-
Pytorch目标分类深度学习自定义数据集训练
目录
一,Pytorch简介;
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch 基于 Python: PyTorch 以 Python 为中心或“pythonic”,旨在深度集成 Python 代码,而不是作为其他语言编写的库的接口。Python 是数据科学家使用的最流行的语言之一,也是用于构建机器学习模型和 ML 研究的最流行的语言之一。由于其语法类似于 Python 等传统编程语言,PyTorch 比其他深度学习框架更容易学习。
二,环境配置;
版本:
系统:window10;
Python:3.11.5;
pytorch:2.0.1;
Python安装:
Python官网:python.org;
下载3.11.5版本Python安装版进行安装;
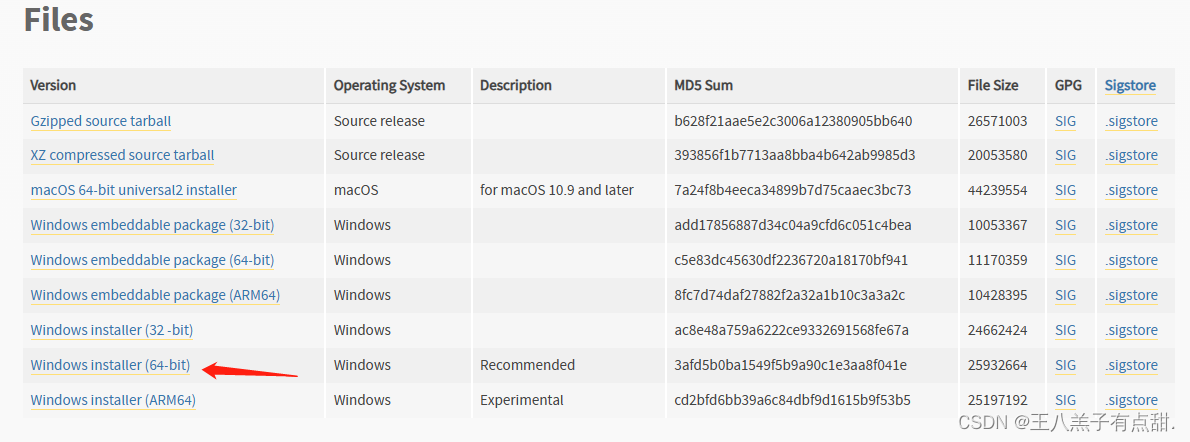
配置Python环境变量;
在系统变量path中添加Python的bin路径和Script路径;
查看Python是否安装成功;
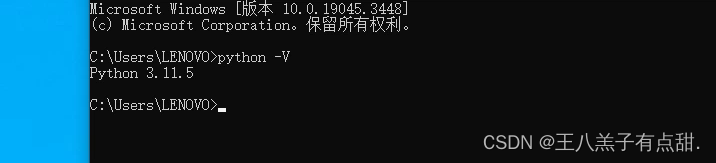
正常如上显示表示安装成功。
同时查看Python对应的Pip版本;
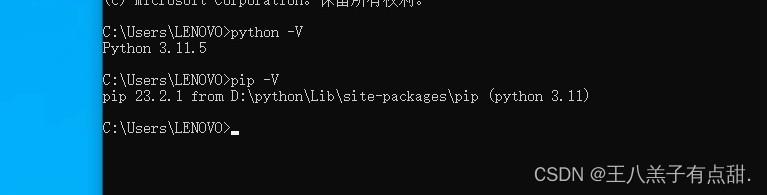
Pytorch安装:
pytorch官网:PyTorch;
进入Pytorch官网后点击左上角Get Started查看Pytorch对于的Python版本,GPU版本。默认安装的是CPU版本,本文使用Pip安装Pytorch方式,直接运行Run this Command会报错,安装了几次都不行,所以自己找对应的安装文件进行安装更方便。
根据Pytorch官网介绍的对应版本找到我们需要的依赖文件。
网址:download.pytorch.org/whl/torch_stable.html
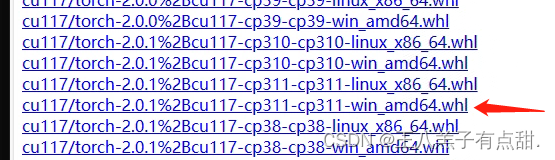
找到对应安装的版本,cu开头表示是GPU版本和版本号,torch后面对应的是Pytorch版本号,cp对应Python版本;点击下载安装文件;
下载好以后打开文件所在位置,进入window命令界面,执行命令;
pip install torch-2.0.1+cu117-cp311-cp311-win_amd64.whl英伟达GPU安装:
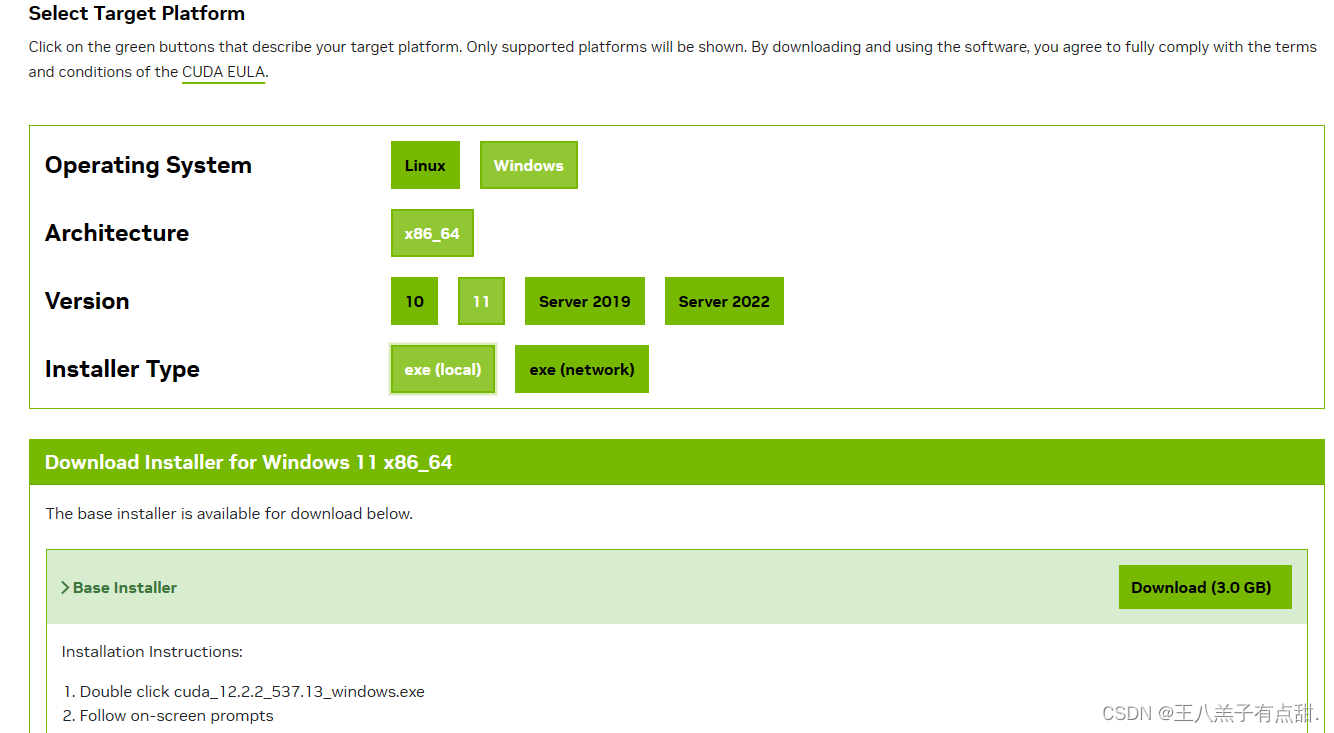
选择对应的GPU版本安装,安装完成后验证下是否安装成功,正常显示版本表示安装成功。
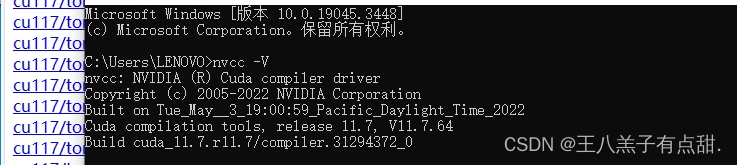
三,自定义数据集;

从网上下载数据集,按照文件夹分类,首先将数据集制作成包含图片路径,和对应索引的csv文件。
- import torch
- import os, glob
- import random, csv
- # 所有自定义数据集的一个母类
- from torch.utils.data import Dataset, DataLoader
- # 常用的图片变换器
- from torchvision import transforms
- # 从图片读取出数据
- from PIL import Image
- # 自定义数据集的类,继承自Dataset
- class Pokemon(Dataset):
- # 一、初始化函数init
- # 第一个参数root:总的图片所在的位置,可以是任意的位置,我们的图片可以放在任意的位置,我们这里就存储在当前目录文件夹下。
- # 第二个参数resize:图片输出的size,是由这个参数所进行设定。
- # 第三个参数mode:这里我们需要做train、validation以及test,对应这三种数据结构,因此我们用一个list[0,1,2]来代表是哪个模式。
- def __init__(self, root, resize, mode):
- # 先调用母类的初始化函数:
- super(Pokemon, self).__init__()
- # 1、首先我们将这个参数保存下来
- self.root = root
- self.resize = resize
- # 2、给每一个分类做一个映射,即当前的皮卡丘、妙蛙种子等这个string类型所对应的label是多少,这个是需要我们人为进行编码的。
- self.name2label = {} # 用字典来表示映射关系
