-
BEAPP:脑电批处理平台
摘要
脑电图(EEG)提供了与各种神经系统和神经精神疾病相关的脑功能信息。EEG包含复杂的高时间分辨率信息,而计算分析可以最大限度地利用这些信息。在这里,本研究提出了批量脑电图自动处理平台(BEAPP),这是一个自动化、灵活的EEG处理平台,集成了可用于跨多个处理步骤批处理多个EEG文件的软件工具。BEAPP不规定特定的脑电处理流程;相反,它允许用户从EEG处理的选项菜单中进行选择,包括管理跨多个采集设备(例如,多站点研究)收集的EEG文件,最小化伪迹,分段连续和/或事件相关EEG,并执行基本分析。总的来说,BEAPP旨在简化批量脑电处理、提高计算脑电评估的可访问性,并提高结果的可重复性。
前言
脑电图(EEG)作为了解大脑功能的窗口提供了巨大的机会。它提供了理解大规模神经网络活动的潜力,因此在神经元和行为之间起到了桥梁的作用。它具有可转化性,为动物和人类之间的桥接提供了机会。它可以适用于各个年龄段的人群,而无需使用镇静剂,也可以用于典型人群和临床人群,有助于在无法遵循指令且行为能力有限的人群(如幼儿)中采集数据。其便携性和相对经济性使得它可以轻松地用于多站点研究,这在研究罕见疾病或获取大型数据集时特别有用。
通常,许多研究会结合两个或多个不同领域的知识。神经科学、心理学和发展学等领域的研究人员对EEG特别感兴趣,因为它能够测量并增强对各个年龄段、环境和疾病状态下大脑活动的理解。在这方面,开源工具包如EEGLAB、与SPM集成的FieldTrip、Brainstorm、MNE与MNE-Python以及NUTMEG提供了大量的机会。所有这些工具包都为脑电信号(以及MEG信号)处理提供了多种高级选项,并且可以为多个脑电文件创建跨多个处理步骤和分析的批处理脚本。
尽管取得了这些重要进展,但在某些情况下,综合分析的可访问性仍然有限。对于没有编码经验的用户来说,创建分析脚本或处理流程可能是一个令人生畏的过程。对于有编码经验的用户来说,追踪分析各个步骤中的输入、输出和特定设置可能是一项具有挑战性的任务。对于评估大规模多站点或纵向数据集的用户来说,这尤其值得关注。在这些数据集中,原始的脑电格式、采样率、电极布局、变量名称甚至线噪声频率可能会在不同文件之间有所不同。此外,分析的可重复性仍然有限。在自动化分析中,研究人员用于生成数据的代码可能会链接多个软件包,设置的参数仅在“材料和方法”部分报告,并且不一定会保存和共享。而且由于难以避免人为错误和判断差异,“手动编辑”脑电数据进一步加剧了这一问题。
因此,批处理脑电自动化处理平台(BEAPP)旨在通过在现有脑电分析工具包基础上构建一个灵活的结构,为脑电数据集的自动化批处理提供支持,增强可访问性和可重复性。从原始或部分预处理的数据开始,BEAPP提供了一系列自动化步骤来管理在多个采集设置下收集的脑电信号,最小化伪迹,执行多种类型的重参考,分段连续和/或事件相关EEG,并进行时频分析。用户可以在单个脚本界面或图形用户界面(GUI)中确定输入参数,这些界面可以保存为模板供未来的用户使用,使用户能够在不编写自己代码的情况下确定分析和参数。BEAPP跟踪分析的每个步骤的输出和参数,允许用户查看先前步骤或在需要时使用新参数重新运行部分分析。
材料和方法
