-
【计算机组成原理】考研真题攻克与重点知识点剖析 - 第 1 篇:计算机系统概述
前言
- 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。
- 此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术有限,最终数据清洗结果不够理想,相关CSDN文章便没有发出。
- 从这篇文章开始,这里我将按章节顺序,围绕考研真题展开计算机组成原理总共7章的知识,边学习边整理数据。
请注意,本文中的部分内容来自网络搜集和个人实践,如有任何错误,请随时向我们提出批评和指正。本文仅供学习和交流使用,不涉及任何商业目的。如果因本文内容引发版权或侵权问题,请通过私信告知我们,我们将立即予以删除。
文章目录
- 前言
- 基础知识
- 上述知识思维导图
- 上述知识思维导图
- 上述知识思维导图
- 相关习题
- 1. 关于计算机系统层次结构
- 2. 关于计算机的性能指标
- (1) 下列选项中,能缩短程序执行时间的措施是?
- (2) 下列选项中,描述浮点数操作速度指标的是?
- (3) 假定基准程序 A 在某计算机上的运行时间为 100s,其中 90s 为 CPU 时间,其余为 I/O 时间。若 CPU 速度提高 50%,I/O 速度不变,则运行基准程序 A 所耗费的时间是?
- (4) 某计算机的主频为 1.2GHz,其指令分为 4 类,它们在基准程序中所占比例及 CPI 如下表所示。
- (5) 程序 P 在机器 M 上的执行时间是 20s,编译优化后,P 执行的指令数减少到原来的 70%,而 CPI 增加到原来的 1.2 倍,则 P 在 M 上的执行时间是?
- (6) 假定计算机 M1 和 M2 具有相同的指令集体系结构(ISA),主频分别为 1.5GHz 和 1.2GHz。在 M1 和 M2 上运行某基准程序 P,平均 CPI 分别为 2 和 1,则程序 P 在 M1 和 M2 上运行时间的比值是?
- (7) 下列给出的部件中,其位数(宽度)一定与机器字长相同的是?
- (8) 2017 年公布的全球超级计算机 TOP 500 排名中,我国“神威·太湖之光”超级计算机蝉联第一,其浮点运算速度为93.0146 PFLOPS,说明该计算机每秒钟内完成的浮点操作次数约为?
- (9) 某计算机主频为1GHz,程序P运行过程中,共执行了10000条指令,其中80%的指令执行平均需1个时钟周期,20%的指令执行平均需10个时钟周期。程序P的平均CPI和CPU执行时间分别是?
- 考研真题