- # 通过循环方式,将root路径下的文件夹名进行编码
- for name in sorted(os.listdir(os.path.join(root))):
- # 过滤掉非文件夹:如果不是dir,就过滤掉,此外我们还通过sorted排序的方法,将键值对关系固定下来
- if not os.path.isdir(os.path.join(root, name)):
- continue
- # 文件名做key,当前name2label的长度做value
- self.name2label[name] = len(self.name2label.keys())
- print(self.name2label)
- # image, label
- self.load_csv('images.csv')
- # 二、创建一个csv,用于保存图片全路径和对应的标签label
- # 这个函数接受一个参数filename
- # 这个函数中需要将所有图片都load进来
- def load_csv(self, filename):
- images = []
- for name in self.name2label.keys():
- # 类别信息我们可以使用路径来判断
- # 上面路径的mewtwo就是类别
- images += glob.glob(os.path.join(self.root, name, '*.png'))
- images += glob.glob(os.path.join(self.root, name, '*.jpg'))
- images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
- print(len(images), images)
- # 将images顺序打乱
- random.shuffle(images)
- # 打开这个文件
- with open(os.path.join(self.root, filename), mode='w', newline='') as f:
- # 新建writer,获得csv这个文件对象
- writer = csv.writer(f)
- for img in images: # 获得每行信息
- # 通过分割符,将每行信息的内容分割开,取导数第二个,类型
- name = img.split(os.sep)[-2]
- # 通过获取的类型名来获取label
- label = self.name2label[name]
- # 将这个label信息写到csv中
- # csv是以逗号作为分割的
- writer.writerow([img, label])
- print('writen into csv file:', filename)
- # 三、完成两个自定义的逻辑
- # 1、样本的总体数量(图片总体数量),返回的是一个数字,总体图片大概有1168张,60%用于training,因此返回6-7百张图片
- def __len__(self):
- pass
- # 2、用于返回当前index上面元素的值,这里是返回两个数据:
- # 需要返回当前image的data,以及image所对应的label[0,1,2,3,4]
- def __getitem__(self, idx):
- pass
- # 创建一个调试函数:
- def main():
- db = Pokemon('F:\\train', 224, 'train')
- if __name__ == '__main__':
- main()
将图片路径改成自己数据的文件夹路径,运行代码在对应路径下生成.csv格式文件
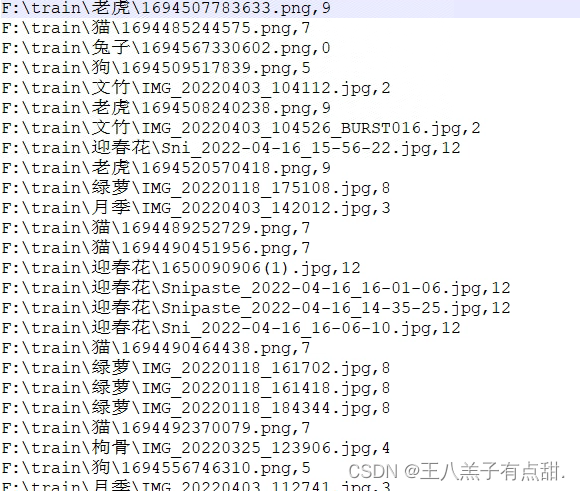
类别索引根据文件夹种类顺序生成,要和csv文件中索引对应。数据集制作完成后就可以开始训练了。
首先定义加载数据集类;
- import torch
- import os, glob
- import random, csv
- # 所有自定义数据集的一个母类
- from torch.utils.data import Dataset, DataLoader
- # 常用的图片变换器
- from torchvision import transforms
- # 从图片读取出数据
- from PIL import Image
- # 自定义数据集的类,继承自Dataset
- class Pokemon(Dataset):