BEAPP是基于MATLAB的模块化软件,用户可以通过GUI或脚本输入参数。BEAPP是免费提供的,受GNU通用公共许可证(第3版)(自由软件基金会,2007)条款的保护。BEAPP软件包、用户手册和新模块创建入门指南可在以下网址获得:https://github.com/lcnbeapp/beapp。BEAPP存储在GitHub上,希望用户在BEAPP结构基础上添加新功能,最终为各个实验室和研究项目的脑电分析提供共享。BEAPP整合了一些脑电分析工具包和管道的代码,包括EEGLAB、PREP管道、CSD工具包、REST、Cleanline、FieldTrip、MARA和HAPPE。
根据输入和输出数据的格式,BEAPP分为四个主要步骤(图1)。步骤1涉及将原始数据转换为BEAPP格式。步骤2涉及对连续数据进行预处理,以最小化实验产生的伪迹并实现采集设置的标准化。步骤3涉及将连续数据分段以便进一步分析。步骤4包括几个分析选项,特别是基于频谱分解的选项。如果用户希望输入预分段的数据,可以跳过步骤2和步骤3,直接进行分析。值得注意的是,尽管在概念上步骤1和步骤2是分开的,但在GUI中,这些步骤被合并在“格式和预处理”选项下。
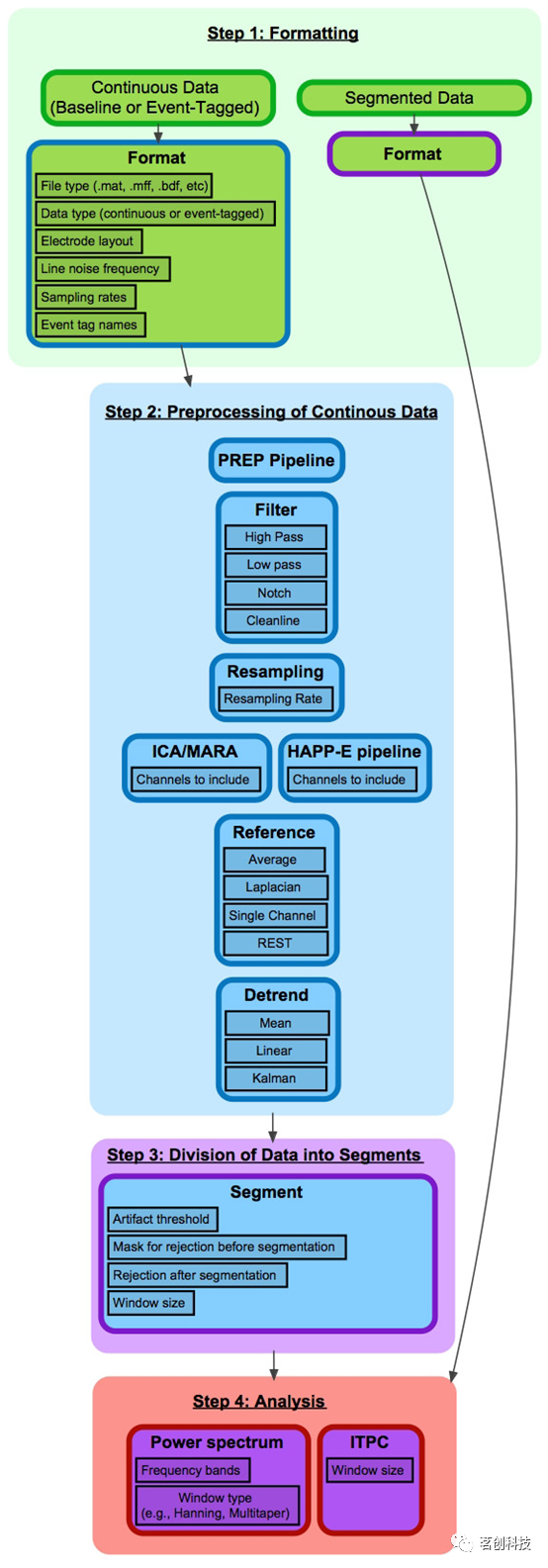
图1.BEAPP步骤和模块的流程图。
步骤1:将数据转换为BEAPP格式
在运行任何处理、分割或分析模块之前,BEAPP会将数据从其原始文件格式转换为BEAPP文件格式。BEAPP可以处理多种源文件格式;关于如何准备源文件的详细信息包含在用户手册中。BEAPP格式包含一个名为eeg的单元数组,每个记录周期包含一个与EEG数据相关的矩阵,该矩阵的每一行包含特定通道的脑电幅值,每一列包含特定时间点的脑电幅值。例如,从一个采样率为500Hz的129导EEG在60s内获得的数据将是一个129×30000的矩阵。BEAPP格式还包括一个标记为file_proc_info的变量,其中包含特定EEG的关键信息,如电极布局、事件时间和采样率。当每个文件在BEAPP平台上运行时,关于EEG经历了哪些处理步骤的详细信息也包含在file_proc_info中。值得注意的是,BEAPP格式的文件可以使用batch_beapp2eeglab.m和batch_eeglab2beapp.m函数与EEGLAB文件格式进行相互转换。原始连续(未分段)的脑电数据可以在BEAPP中灵活选择运行哪些模块。然而,如果用户希望提供经过预处理和预分段的数据供BEAPP分析,也是可以的。
格式转换模块要求用户向BEAPP提供原始EEG数据和其他必要的信息,包括数据类型信息(基线、事件标记或条件基线)。在这里,基线是指连续采集且与任何特定刺激或时间点无关的数据。(如果在标记为“基线”的数据中存在任何事件标记,则这些标记将在分析中被忽略)。对于许多用户来说,静息态数据可能符合这些条件。“事件标记”是指数据可能是连续采集的,但包含指定分段发生的特定刺激或时间点的标记。例如,这可以用于事件相关电位(ERP)范式。“条件基线”是基线数据和事件标记数据的混合,其中基线数据出现在事件标记之间,包括交替或反复出现的基线数据段。间歇性睁眼和闭眼的静息态数据、睡眠阶段或包含间歇性癫痫性活动的数据通常属于这种数据类型。还有一种选项,可以指定是否应分析特定的“记录周期”数据。在BEAPP中,“记录周期”是指在非连续数据文件中的连续数据段。例如,如果一个EEG文件包含一分钟的连续数据,然后是没有记录EEG的休息段,接着又是一分钟的连续数据,那么每个一分钟的连续数据运行都被视为一个记录周期,并且将分别报告每个记录周期的输出。此外,用户还可以提供有关电极布局、线噪声频率、采样率、事件标记名称和事件标记偏移量等信息,这些信息在单个数据集中的不同EEG之间可能有所不同。
