1, 1, 1, 1)
- return kernel * t, beta - running_mean * gamma / std
- def forward(self, inputs):
- if self.deploy:
- return self.nonlinearity(self.rbr_dense(inputs))
- if hasattr(self, 'rbr_reparam'):
- return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
- if self.rbr_identity is None:
- id_out = 0
- else:
- id_out = self.rbr_identity(inputs)
- return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
其中缺少的C3C2模块看本专栏相关文章,你也可以改回原来的模块
2.3 yolo.py配置
然后找到./models/yolo.py文件下里的parse_model函数,将类名加入进去
在 models/yolo.py文件夹下- parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要增加
RepVGGBlock模块
- elif m is RepVGGBlock:
- c1, c2 = ch[f], args[0]
- if c2 != no: # if not output
- c2 = make_divisible(c2 * gw, 8)
- args = [c1, c2, *args[1:]]
-
-
相关阅读:
数据库基础篇一
MybatisPlus常用插件
【ES6.0】- 扩展运算符(...)
Spring AOP浅谈
剑指offer(C++)-JZ38:字符串的排列(算法-搜索算法)
深入探究Spring自动配置原理及SPI机制:实现灵活的插件化开发
【无标题】
ansible清单文件的配置方法、配置文件的配置、临时命令的用法
使用Element进行前端开发
【LWM2M协议传输ADC到ONENET移动云】
- 原文地址:https://blog.csdn.net/weixin_45303602/article/details/133563341