- # 一、初始化函数init
- # 第一个参数root:总的图片所在的位置,可以是任意的位置,我们的图片可以放在任意的位置,我们这里就存储在当前目录文件夹下。
- # 第二个参数resize:图片输出的size,是由这个参数所进行设定。
- # 第三个参数mode:这里我们需要做train、validation以及test,对应这三种数据结构,因此我们用一个list[0,1,2]来代表是哪个模式。
- def __init__(self, root, resize, mode):
- # 先调用母类的初始化函数:
- super(Pokemon, self).__init__()
- # 1、首先我们将这个参数保存下来
- self.root = root
- self.resize = resize
- # 2、给每一个分类做一个映射,这个string类型所对应的label是多少,这个是需要我们人为进行编码的。
- self.name2label = {} # 用字典来表示映射关系
- # 通过循环方式,将root路径下的文件夹名进行编码
- for name in sorted(os.listdir(os.path.join(root))):
- # 过滤掉非文件夹:如果不是dir,就过滤掉,此外我们还通过sorted排序的方法,将键值对关系固定下来
- if not os.path.isdir(os.path.join(root, name)):
- continue
- # 文件名做key,当前name2label的长度做value
- self.name2label[name] = len(self.name2label.keys())
- # print(self.name2label)
- # 将self.load_csv的返回值images, labels赋予self.images, self.labels
- self.images, self.labels = self.load_csv('images.csv')
- # 四、不同比例模式下对图片数量进行划分
- if mode == 'train': # 取60%做training
- # len(self.images)的长度是1167,取60%做为train模式的图片
- self.images = self.images[:int(0.6 * len(self.images))]
- self.labels = self.labels[:int(0.6 * len(self.labels))]
- elif mode == 'val': # 取20%做validation, 60%-80%
- self.images = self.images[int(0.6 * len(self.images)):int(0.8 * len(self.images))]
- self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
- else: # mode为test,取80%到最末尾
- self.images = self.images[int(0.8 * len(self.images)):]
- self.labels = self.labels[int(0.8 * len(self.labels)):]
- # 二、创建一个csv,用于保存图片全路径和对应的标签label
- # 这个函数接受一个参数filename
- # 这个函数中需要将所有图片都load进来
- def load_csv(self, filename):
- # 需要一个判断,如果文件不存在,就需要创建csv,直接读取创建好的csv文件内容即可:
- # 如果不存在,就需要创建csv
- if not os.path.exists(os.path.join(self.root, filename)):
- images = []
- for name in self.name2label.keys():
- # 类别信息我们可以使用路径来判断
- # 上面路径的mewtwo就是类别
- images += glob.glob(os.path.join(self.root, name, '*.png'))
- images += glob.glob(os.path.join(self.root, name, '*.jpg'))
- images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