步骤2:连续数据的预处理
在步骤2中,每个模块输入一个连续的EEG信号,经过该模块修改后输出另一个连续的EEG信号。用户选择的第一个模块利用用户提供的EEG作为其输入,并且用户选择的每个后续模块都建立在对前一个模块中所做的EEG更改之上。如上所述,用户可以决定使用哪些模块,以及关闭哪些模块。
PREP管道
步骤2中的第一个模块是PREP管道。PREP管道是作为标准化的早期预处理管道而开发的,包括使用cleanline方法去除线噪声,以及进行坏导检测和插值。由于线噪声频率因地区而异(北美大部分地区为60Hz,欧洲、非洲和澳大利亚大部分地区为50Hz,南美洲和亚洲部分地区可能为50或60Hz),因此BEAPP用户有机会在格式转换模块中指定其数据集的预期线噪声频率,并在PREP中进行相应更改。对于那些可能希望评估来自多个国家/地区的具有潜在不同线噪声频率数据的用户,他们还可以为每个单独的文件分别定义线噪声频率。由于PREP是一个标准化管道,因此通过BEAPP可选的PREP输入参数会受到限制,但高级用户可以根据需要直接在PREP中进行手动更改。输出包括有关PREP管道确定的各种变量信息,包括是否遇到任何错误,以及PREP插值了哪些通道。
滤波
用户接下来可以使用滤波模块来执行高通、低通和/或陷波滤波步骤,并可以设置每个步骤的频率参数。在这个模块中,BEAPP目前使用EEGLAB的eegfiltnew函数进行高通、低通和陷波滤波,该函数会提取特定文件的脑电数据和采样率。Cleanline也可用于去除线噪声。
本模块中包含多项检查。首先,由于用户有可能在滤波后进行重采样,BEAPP验证允许的最小采样率(重采样后)不会小于低通滤波器最大频率的两倍,以避免在重采样过程中出现混叠现象。(需要注意的是,由于典型滤波器存在缺陷,实际上我们建议将低通滤波器设置为低于重采样率的奈奎斯特频率)。或者,如果特定文件的数据采样率低于低通滤波器中的最大有效频率,就会跳过该文件的滤波处理。在这两种情况下都会生成用户通知,尽管流程将继续运行。
通常,用户会选择使用陷波滤波器或cleanline方法来去除线噪声,但不能同时使用两者。值得注意的是,PREP管道和HAPPE管道均采用了cleanline;因此,因此,对数据应用PREP或HAPPE的用户可能会选择在此模块中关闭陷波滤波和cleanline步骤。默认情况下,如果陷波滤波器或cleanline方法被启用,那么它们将针对用户定义的线噪声范围的频率成分进行处理。
重采样
接下来提供的模块是重采样。用户目前可以选择使用MATLAB的interp1函数进行插值来重采样。尽管重采样可以出于多种原因使用,但在BEAPP中,其主要用途可能是通过将高采样率下的脑电图进行降采样,以匹配低采样率下的脑电图,从而对多个采集设置的采样率进行标准化。
独立成分分析
BEAPP包含一个ICA模块,该模块提供了三种应用ICA到数据集的选项。其中一个选项是仅使用ICA,它将选定通道的数据分解为一系列最大化彼此时序独立性的成分。BEAPP采用了扩展的Infomax ICA算法(预白化)来处理具有亚高斯或超高斯活动分布的源。相对于其他ICA算法和分解方法,该ICA算法已被证明是一种有效的电生理信号(如脑电信号)分解方法。如果用户希望分析某个特定的成分或一系列成分,则可以选择此选项。