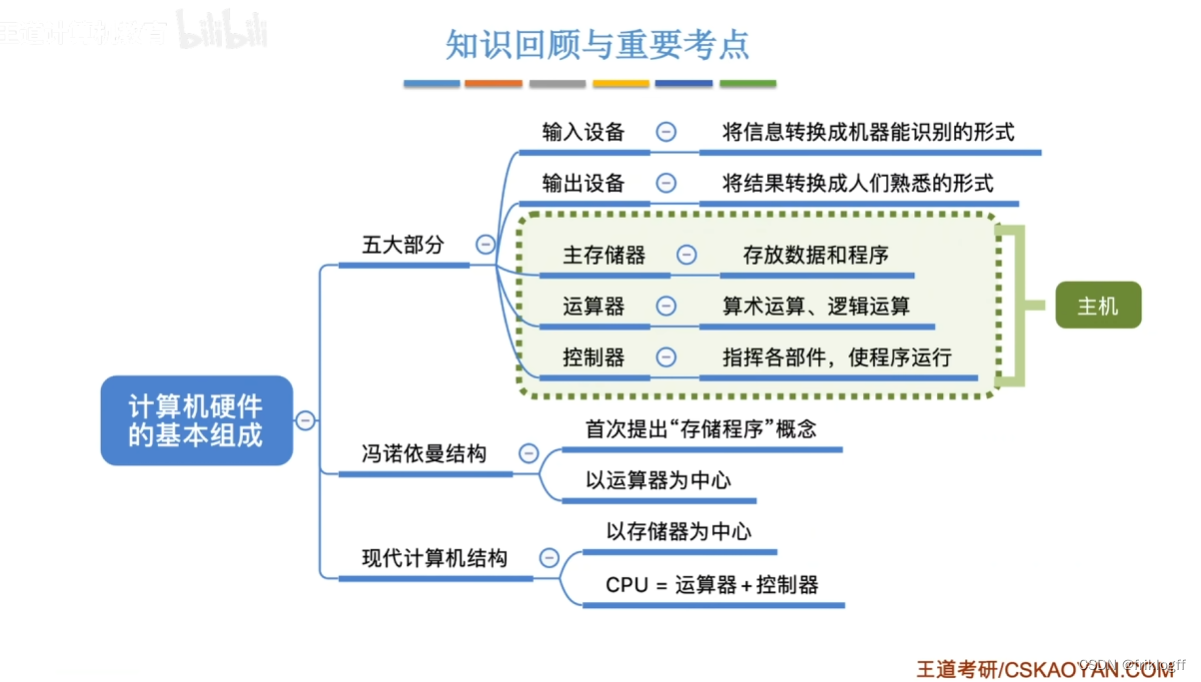
基础知识
通用计算机的诞生
冯·诺依曼结构的基本思想
最重要思想:“存储程序”
工作方式:要完成的工作编写为程序,将程序和数据送入主存并执行。程序一旦启动,计算机能够自动完成逐条取出指令和执行指令的任务
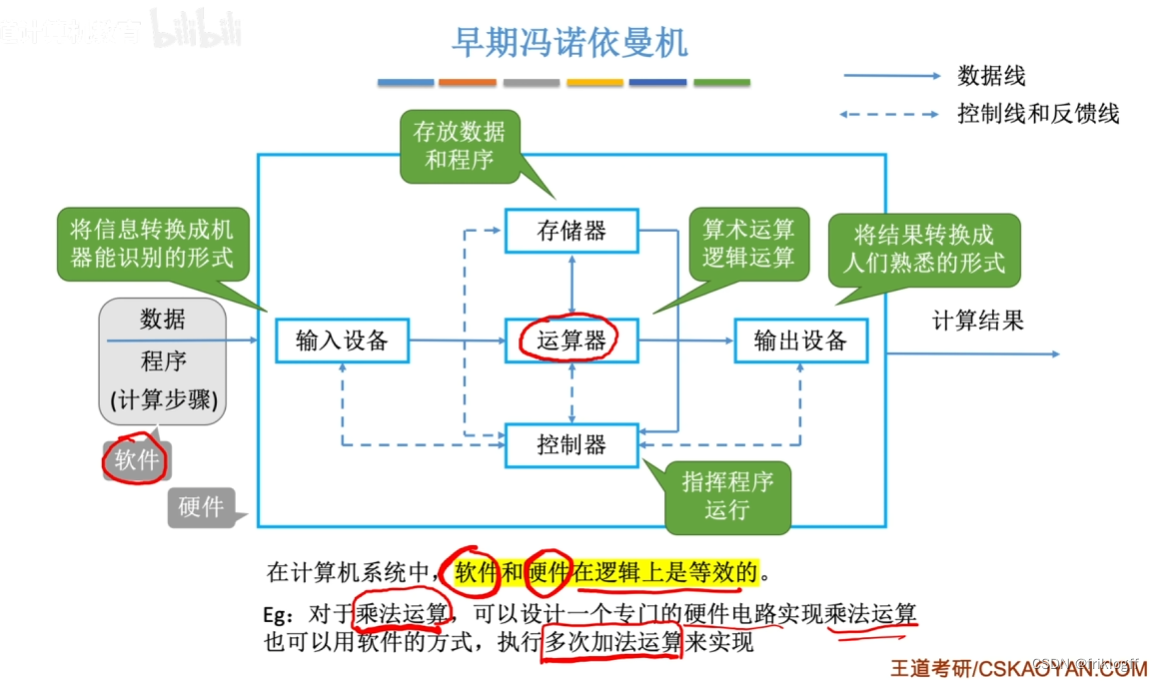
特点
-
- 采用“存储程序”的工作方式
-
- 计算机由五大部件组成(运算器、存储器、控制器、输入设备、输出设备)
-
- 指令和数据以同等地位存储在存储器中,形式上两者没有区别,但计算机应能区分(CPU区分指令与数据,依据是指令周期不同阶段)
-
- 指令和数据用二进制代码表示,指令由操作码和地址码组成,可按地址寻址
-
- 以运算器为中心
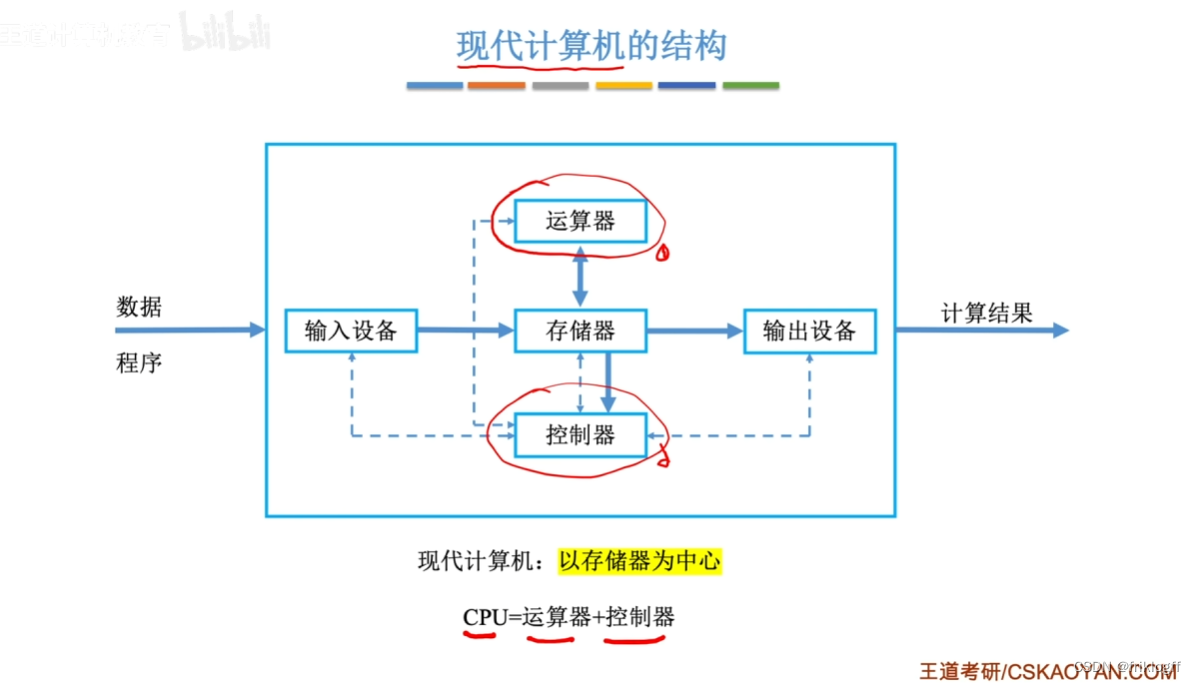
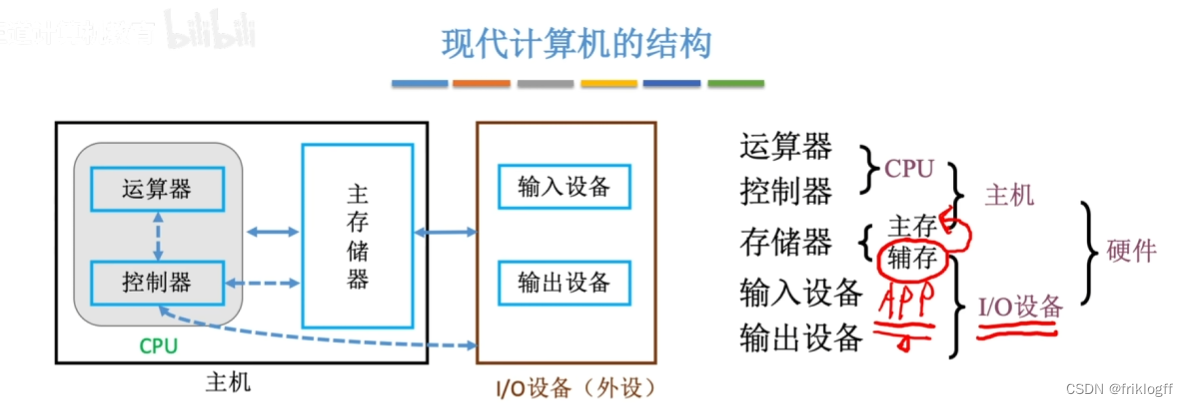
现代计算机的结构
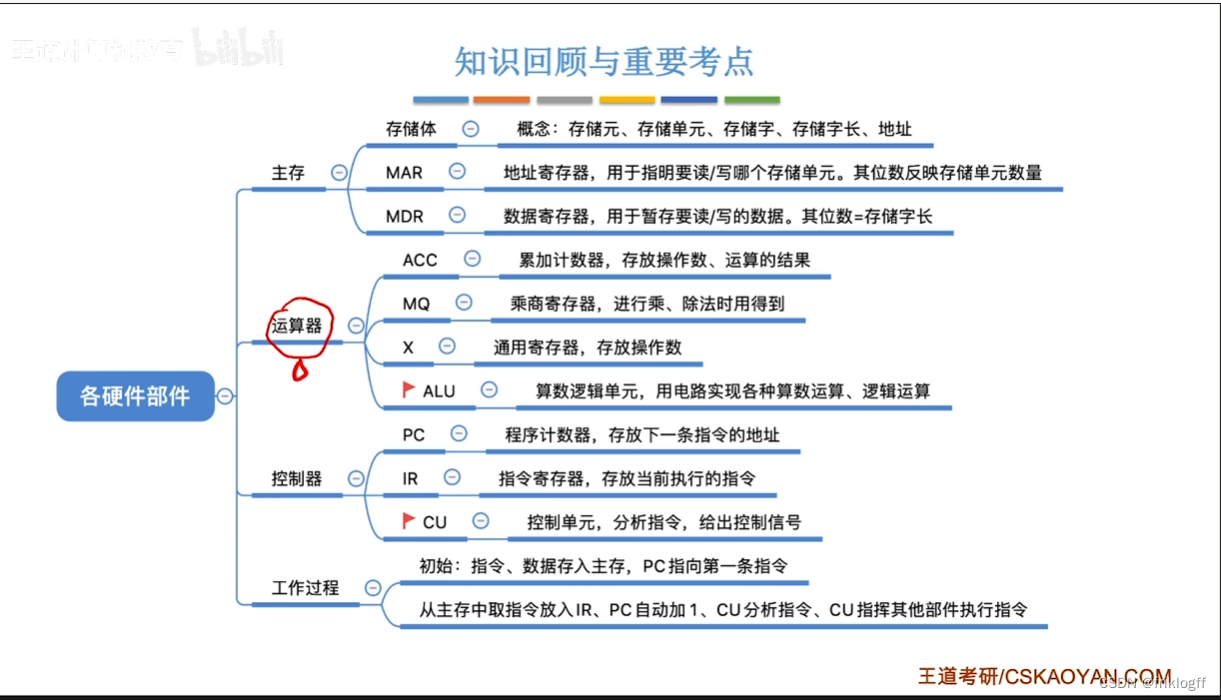
运算器的基本组成

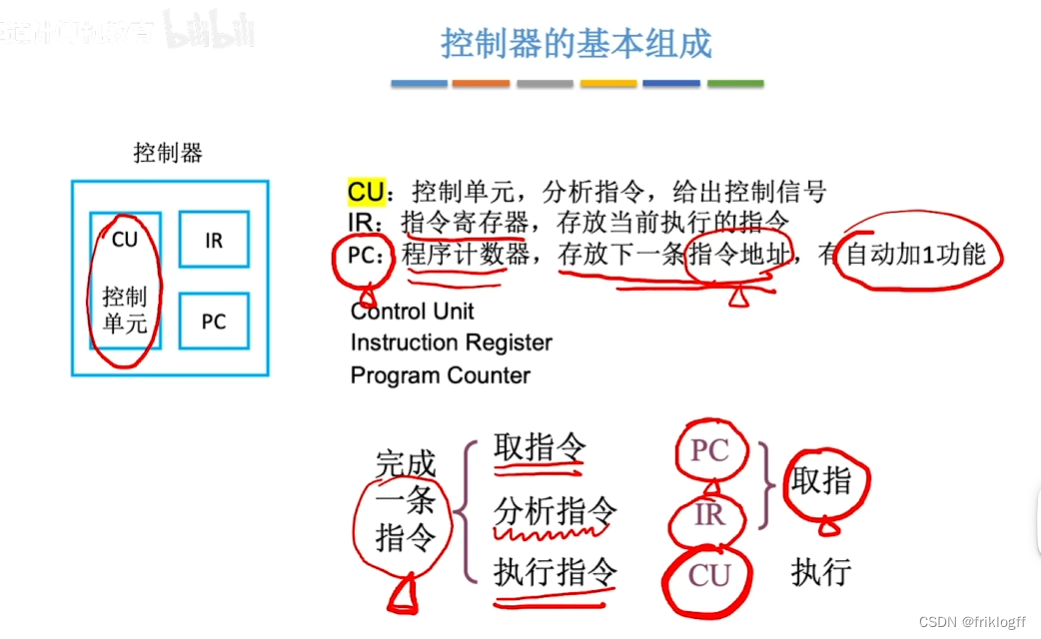
控制器的基本组成
计算机的工作过程