- print(len(images), images)
- # 将images顺序打乱
- random.shuffle(images)
- # 打开这个文件
- with open(os.path.join(self.root, filename), mode='w', newline='') as f:
- # 新建writer,写入csv这个文件对象
- writer = csv.writer(f)
- for img in images:
- # 通过分割符,将每行信息的内容分割开,取导数第二个,类型
- name = img.split(os.sep)[-2]
- # 通过获取的类型名来获取label
- label = self.name2label[name]
- # 将这个label信息写到csv中
- # csv是以逗号作为分割的
- writer.writerow([img, label])
- print('writen into csv file:', filename)
- # 三、读取csv文件过程:
- # 这里需要在开头有一个判断,如果csv存在,就不用写入csv了,直接进行读取
- # 下次运行的时候只需加载进来即可
- images, labels = [], []
- with open(os.path.join(self.root, filename)) as f:
- # 新建reader,读取csv这个文件对象
- reader = csv.reader(f)
- for row in reader:
- img, label = row
- label = int(label) # 将这个label转码为int类型
- # 将img每个图片路径,以及label保存在建立好的列表对象中。
- images.append(img)
- labels.append(label)
- assert len(images) == len(labels)
- return images, labels
- # 完成两个自定义的逻辑:
- # 1、样本的总体数量(图片总体数量),返回的是一个数字,总体图片大概有1168张,60%用于training,因此返回6-7百张图片
- # 五、完成总体样本数量函数的内容
- def __len__(self):
- # 这里的样本长度是跟模型类别来决定的,上面已经根据不同模型类型划分了样本数量了。
- # 不同模式下,样本长度是不同的。
- # 因此这里的总体样本长度,就是不同模式下的样本数量。
- return len(self.images)
- # 九、解决normalize处理后,visdom无法正常显示的问题
- # 这里传入的参数x是normalize过后的
- def denormalize(self, x_hat):
- mean = [0.485, 0.456, 0.406]
- std = [0.229, 0.224, 0.225]
- mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
- std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
- print('mean.shape,std.shape:', mean.shape, std.shape)
- x = x_hat * std + mean
- return x
- # 2、用于返回当前index上面元素的值,这里是返回两个数据:
- # 需要返回当前image的data,以及image所对应的label[0,1,2,3,4]
- # 六、完成index与样本的一一对应
- def __getitem__(self, idx):
- # idx数值范围是[0-len(images)]
- # self.images保存了所有的数据;self.labels保存了所有数据对应的label信息;
- # img是一个string类型(还不是具体的图片,只是路径)
- # label是一个整数类型
- img, label = self.images[idx], self.labels[idx]
- # 这里就需要将img所对应的路径读取出图片,并转为tensor类型
- # 这里我们可以Compose组合操作步骤
- # 八、增加数据预处理的工作,在Compose中增加这些内容,data augmentation数据增强
- # 这里我们做放大、旋转、裁切这三个数据增强的操作
