-
Hive【Hive(五)函数-高级聚合函数、炸裂函数】
高级聚合函数
多进一出(多行输入,一个输出)
普通聚合函数:count、sum ...
1)collect_list():收集并形成 list 集合,结果不去重
- select sex,collect_list(job)
- from employee
- group by sex;
- --女 ["行政","研发","行政","前台"]
- --男 ["销售","研发","销售","前台"]
2)collect_set():收集并形成 set 集合,结果去重
- select sex,collect_set(job)
- from employee
- group by sex;
- --女 ["行政","研发","前台"]
- --男 ["销售","研发","前台"]
案例
1)每个月的入职人数以及姓名
- select month(replace(hire_date,'/','-')) as month,
- count(*) cnt,
- collect_list(name) as name_list
- from employee
- group by month(replace(hire_date,'/','-'));
运行结果:
- month cnt name_list
- 4 2 ["宋青书","周芷若"]
- 6 1 ["黄蓉"]
- 7 1 ["郭靖"]
- 8 2 ["张无忌","杨过"]
- 9 2 ["赵敏","小龙女"]
炸裂函数(UDTF)
接受一行数据,输出一行或多行数据。
TF(Table-Genrating Functions),表生成函数,也就是说这个函数的结果是一张表。
1、常用 UDTF - explode(array
a) explode(array
a)接受一个数组类型的参数,它会把这一个数组炸裂成一个列(多行)。 语法
- select explode(array("a","b","c"))as item;
- -- item
- -- a
- -- b
- -- c
2、 常用 UDTF - explode(Map
返回多行2列(key,value)。
语法
注意:不加别名时,它默认的字段也是 key 和 value,我们自定义多个字段名时需要加括号。
- select explode(map('hadoop','1','spark',2)) as (key,value);
- -- key value
- -- hadoop 1
- -- spark 2
3、常用 UDTF - posexplode(array
a) 接受一个数组 array ,pos 的意思是 position ,也就是数组的下标。它返回多行两列,一列为 pos(索引) ,一列是 val(值)。
- select posexplode(array('a','b','c'));
- -- pos val
- -- 0 a
- -- 1 b
- -- 2 c
4、常用 UDTF - inline(array
它接受一个 结构体数组 ,返回多行多列,列数=结构体的属性数量。
注意:每个结构体的属性数量必须一致。
- select inline(array(
- named_struct("id",1,"name","zs","age",15),
- named_struct("id",2,"name","ls","age",17),
- named_struct("id",3,"name","ww","age",23)
- )) as (id,name,age);
运行结果:
Lateral View(常用)
Lateral View 通常与UDTF 配合使用。它可以将UDTF应用到源表的每行数据,UDTF会将每行数据转换为一行或多行,Lateral View会将源表中每行的输出结果与该行连接起来,形成一个虚拟表。

数据准备
- create table movie_info(
- movie string, --电影名称
- category string --电影分类
- )
- row format delimited fields terminated by "\t";
- insert overwrite table movie_info
- values ("《疑犯追踪》", "悬疑,动作,科幻,剧情"),
- ("《Lie to me》", "悬疑,警匪,动作,心理,剧情"),
- ("《战狼2》", "战争,动作,灾难");
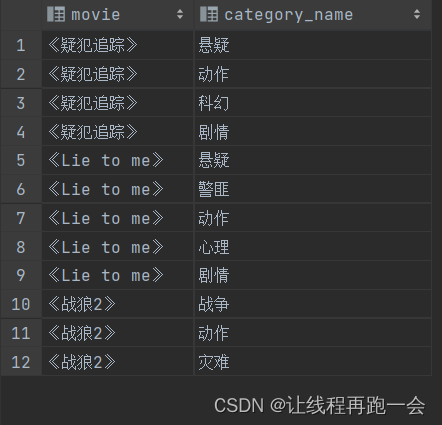
函数演示
- select
- movie,
- category_name
- from
- movie_info
- lateral view
- explode(split(category,",")) movie_info_tmp as category_name;
运行结果:
- select cate,count(*)
- from (
- select movie,cate
- from (
- select movie,
- split(category,',') cates
- from movie_info
- )t1 lateral view explode(cates) tmp as cate
- )t2
- group by cate;
运行结果:

窗口函数
明天写
-
相关阅读:
河北吉力宝以步力宝健康鞋引发的全新生活生态商
Vue3自定义指令
图像识别在自动驾驶汽车中的多传感器融合技术
onPageNotFound踩坑
Python数据分析学习路线
栈的基本操作
C#实现根据字体名称获取字体文件名
kubernetes 安装与部署
redis
【开卷数据结构 】什么是二叉排序树(BST)?
- 原文地址:https://blog.csdn.net/m0_64261982/article/details/133556885