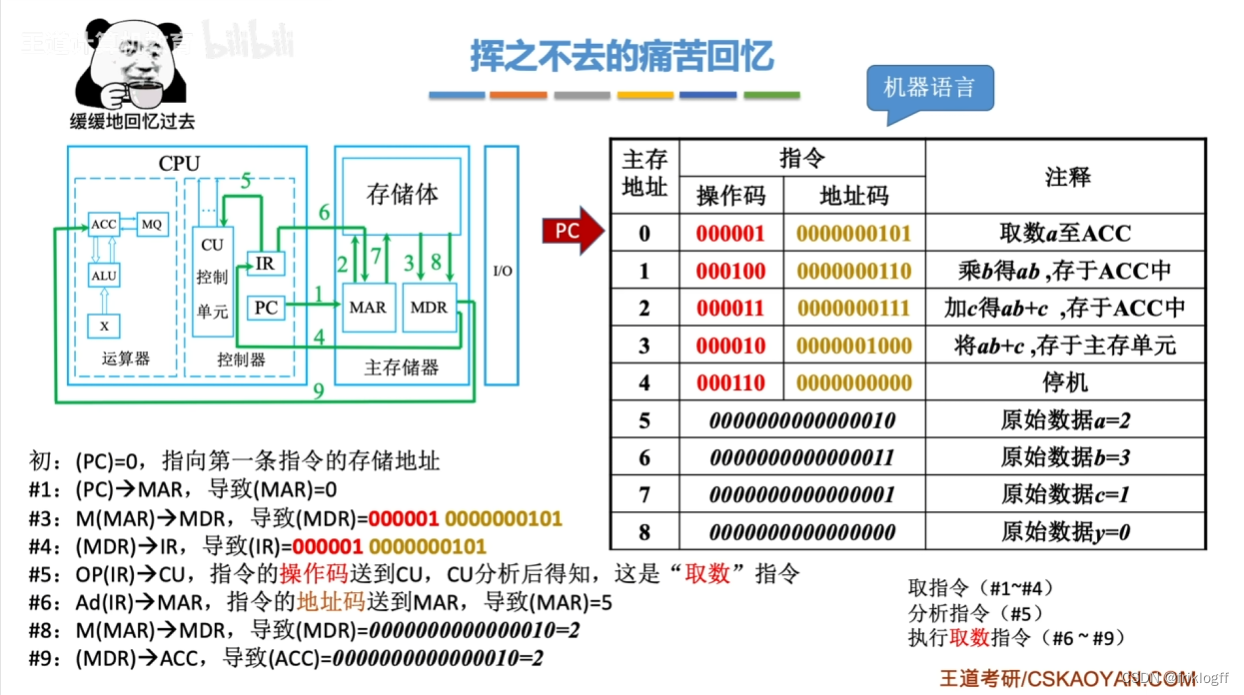
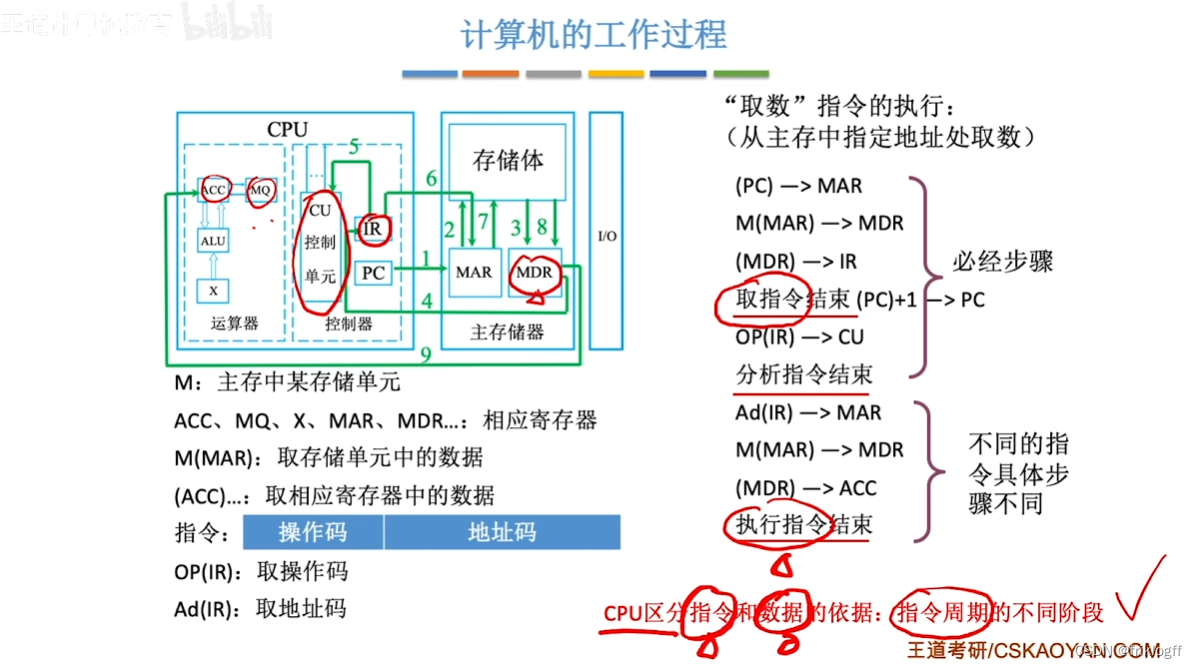
上述知识思维导图
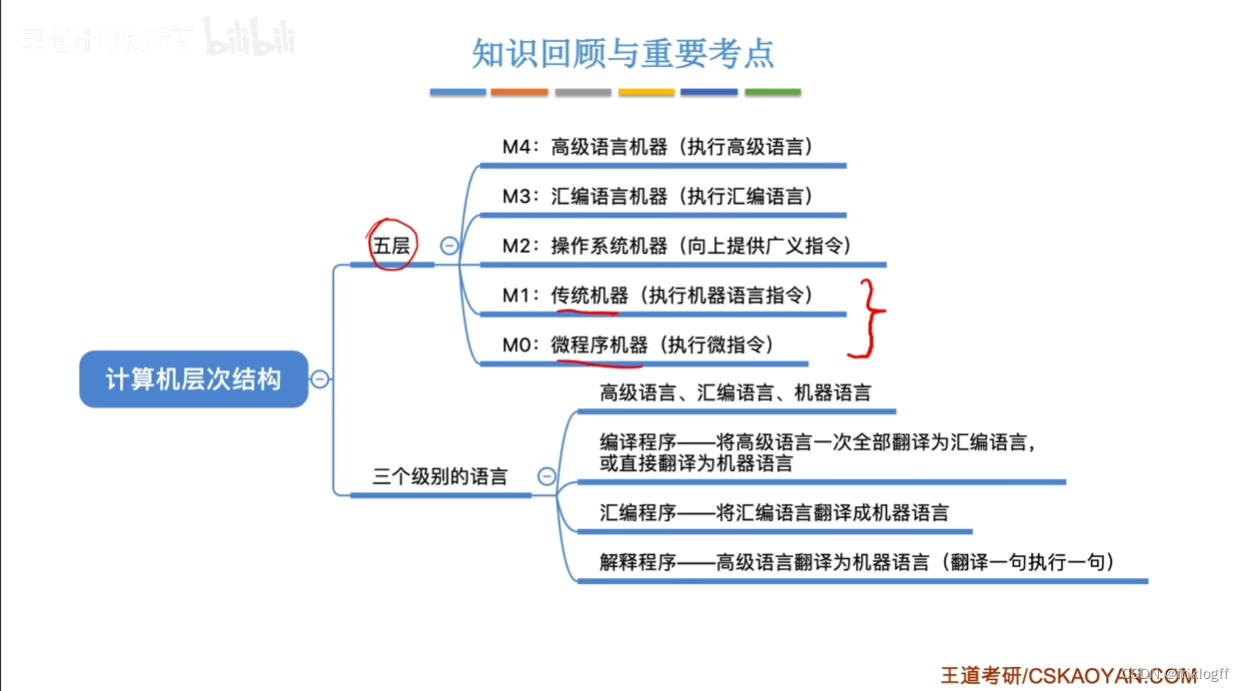
计算机系统层次结构
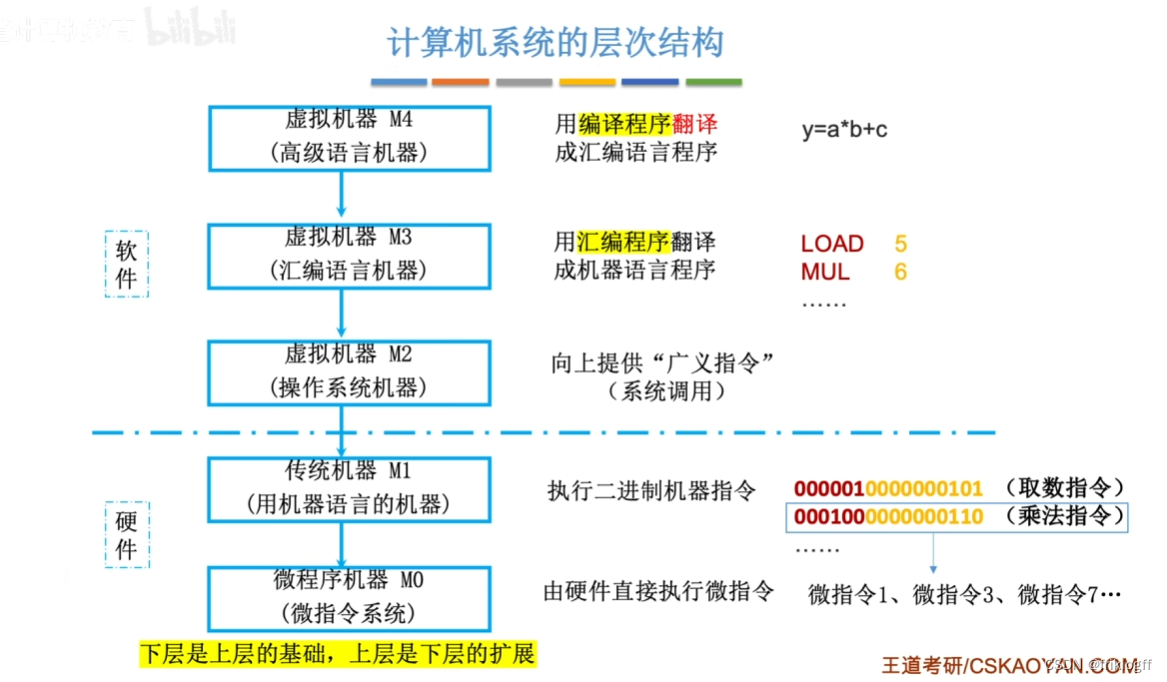
计算机语言
机器语言
- 计算机唯一可以直接识别和执行的语言,机器指令由二进制表示
汇编语言
高级语言
-
面向算法描述,一条语句对应多条指令,有“面向过程”与“面向对象”之分
-
处理逻辑:顺序结构、选择结构、循环结构
-
高级语言开发程序环境
-
语言处理系统
-
语言处理程序:编辑器+翻译转换软件
-
编译方式:预处理程序、编译器、汇编器、链接器
-
程序的转换处理过程
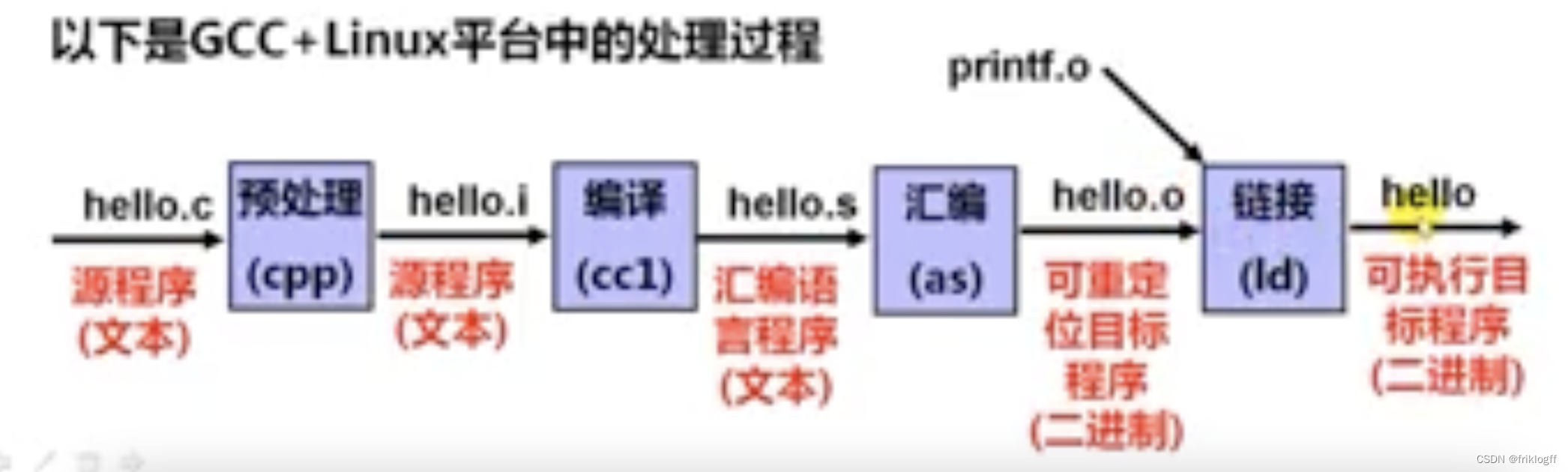
-
解释方式:解释程序
-
-
语言的运行时系统
-
-
操作系统(人机接口+操作系统内核)、指令集体系结构、计算机硬件
-
三种语言联系
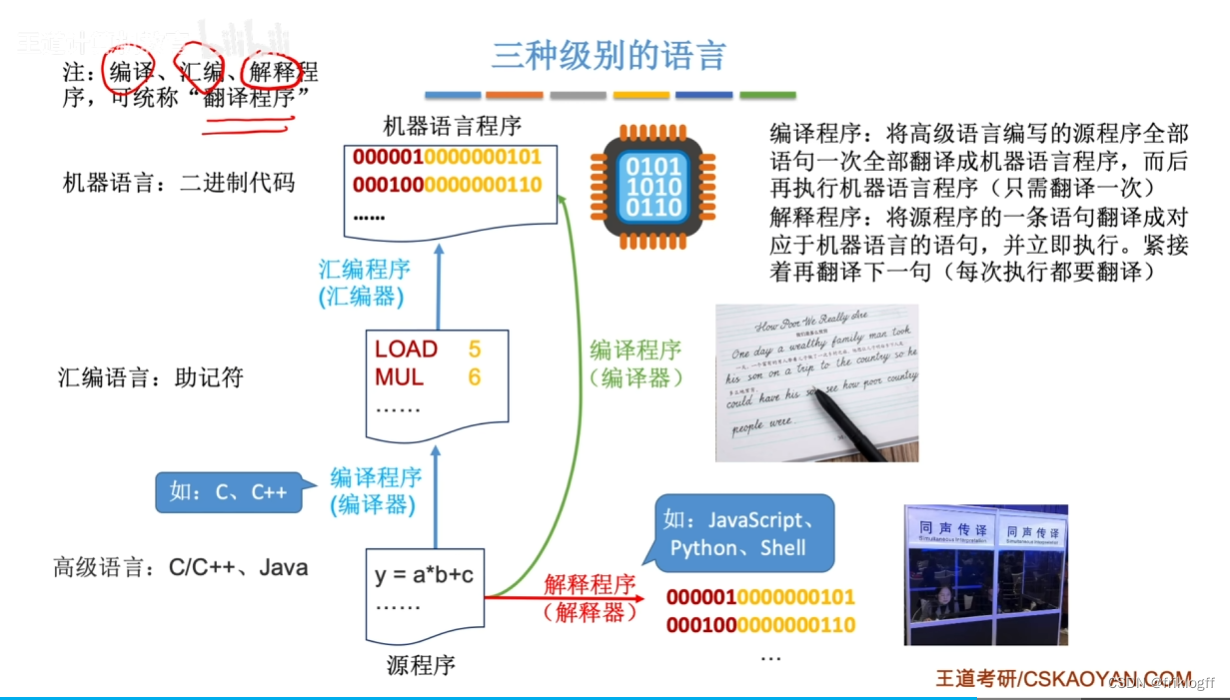
翻译程序
-
汇编程序:汇编语言源程序->机器语言目标程序
-