- tf = transforms.Compose([
- # 这里需要将路径变成具体的图片数据类型
- # 即:string path => image data
- lambda x: Image.open(x).convert('RGB'),
- # Resize工作,这里的size是我们实例化时的self.resize的值
- # 1、data augmentation放大:在Resize设置的基础上,稍微调大一些size, 调整为1.25倍
- transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
- # 2、data augmentation旋转:增加随机旋转,注意:这里旋转角度不能太大,会增加学习的难度。
- transforms.RandomRotation(15),
- # 3、data augmentation中心裁切:裁切为我们所需要的大小
- transforms.CenterCrop(self.resize),
- # 将数据变为tensor类型
- transforms.ToTensor(),
- # 4、normalize处理,希望图片数值范围在0左右分布,而不希望数值只分布在0的右侧或只在左侧
- # 其中参数统计的所有image net数据集几百万张图片的mean=[R的mean,G的mean,B的mean]和std=[R的方差,G的方差,B的方差]
- # 基本上这个数值是通用的
- # 数据通过Normalize处理后,就是在-1到1之间分布了。
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
- ])
- img = tf(img)
- label = torch.tensor(label)
- return img, label
- # 创建一个调试函数:
- def main():
- # 七、验证自定义数据集
- # 验证需要一些辅助函数,用visdom做一些可视化。
- import visdom
- import time
- import torchvision # 通过API较为简便的加载自定义数据集,需要引入torchvision
- # 创建一个visdom这个对象
- viz = visdom.Visdom()
- # 十一、通过API较为简便的加载自定义数据集(前提是数据集按照不同类型存储在对应类型命名的文件夹下面,并且这些不同类别的文件夹都存储在统一的一个文件夹下,只有这种固定的二级目录存储形式才能用这个API进行加载。)
- tf = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor()
- ])
- # 参数1:传入路径
- # 参数2:变换器,这个变换器就是进行resize操作
- db = torchvision.datasets.ImageFolder(root='F:\\train', transform=tf)
- loader = DataLoader(db, batch_size=32, shuffle=True)
- print(db.class_to_idx) # 通过这个就能知道不同类别是如何编码的了。
- if __name__ == '__main__':
- main()
将上面代码修改即可;
四,模型训练;
这里我们需要用到可视化工具来查看我们训练效果。
安装visdom:
pip install visdom在pycharm命令界面启动visdom:
python -m visdom.server正常启动在浏览器输入localhost:8097打开可视化界面;
准备工作完成,编写模型训练代码,这么我们直接使用Pytorch自带的神经网络resnet18模型;
- import torch
- from torch import optim, nn
- import visdom
- import torchvision
- from torch.utils.data import DataLoader
- from pokemon import Pokemon
- from torchvision.models import resnet18 # 这个resnet18是已经training好的状态
- from utils import Flatten # 用于打平,这个是自己来实现的打平层
- batchsz = 32
- lr = 1e-3
- epochs = 40