第二个选项是,如果用户希望使用ICA进行伪迹拒绝,可以选择具有多伪迹拒绝算法(MARA)的ICA选项。虽然MARA的详细信息在Winkler等人(2011,2014)的研究中有描述,但值得注意的是,MARA已被证明能够以自动化的方式识别多种类型的伪迹(包括肌肉伪迹和眼动伪迹),并可以应用于不同的电极位置。虽然未来可以添加其他自动化伪迹检测选项,但我们从MARA开始,是因为它具有完全自动化的方法、可以适用于不同参与者和EEG采集方式,并且可以检测多种类别的伪迹(而不是局限于单一的伪迹类型)。对于希望可视化MARA选择拒绝的成分,或进行手动成分拒绝的用户,提供了可视化选项;然而,用户应注意,添加手动步骤可能会降低BEAPP中自动化EEG处理的可重复性。
第三个选项是,用户还可以在BEAPP中运行HAPPE管道。HAPPE包括1Hz的高通滤波(对500Hz或更高采样率的EEG进行1-249Hz的带通滤波)、用cleanline方法去除线噪声、自动坏导检测和去除、小波增强ICA(W-ICA)和具有MARA的ICA用于伪迹去除、坏导插值以及平均参考、单通道或通道子集参考。在BEAPP的分段步骤中,HAPPE还提供特定的分段选项,包括自动分段拒绝。HAPPE为每个EEG生成一个包含所有数据质量指标的汇总报告,以便评估文件是否适合进一步分析,并评估HAPPE在数据上的表现。
重参考
BEAPP提供了几个重参考数据的选项。其中一种参考选项是参考电极标准化技术(REST),有多项研究发现REST的性能优于其他参考技术,因此提供了此选项。如果用户愿意,数据可以在此阶段进行平均参考。(值得注意的是,如果原始数据已经进行了平均参考,或者已经对数据集运行了PREP或HAPPE,那么在此阶段不需要再次进行平均参考,因为这些管道输出的是平均参考的数据)。数据还可以参考到单个通道或用户定义的通道子集。另外,也可以使用CSD工具箱中的Laplacian进行参考。Laplacian变换可以抵消信号中的容积传导和肌肉伪迹等负面影响;此外,Laplacian和平均参考可以提供互补信息,因为这些技术允许对局部和广泛活动进行有针对性的分析。
去趋势
BEAPP预处理步骤中提供的最后一个模块是去趋势选项。目前用户可以选择均值、线性或卡尔曼去趋势。虽然平均或线性去趋势对于大多数用户来说可能就足够了,但卡尔曼去趋势可用于去除经颅磁刺激和心电图中的伪迹,以及癫痫尖峰的检测。卡尔曼滤波在贝叶斯框架内工作,使用周围信息来估计过程的状态,从而估计要从信号中去除的噪声。值得注意的是,该模块中的“去趋势”是指对连续脑电图的处理。在步骤3中还提供了用于在单个段内进行去趋势的单独选项。
步骤3:数据分段
在分段步骤中,用户可以指定是否将数据视为基线数据、事件相关数据或条件基线数据,以及是否进行任何其他处理(例如,段内去趋势)。此外,该步骤还允许用户为每个段提供拒绝标准。
事件相关数据
对于事件相关EEG,用户可以定义感兴趣的刺激事件代码,并指定与该刺激相关段的起始时间和结束时间。如果事件代码的时间与真实刺激传递时间不一致(例如,由于刺激呈现设置中的传输延迟),用户可以在格式转换模块中定义此偏移量。如果数据集的偏移量不一致,用户可以提供一个表格来定义每个文件的偏移量。创建段后,用户可以选择是否进行段内线性去趋势处理。如果任何通道中的数据超过用户设置的幅度阈值,或使用HAPPE中定义的拒绝标准,则可以剔除坏段。
基线数据