编译程序:高级语言源程序->汇编/机器语言目标程序,执行时只要启动目标程序即可
-
解释程序:将高级语言语句逐条翻译成机器指令并立刻执行,不生成目标文件
编译程序和解释程序重点在有没有生成目标文件,最终都转换为机器语言。
不同层次语言之间的等价转换
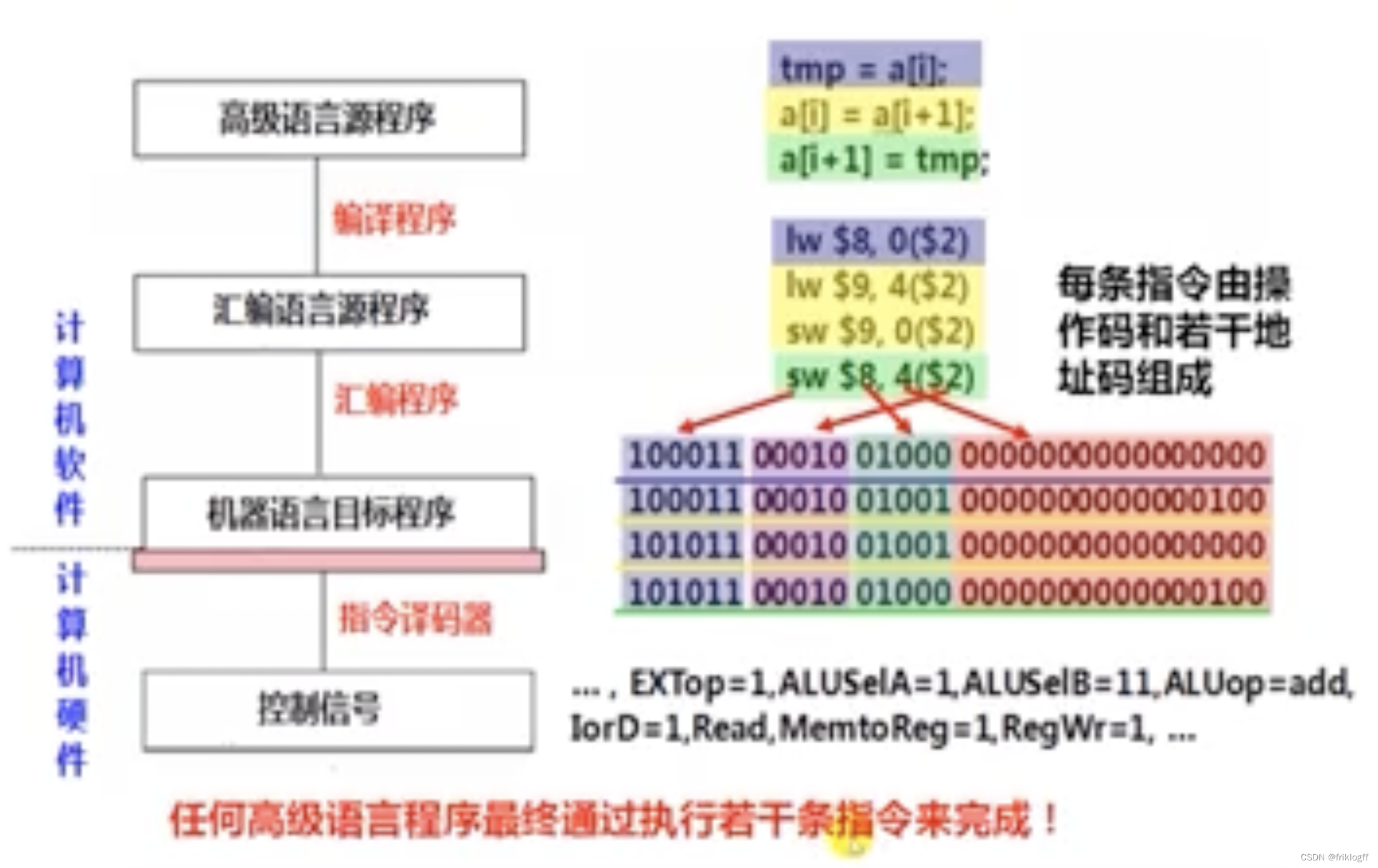
现代(传统)计算机系统层次

上述知识思维导图
计算机性能指标
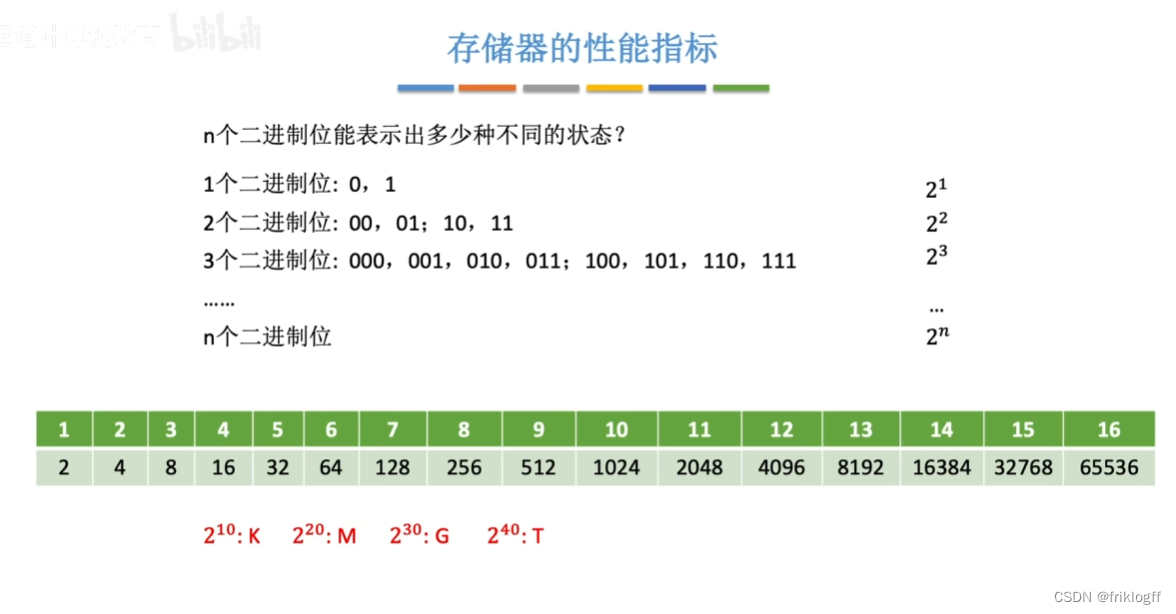
存储器的性能指标
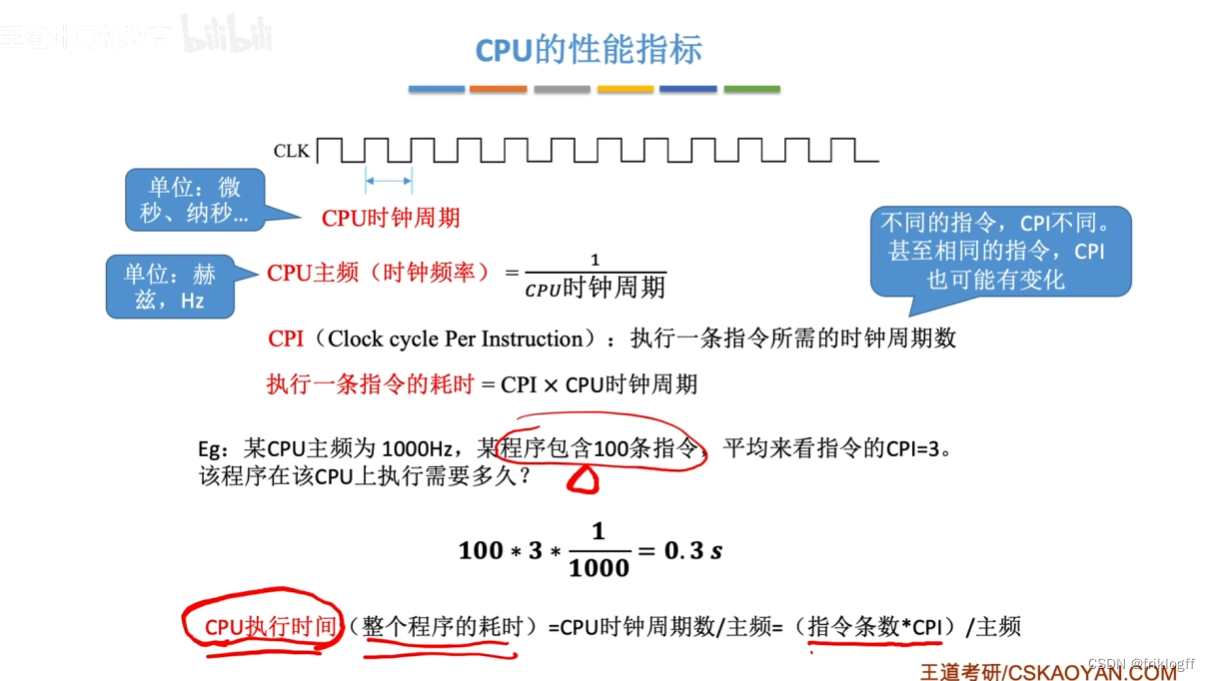
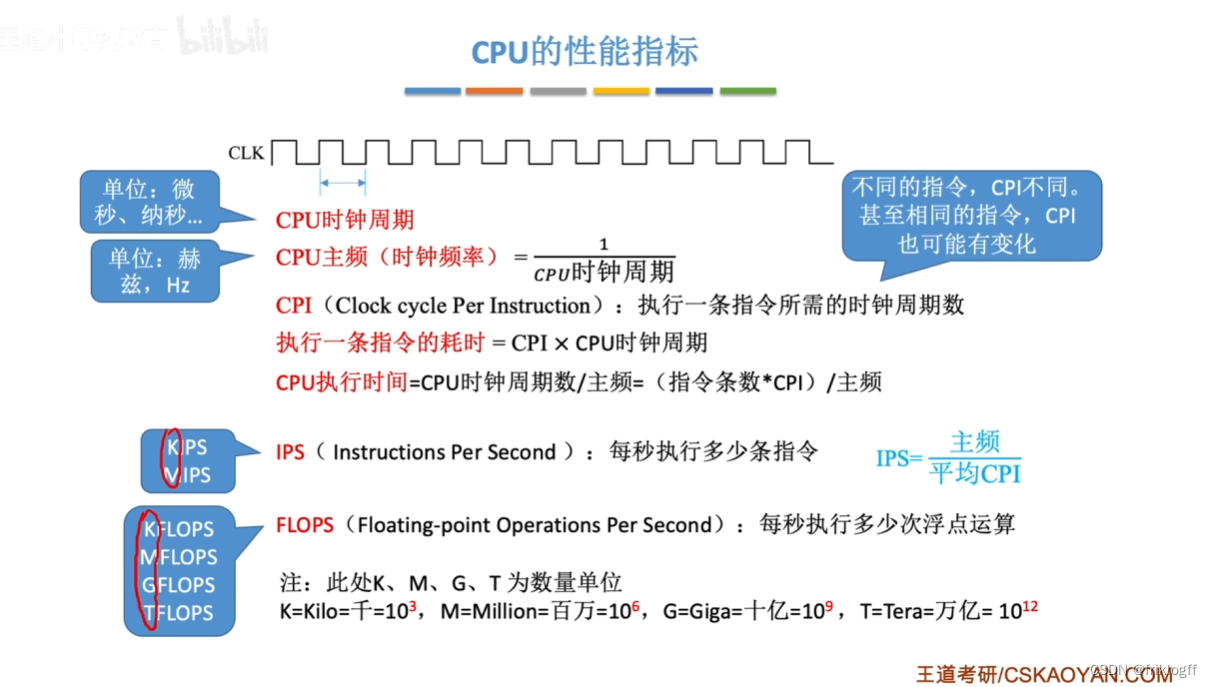
CPU的性能指标
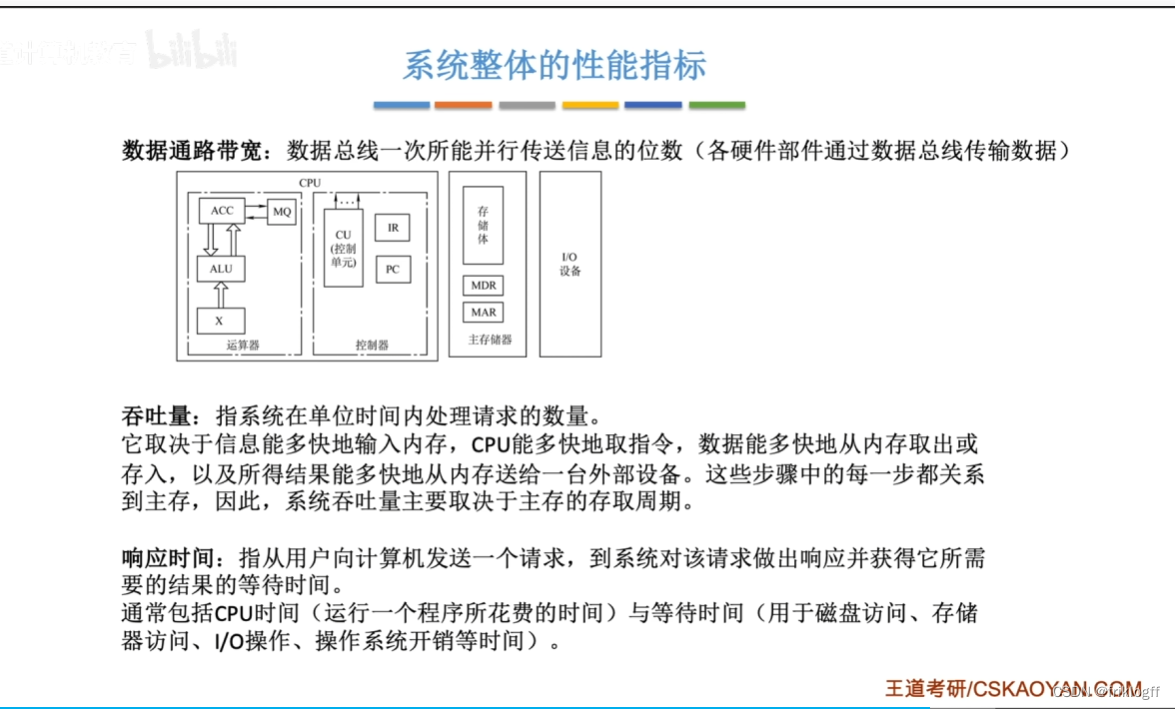
系统整体的性能指标
字长(都得是字节的整数倍)
-
机器字长:指CPU内部用于整数运算的数据通路的宽度
- 等于CPU内部用于整数运算的运算器位数和通用寄存器宽度
-
指令字长:一个指令字中包含的二进制代码位数
-
存储字长:一个存储单元存储的二进制代码长度
带宽
-
数据通路带宽
- 数据总线一次性所能传送信息的位数
-
总线带宽
- 总线宽度×总线工作频率
主存容量