- device = torch.device('cuda')
- torch.manual_seed(1234) # 这个是随机数种子,保证每次都能复现出来。
- # 这里是需要实例化Pokemon类
- # 这里之所以使用224,是因为是ResNet最适合的大小。
- train_db = Pokemon('F:\\train', 224, 'train')
- val_db = Pokemon('F:\\train', 224, 'val')
- test_db = Pokemon('F:\\train', 224, 'test')
- # 批量加载数据
- # 参数num_workers表示工作线程数:
- train_loader = DataLoader(train_db
- , batch_size=batchsz
- , shuffle=True
- , num_workers=4)
- val_loader = DataLoader(val_db
- , batch_size=batchsz
- , num_workers=2)
- test_loader = DataLoader(test_db
- , batch_size=batchsz
- , num_workers=2)
- # 需要把train的进度保存下来,需要用到visdom
- viz = visdom.Visdom()
- # 建立一个测试函数:测试函数针对validation和test功能是一样的
- def evalute(model, loader):
- # 用于统计总的预测正确的数量
- correct = 0
- # 总的测试数量
- total = len(loader.dataset)
- for x, y in loader:
- x, y = x.to(device), y.to(device)
- with torch.no_grad(): # test和validation是不需要梯度信息的
- logits = model(x)
- pred = logits.argmax(dim=1) # 最大的值所在的位置
- # 总的预测正确的数量,累加操作
- correct += torch.eq(pred, y).sum().float().item()
- accuracy = correct / total
- return accuracy
- def main():
- # 实例化模型
- # 使用已经训练好的resnet18模型,一定要设置这个参数pretrained=True
- trained_model = resnet18(pretrained=True)
- # 我们要使用训练好的resnet18模型的A部分,即取出前17层:
- # Sequential结束的是一个打散的数据,所有我们在list前加一个*,*args:接收若干个位置参数,转换成元组tuple形式。
- model = nn.Sequential(*list(trained_model.children())[:-1] # model的前17层(即A部分)返回的结果是:[b,512,1,1]
- , Flatten() # 打平操作从[b,512,1,1]=>[b,512]
- , nn.Linear(512, 14) # 这层是最后那层,用于从新学习分成14类。(第二个参数为自定义数据集实际训练种类数量,根据自己数据集的种类数据传递实际值)
- ).to(device)
- # 我们从已经训练好的resnet18开始训练效果会好很多
- # # 这里我们测试一下
- # x = torch.randn(2,3,224,224)
- # print(model(x).shape)#打印结果为:torch.Size([2, 5])
- # #这样就实现了transfer learning
- # ======================================================
- # 创建一个优化器Adam,这个优化器比较好
- optimizer = optim.Adam(model.parameters(), lr=lr)
- # Loss的计算方法:CrossEntropyLoss;
- # 这个Loss所接受的参数是logits,logits是不需要经过一个softmax的,只需要得到logits即可。
- criteon = nn.CrossEntropyLoss()
- # 用于保存模型的训练状态