对于基线数据,用户定义要创建的段长,BEAPP将从可用数据中创建一系列不重叠的段。在BEAPP进行分段之后,可以根据幅度阈值或基于HAPPE的阈值来剔除坏段(图2A)。此外,BEAPP还提供一个选项,可以使用幅度阈值首先识别连续脑电图中无法使用的数据段,然后从剩余数据中创建段。在识别任何高于阈值的数据点之后,BEAPP会确定该数据点之前和之后最近的过零点,然后将超过阈值的数据点所在段标红。BEAPP会创建一个掩码,标记其中任何通道高于阈值的数据段(根据过零起始点和结束点定义),然后从剩余数据创建段(图2B)。

图2.分段和幅度阈值。
条件基线数据
如上所述,条件基线数据本质上是基线数据和事件标记数据的混合,其中基线数据出现在事件标记之间。用户指定表示条件基线段开始和结束的事件标记。然后,与基线数据一样,用户定义要创建的段长,BEAPP会相应地在事件标记之间对数据进行分段。
步骤4:分析
功率谱
功率谱最初是在上面创建的每个段或子段上计算的。有几个选项可以计算功率谱。如果用户选择使用矩形窗或汉宁窗,则用MATLAB中的fft函数通过快速傅里叶变换(FFT)来计算功率。如果用户选择使用多窗法来计算功率谱,则可以选择要应用的窗数。然后使用MATLAB的pmtm函数计算功率谱。
试次间相位相干性
试次间相位相干性(ITPC)可用于在各段之间计算EEG信号与重复时间锁定事件相位同步的程度。此计算使用了EEGLAB中的newtimef.m函数。对于每个事件条件和每个通道,计算所有段、相关频谱时间窗(由用户定义的子窗口长度确定)和频率区间的相位相干性。该模块的输出是复数,其中包括有关ITPC幅度(复数的绝对值)和相位(复数的角度)的信息。
结论
BEAPP是一种批量自动化脑电图(EEG)处理和分析工具,可用于多个EEG数据(包括在多个采集设置中收集的数据)和多个处理步骤的自动化批处理。BEAPP允许用户从菜单中选择满足其需求的选项,而不是指定一组特定的处理步骤。BEAPP有两个主要目标。首先是可访问性。BEAPP旨在提供一个桥梁,使大脑研究人员能够通过复制其他人的分析管道或创建自己的分析管道,从而更轻松地使用经验丰富的信号处理专家创建的有用工具。第二个目标是再现性。通过提高不同执行环境中的方法和工作流的可访问性,BEAPP旨在提高实验中的可重复性、实验间的可复制性以及跨实验室的协作性。总的来说,BEAPP旨在为跨多个预处理和分析步骤以及多个EEG数据集(包括采集设置不同的EEG数据)的批处理提供一个结构化流程。该结构的长期目标包括改进各个领域EEG分析的可访问性,并提高其可重复性。
参考文献:April R. Levin1, Adriana S. Méndez Leal, Laurel J. Gabard-Durnam, Heather M. O’Leary, BEAPP: The Batch Electroencephalography Automated Processing Platform. Front. Neurosci. 12:513.
-
相关阅读:
免费学习Linux!
【k8s】浅谈对kubernetes基本概念
邮件自动化:简化Workplace中的操作
自动化测试何时切入?为何选择selenium做UI自动化?
Python学习:类与实例
【大数据分布并行处理】单元测试(四)
Java学习----UDP和反射
Cobalt_Strike与Metasploit(msf)联动-Win或Linux不同系统之间互相弹shell
【数据库04】中级开发需要掌握哪些SQL进阶玩法
《C和指针》读书笔记(第十四章 预处理器)
- 原文地址:https://blog.csdn.net/u011661076/article/details/133494549