- 主存储器的最大容量=存储单元个数(MAR位数n,2^n)×存储字长(MDR位数)
运算速度
-
吞吐量
- 单位时间内处理请求的数量
-
响应时间
- CPU时间+等待时间(磁盘访问、储存器访问、IO操作、操作系统开销)
-
CPU时钟周期
-
CPU最小时间单位,每个动作至少需要一个时钟周期,主频倒数
- 主频
-
-
CPI
- 执行一条指令所需的时钟周期数
-
CPU执行时间
- 运行一个程序所花时间=(指令条数×CPI)/主频
-
计算能力
-
每秒执行多少条指令
- KIPS、MIPS
-
每秒执行多少次浮点运算,衡量科学计算计算机的系统性能
- KFLOPS、MFLOPS、GFLPOPS、TFLOPS、PFLOPS、EFLOPS、ZFLOPS(每个差3位)
-
整体性能指标:数据通路带宽、吞吐量、响应时间
思考

上述知识思维导图
补充术语
-
兼容机(系列机):相同或相似的指令集,相同或相似的操作系统(指令系统向后兼容)
-
兼容:计算机软件或硬件通用性,通常在同一系列不同型号的计算机间通用
-
软件可移植性:某系列中计算机软件,直接或很少修改,运行在另一个系列中
-
固件:将程序固定在ROM中的部分
相关习题
1. 关于计算机系统层次结构
(1) 冯·诺依曼计算机中指令和数据的存储区分依据是?