- best_acc, best_epoch = 0, 0
- # step每次都是从0开始的,因此这里我们创建一个全局step
- global_step = 0
- # 用visdom工具保存下accuracy和loss
- # training和loss的曲线
- # x=0,y=-1是初始状态
- viz.line([0], [-1], win='loss', opts=dict(title='loss(损失值)'))
- # training和validation accuracy的曲线
- viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc(准确率)'))
- # training逻辑
- for epoch in range(epochs):
- for step, (x, y) in enumerate(train_loader):
- # x:[b,3,224,224]; y:[b]
- x, y = x.to(device), y.to(device) # x和y都转移到cuda上面
- # 执行forward函数
- logits = model(x) # 学出的预测结果
- # 在pytorch中crossEntropyLoss中,传入的真实值y不需要进行one-hot操作,不需要做one-hot编码,会在内部做one-hot。
- # 所以我们直接传入y就可以了。
- loss = criteon(logits, y) # 预测结果与真实值进行交叉熵计算
- # 前向传播和迭代过程
- # 优化器
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- # 用visdom工具保存下accuracy和loss
- # 每一个step我都要记录下来
- # validation和loss的曲线
- # x=loss.item()loss是一个tensor,因此需要通过item转为具体数值,y=-1是初始状态
- # 参数update为append,表示添加到曲线的末尾。
- viz.line([loss.item()], [global_step], win='loss', update='append')
- global_step += 1
- # 这里我们每完成两个epoch就做一组validation
- if epoch % 1 == 0:
- # 我们根据validation accuracy来选择要不要保存这个模型的训练状态。
- val_acc = evalute(model, val_loader)
- # 如果当前accuracy大于best_acc,就保存当前的状态:
- if val_acc > best_acc:
- best_epoch = epoch
- best_acc = val_acc
- # 保存当前模型的状态:
- # 参数一:模型状态值
- # 参数二:模型状态保存的文件名,文件名后缀随意
- torch.save(model, 'best-pro.pth')
- # validation和 accuracy的曲线
- # 这里val_acc是数值型,所以不需要转换。
- viz.line([val_acc], [global_step], win='val_acc', update='append')
- print('best acc:', best_acc, 'best epoch:', best_epoch)
- # 从最好的状态加载模型:
- # model.load_state_dict(torch.load('best-pro.ptl'))
- # print('loaded from check point!')
- #
- # # 上面加载了最好的模型状态,这里使用的模型也是最好的状态时的模型
- # test_acc = evalute(model, test_loader)
- # print('test_acc:', test_acc)
- if __name__ == '__main__':
- main()
这里我们用到了一个util:
- from matplotlib import pyplot as plt
- import torch
- from torch import nn
- # 该函数是一个标准的打平层
- class Flatten(nn.Module):
- # 该文件utils包含一些辅助函数。
- def __init__(self):
