1、首先,导入所需的库和模块,包括NumPy、PyTorch、MNIST数据集、数据处理工具、模型层、优化器、损失函数、混淆矩阵、绘图工具以及数据处理工具。
from torchvision.datasets import mnist
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
2、设置超参数,包括训练批次大小、测试批次大小、学习率和训练周期数。
3、创建数据转换管道,将图像数据转换为张量并进行标准化。
transform = transforms.Compose([
transforms.Normalize([0.5], [0.5])
4、下载和预处理MNIST数据集,分为训练集和测试集。
train_dataset = mnist.MNIST('data', train=True, transform=transform, download=True)
test_dataset = mnist.MNIST('data', train=False, transform=transform)
5、创建用于训练和测试的数据加载器,以便有效地加载数据。
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)
6、定义了一个简单的CNN模型,包括两个卷积层和两个全连接层。
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5)
self.fc1 = nn.Linear(1024, 256)
self.fc2 = nn.Linear(256, 10)
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(x.size(0), -1)
return F.log_softmax(x, dim=1)
7、初始化模型、优化器和损失函数。
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
8、准备用于记录训练和测试过程中损失和准确率的列表。
9、进入训练循环,遍历每个训练周期。在每个训练周期内,进入训练模式,遍历训练数据批次,计算损失、反向传播并更新模型参数,同时记录训练损失和准确率。
for epoch in range(num_epochs):
for batch_idx, (data, target) in enumerate(train_loader):
loss = criterion(output, target)
train_loss += loss.item()
_, predicted = output.max(1)
correct += predicted.eq(target).sum().item()
train_loss /= len(train_loader)
train_accuracy = 100. * correct / total
train_losses.append(train_loss)
train_accuracies.append(train_accuracy) # 记录训练准确率
for data, target in test_loader:
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
all_labels.extend(target.numpy())
all_preds.extend(pred.numpy())
10、在每个训练周期结束后,进入测试模式,遍历测试数据批次,计算测试损失和准确率,同时记录它们。打印每个周期的训练和测试损失以及准确率。
test_loss /= len(test_loader)
test_accuracy = 100. * correct / len(test_loader.dataset)
test_losses.append(test_loss)
test_accuracies.append(test_accuracy)
print(f'Epoch [{epoch + 1}/{num_epochs}] -> Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.2f}%, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.2f}%')
 11、losses、acces、eval_losses、eval_acces保存到TXT文件
11、losses、acces、eval_losses、eval_acces保存到TXT文件
data = np.column_stack((train_losses,test_losses,train_accuracies, test_accuracies))
np.savetxt("results.txt", data)
12、绘制Loss、ACC图像
plt.figure(figsize=(10, 2))
plt.plot(train_losses, label='Train Loss', color='blue')
plt.plot(test_losses, label='Test Loss', color='red')
plt.savefig('loss_curve.png')
plt.figure(figsize=(10, 2))
plt.plot(train_accuracies, label='Train Accuracy', color='red') # 绘制训练准确率曲线
plt.plot(test_accuracies, label='Test Accuracy', color='green')
plt.title('Accuracy Curve')
plt.savefig('accuracy_curve.png')


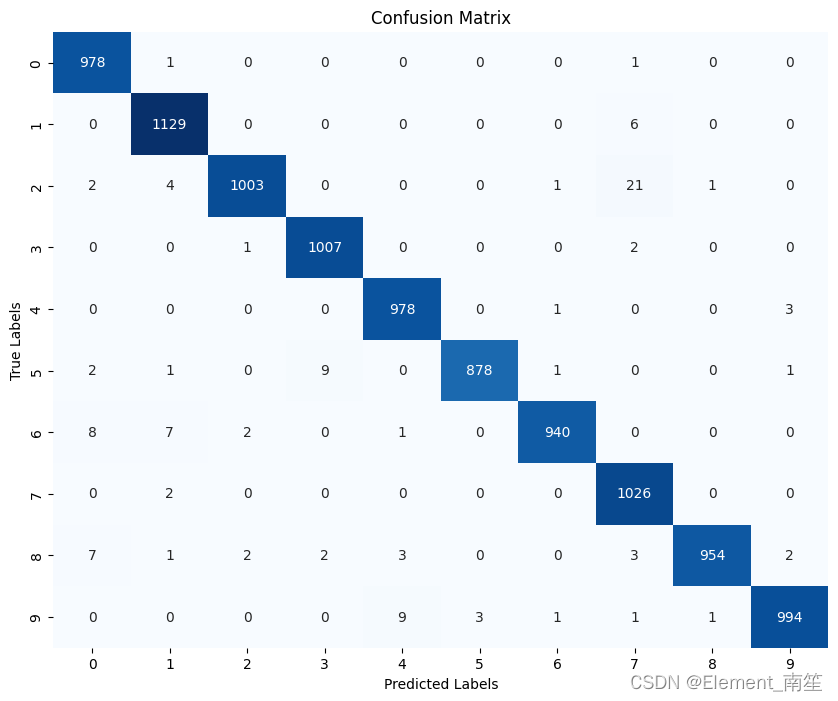
13、绘制混淆矩阵图像
confusion_mat = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mat, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.savefig('confusion_matrix.png')