A. 指令操作码的译码结果
B. 指令和数据的寻址方式
C. 指令周期的不同阶段
D. 指令和数据所在的存储单元答案:C
基础知识:
在冯·诺依曼计算机体系结构中,指令和数据都存储在同一内存中,并且计算机的运行是通过不同的指令周期来控制的。这些不同的周期包括取指令周期、译码周期、执行周期等。因此,指令周期的不同阶段用于区分指令和数据的存储。(2) 将高级语言源程序转换为机器级目标代码文件的程序是?
A. 汇编程序
B. 链接程序
C. 编译程序
D. 解释程序答案:C
基础知识:
将高级语言源程序转换为机器级目标代码文件的程序是编译程序。编译程序将高级语言代码翻译成机器可以执行的目标代码,而不需要每次运行都重新翻译。(3) 计算机硬件能够直接执行的程序类型是?
I. 机器语言程序
II. 汇编语言程序
III. 硬件描述语言程序A. 仅 I
B. 仅 I、II
C. 仅 I、III
D. I、II、III答案:A
基础知识:
计算机硬件能够直接执行的程序类型是机器语言程序。机器语言是计算机可以理解和执行的二进制指令。(4) 关于冯·诺依曼计算机基本思想的叙述中,错误的是?
A. 程序的功能都通过中央处理器执行指令实现
B. 指令和数据都用二进制数表示,形式上无差别
C. 指令按地址访问,数据都在指令中直接给出
D. 程序执行前,指令和数据需预先存放在存储器中答案:C
基础知识:
在冯·诺依曼计算机中,指令和数据都用二进制数表示,形式上无差别。指令按地址访问,而数据需要在存储器中存放并通过地址访问。(5) 将高级语言源程序转换为可执行目标文件的主要过程是?
A. 预处理→编译→汇编→链接
B. 预处理→汇编→编译→链接
C. 预处理→编译一链接→汇编
D. 预处理→汇编→链接→编译答案:A
基础知识:
将高级语言源程序转换为可执行目标文件的主要过程通常包括预处理、编译、汇编和链接。这是编译器工作的一般步骤。首先进行预处理,然后编译成汇编代码,接着汇编成机器码,最后通过链接生成可执行目标文件。2. 关于计算机的性能指标
(1) 下列选项中,能缩短程序执行时间的措施是?
I. 提高 CPU 时钟频率
II. 优化数据通路结构
III. 对程序进行编译优化A. 仅Ⅰ和 II
B. 仅Ⅰ和 III
C. 仅Ⅱ和 II
D. I、II、III答案:D
基础知识:
提高 CPU 时钟频率(主频)可以缩短完成指令的一个执行步骤所需的时间,从而加快指令的执行速度,因此选项 I 正确。优化数据通路结构可以提高计算机系统的吞吐量,加快数据传输和处理的速度,从而缩短程序的执行时间,因此选项 II 正确。
对程序进行编译优化可以生成更有效率的机器代码,减少指令的执行次数和提高数据局部性,从而降低程序的执行时间,因此选项 III 正确。
综上所述,选项 D 包括了所有能够缩短程序执行时间的有效措施。
(2) 下列选项中,描述浮点数操作速度指标的是?
A. MIPS
B. CPI
C. IPC
D. MFLOPS答案:D
基础知识:
-
MIPS(Million Instructions Per Second): MIPS 是一种用于描述计算机指令执行速度的指标。它表示每秒执行的百万条指令数。MIPS 值越高,表示计算机执行指令的速度越快,但并未直接描述浮点数操作速度。
-
CPI(Cycles Per Instruction): CPI 是一种用于描述计算机执行指令效率的指标。它表示每条指令执行所需的时钟周期数。CPI 值越低,表示计算机执行指令的效率越高,但它也不是描述浮点数操作速度的指标。
-
IPC(Instructions Per Cycle): IPC 是一种用于描述计算机每个时钟周期内执行的指令数的指标。它与 CPI 相关,但表示的是每个时钟周期内执行的指令数,而不是每条指令执行所需的时钟周期数。IPC 值越高,表示计算机在每个时钟周期内执行更多的指令,但它也不是描述浮点数操作速度的指标。
-
MFLOPS(Million Floating Point Operations Per Second): MFLOPS 是一种用于描述计算机浮点数操作速度的指标。它表示每秒执行的百万次浮点数运算操作数。MFLOPS 值越高,表示计算机执行浮点数操作的速度越快。因此,选项 D 描述浮点数操作速度的指标是正确的。
所以,答案是D。
(3) 假定基准程序 A 在某计算机上的运行时间为 100s,其中 90s 为 CPU 时间,其余为 I/O 时间。若 CPU 速度提高 50%,I/O 速度不变,则运行基准程序 A 所耗费的时间是?
A. 55s
B. 60s
C. 65s
D. 70s答案:D
基础知识:
-
CPU 时间(CPU Time): CPU 时间表示程序在 CPU 上执行所花费的时间。它包括用户态和内核态的 CPU 时间,用于执行程序的指令。
-
I/O 时间(I/O Time): I/O 时间表示程序在等待 I/O 操作完成时所花费的时间。这包括等待数据从磁盘、网络或其他外部设备读取或写入的时间。
-
CPU 速度提高 50%: 当 CPU 速度提高 50% 时,意味着 CPU 执行指令的速度增加了 50%,也就是原来的 1.5 倍。
基准程序A的运行时间为100秒,90秒为CPU时间,10秒为I/O时间。由于CPU速度提高50%,则原来要执行90秒的任务,现在缩短为90/(1+50%)=60秒。由于I/0速度不变,则运行基准程序A所耗费的时间为10秒+60秒=70秒。
(4) 某计算机的主频为 1.2GHz,其指令分为 4 类,它们在基准程序中所占比例及 CPI 如下表所示。
指令类型 所占比例 CPI A 50% 2 B 20% 3 C 10% 4 D 20% 5 该机的 MIPS 数是?
A. 100
B. 200
C. 400
D. 600答案:C
基础知识:
-
MIPS(百万指令每秒): MIPS 是衡量计算机性能的一种指标,表示每秒钟能够执行多少百万条指令。
-
CPI(每条指令的平均时钟周期数): CPI 衡量了程序在执行时所需的平均时钟周期数。
计算MIPS数的公式为:MIPS = 主频(Hz) / (CPI × 10^6)。
根据题目中的数据,我们首先需要计算基准程序的CPI。
CPI = (50% × 2) + (20% × 3) + (10% × 4) + (20% × 5) = 1 + 0.6 + 0.4 + 1 = 3
然后,使用计算机的主频来计算MIPS数:
MIPS = 主频(1.2GHz)/ (CPI × 10^6) = 1.2 × 10^9 / (3 × 10^6) = 400
所以,该机的MIPS数为400。
(5) 程序 P 在机器 M 上的执行时间是 20s,编译优化后,P 执行的指令数减少到原来的 70%,而 CPI 增加到原来的 1.2 倍,则 P 在 M 上的执行时间是?
A. 8.4s
B. 11.7s
C. 14s
D. 16.8s答案:D
基础知识:
-
执行时间(Execution Time): 执行时间表示程序在计算机上运行所需的时间。它是程序执行的实际时间。
-
指令数(Number of Instructions): 指令数表示程序执行过程中执行的指令总数。
-
CPI(Cycles Per Instruction): CPI 表示每条指令执行所需的时钟周期数。它是衡量计算机性能的重要指标之一。
根据题意,编译优化后,程序P执行的指令数减少到原来的70%,即指令数变为原来的0.7倍。同时,CPI增加到原来的1.2倍。
新的执行时间 = 原执行时间 × 新指令数 × 新CPI
新的执行时间 = 20s × 0.7 × 1.2 = 16.8s
因此,P在M上的执行时间是16.8秒,答案是D。
(6) 假定计算机 M1 和 M2 具有相同的指令集体系结构(ISA),主频分别为 1.5GHz 和 1.2GHz。在 M1 和 M2 上运行某基准程序 P,平均 CPI 分别为 2 和 1,则程序 P 在 M1 和 M2 上运行时间的比值是?