- super(Flatten, self).__init__()
- def forward(self, x):
- shape = torch.prod(torch.tensor(x.shape[1:])).item()
- return x.view(-1, shape)
- # 该函数是将img打印到matplotlib上
- def plot_image(img, label, name):
- fig = plt.figure()
- for i in range(6):
- plt.subplot(2, 3, i + 1)
- plt.tight_layout()
- plt.imshow(img[i][0] * 0.3081 + 0.1307, cmap='gray', interpolation='none')
- plt.title("{}: {}".format(name, label[i].item()))
- plt.xticks([])
- plt.yticks([])
- plt.show()
运行函数打开可视化界面,查看训练情况;
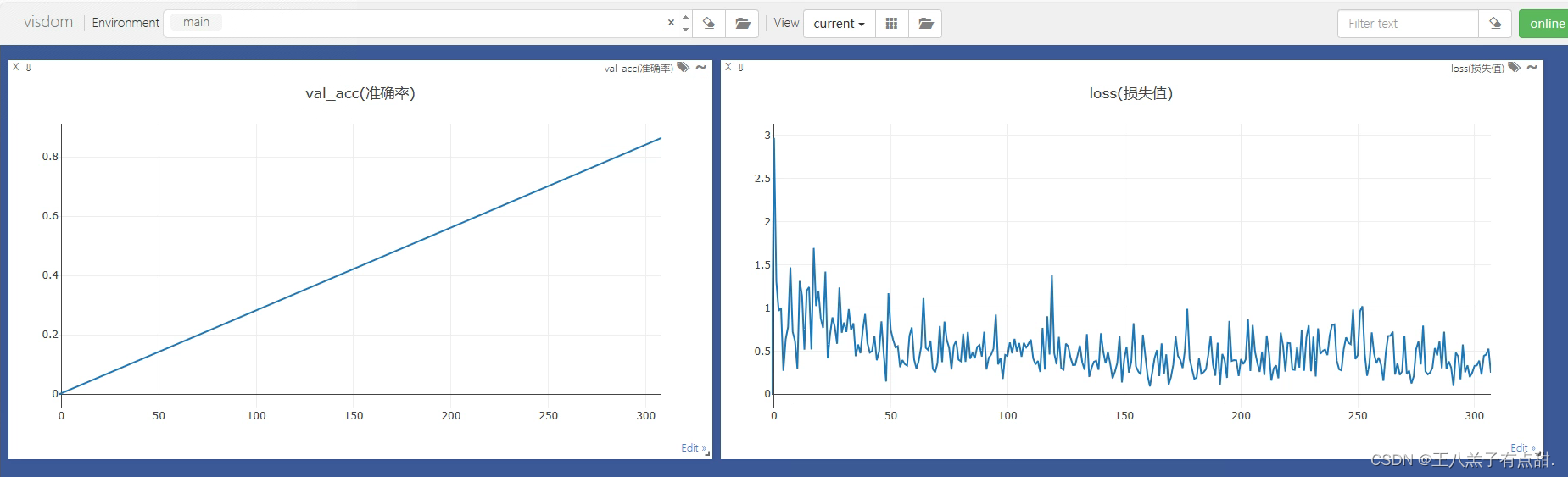
刚开始训练的情况,使用数据量大概1.6w张最终结果大概是准确率96%。已经非常好了。
五,模型验证;
- import numpy as np
- import torch
- import torch.nn.functional as F
- import torchvision.transforms as transforms
- from PIL import Image
- device = torch.device('cuda')
- def main():
- labels = ['兔子', '吊兰', '文竹', '月季', '枸骨', '狗', '狮子', '猫', '绿萝', '老虎', '菊花', '蛇', '迎春花', '龟背竹']
- image_path = "C:/Users/LENOVO/Desktop/dog.png"
- image = Image.open(image_path)
- image = image.resize((256, 256), Image.BILINEAR).convert("RGB")
- image = np.array(image)
- to_tensor = transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
- image = to_tensor(image)
- image = torch.unsqueeze(image, 0)
- image = image.cuda()
- model = torch.load("刚才训练好的模型")
- model.eval()
- model.to(device)
- output = model(image)
- output1 = F.softmax(output, dim=1)
- predicted = torch.max(output1, dim=1)[1].cpu().item()
- outputs2 = output1.squeeze(0)
- confidence = outputs2[predicted].item()
- confidence = round(confidence, 3)
- print("识别结果: ", labels[predicted], " 准确率为: ", confidence * 100, "%")
- if __name__ == '__main__':
- main()
测试图片:

labels为我们训练的类别数组,和cvs的索引对应。
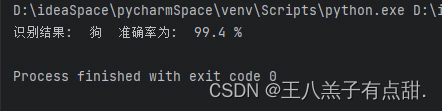
多次测试结果全对,准确率不低于95%。
-
相关阅读:
[Power Query] 删除重复项
计算机网络——第五章网络层笔记(5)
PAT 1005 Spell It Right
洛谷P1331 海战 题解
Redis cluster集群搭建
MyBatis 缓存
Oracle数据库体系结构简介
Java Stream & Reactor
学习Java8 Stream流,让我们更加便捷的操纵集合
区块链(11):java区块链项目之页面部分实现
- 原文地址:https://blog.csdn.net/liukangjie520/article/details/132901511