A. 0.4
B. 0.625
C. 1.6
D. 2.5答案:C
基础知识:
-
指令集体系结构(ISA): ISA 定义了计算机体系结构中的指令集合、寄存器和数据传输方式。它是计算机硬件和软件之间的接口标准。
-
主频(Clock Frequency): 主频表示计算机的时钟频率,即每秒时钟周期数。它通常以赫兹(Hz)为单位表示。
-
CPI(Cycles Per Instruction): CPI 表示每条指令执行所需的时钟周期数。它是衡量计算机性能的重要指标之一。
根据题意,M1 的平均 CPI 为 2,M2 的平均 CPI 为 1。而主频与 CPI 之间的关系可以用以下公式表示:
执行时间 = 指令数 × CPI / 主频
对于 M1,执行时间1 = 指令数 × 2 / 1.5GHz = (2/1.5) × 指令数 秒
对于 M2,执行时间2 = 指令数 × 1 / 1.2GHz = (1/1.2) × 指令数 秒现在我们来计算程序 P 在 M1 和 M2 上运行时间的比值:
程序 P 在 M1 上的执行时间 / 程序 P 在 M2 上的执行时间 = (2/1.5) × 指令数 / ((1/1.2) × 指令数)
指令数可以约掉,于是比值为:
(2/1.5) / (1/1.2) = (2/1.5) × (1.2/1) = 2.4/1.5 = 1.6
因此,程序 P 在 M1 和 M2 上运行时间的比值为 1.6,答案是C。
(7) 下列给出的部件中,其位数(宽度)一定与机器字长相同的是?
I. ALU
II. 指令寄存器
III. 通用寄存器
IV. 浮点寄存器A. 仅 I、II
B. 仅 I、III
C. 仅 II、 III
D. 仅 II、III、 IV答案:B. 仅 I、III
基础知识:
-
机器字长(Word Length): 机器字长是计算机体系结构中的一个重要概念,它表示计算机一次性能处理的二进制位数,通常以位(bits)为单位表示。机器字长决定了计算机的数据表示范围和性能。
-
ALU(Arithmetic Logic Unit): ALU 是计算机中的算术逻辑单元,负责执行算术和逻辑操作。ALU 的位数通常与机器字长相同,以便处理与机器字长相匹配的数据。
-
指令寄存器: 指令寄存器是用于存储当前正在执行的指令的寄存器。它通常存储一条机器指令,而机器指令的位数与机器字长相匹配。
-
通用寄存器: 通用寄存器是计算机中用于存储临时数据的寄存器,通常用于执行算术和逻辑运算。通用寄存器的位数通常与机器字长相同。
-
浮点寄存器: 浮点寄存器是用于存储浮点数(实数)数据的寄存器。浮点寄存器的位数通常与浮点数的表示格式相关,可能与机器字长不同。
根据上述知识,只有 ALU 和通用寄存器的位数一定与机器字长相同,因此答案是B. 仅 I、III。其他部件的位数可能根据需要而有所不同。
(8) 2017 年公布的全球超级计算机 TOP 500 排名中,我国“神威·太湖之光”超级计算机蝉联第一,其浮点运算速度为93.0146 PFLOPS,说明该计算机每秒钟内完成的浮点操作次数约为?
A. 9.3×10^13次
B. 9.3×10^15次
C. 9.3 千万亿次
D. 9.3 亿亿次答案:D
基础知识:
PFLOPS(PetaFLOPS)表示每秒钟完成的浮点操作次数达到了10^15次。根据题目中提供的数据,神威·太湖之光超级计算机的浮点运算速度为93.0146 PFLOPS~每秒9.3×10次浮点运算,因此每秒钟完成的浮点操作次数约为9.3×10^16次。(9) 某计算机主频为1GHz,程序P运行过程中,共执行了10000条指令,其中80%的指令执行平均需1个时钟周期,20%的指令执行平均需10个时钟周期。程序P的平均CPI和CPU执行时间分别是?
A. 2.8, 28μs
B. 28, 28μs
C. 2.8, 28ms
D. 28, 28ms答案:A
基础知识
在理解和解析这个问题之前,需要了解以下基础知识:
-
主频(Clock Frequency):主频是计算机处理器(CPU)的时钟频率,通常以赫兹(Hz)为单位表示。它表示CPU每秒钟的时钟周期数。例如,如果主频为1.5 Hz,那么CPU每秒钟将执行1.5亿个时钟周期。
-
指令执行速度(IPS,Instructions Per Second):指令执行速度是计算机在单位时间内执行的指令数。它通常以GIPS(Giga Instructions Per Second)为单位表示。计算指令执行速度需要考虑主频和每条指令的平均CPI(Cycles Per Instruction)。
-
指令条数:指令条数是程序中包含的机器指令的数量。这是一个影响程序执行时间的因素。
-
用户CPU时间:用户CPU时间是指程序在CPU上执行的实际时间,通常以毫秒(ms)为单位表示。它取决于总时钟周期数和主频。
按照题意,程序P的指令总数为10000,其中80%的指令CPI为1,20%的指令CPI为10。首先计算平均CPI:
平均CPI = (80% × 1 + 20% × 10) = 2.8
计算机主频为1GHz,即1 × 10^9 Hz。现在可以计算CPU执行时间:
CPU执行时间 = 10000 × 2.8 / (1 × 10^9) = 28μs
所以,程序P的平均CPI是2.8,CPU执行时间是28μs。
以上习题多数为考研真题,我正在逐年整理中,后续会标明年份和题号
考研真题
408 - 2023
12. 计算程序执行速度和用户CPU时间
若机器M的主频为1.5 Hz,在M上执行程序P的指令条数为5 × 10^5,P的平均CPI为1.2,则P在M上的指令执行速度和用户CPU时间分别为哪个选项?
A. 0.8 GIPS, 0.4 ms
B. 0.8 GIPS, 0.4 us
C. 1.25 GIPS, 0.4 ms
D. 1.25 GIPS, 0.4 us
基础知识在理解和解析这个问题之前,需要了解以下基础知识:
-
主频(Clock Frequency):主频是计算机处理器(CPU)的时钟频率,通常以赫兹(Hz)为单位表示。它表示CPU每秒钟的时钟周期数。例如,如果主频为1.5 Hz,那么CPU每秒钟将执行1.5亿个时钟周期。
-
指令执行速度(IPS,Instructions Per Second):指令执行速度是计算机在单位时间内执行的指令数。它通常以GIPS(Giga Instructions Per Second)为单位表示。计算指令执行速度需要考虑主频和每条指令的平均CPI(Cycles Per Instruction)。
-
指令条数:指令条数是程序中包含的机器指令的数量。这是一个影响程序执行时间的因素。
-
用户CPU时间:用户CPU时间是指程序在CPU上执行的实际时间,通常以毫秒(ms)为单位表示。它取决于总时钟周期数和主频。
解析:
首先,我们需要计算程序P在机器M上的指令执行速度和用户CPU时间。以下是计算过程:
- 程序P的指令条数为5 × 10^5。
- P的平均CPI为1.2。
- 机器M的主频为1.5 Hz。
计算程序P的总时钟周期数:
总时钟周期数 = 指令条数 × 平均CPI = 5 × 10^5 × 1.2 = 6 × 10^5机器M的主频为1.5 Hz,这意味着每秒有1.5 × 10^9 个时钟周期。
现在,计算指令执行速度(IPS,Instructions Per Second):
指令执行速度 = 主频 / 平均CPI = (1.5 × 10^9) / 1.2 = 1.25 × 10^9 IPS = 1.25 GIPS最后,计算用户CPU时间:
用户CPU时间 = 总时钟周期数 / 主频 = (6 × 10^5) / (1.5 × 10^9) = 0.4 × 10^(-3) 秒 = 0.4 ms所以,程序P在机器M上的指令执行速度为1.25 GIPS,用户CPU时间为0.4毫秒(ms)。因此,答案是选项C:1.25 GIPS, 0.4 ms。
408 - 2022
12. 计算平均CPI和CPU执行时间
问题: 某计算机主频为1GHz,程序P运行过程中,共执行了10000条指令,其中,80%的指令执行平均需1个时钟周期,20%的指令执行平均需10个时钟周期。程序P的平均CPI(Cycles Per Instruction)和CPU执行时间分别是多少?
A. 2.8,28μs
B. 28,28μs
C. 2.8,28ms
D. 28,28ms
解答:
基础知识:
-
CPI(Cycles Per Instruction): CPI 表示每条指令执行所需的平均时钟周期数。它是衡量计算机性能的一个重要指标。公式为:
[CPI = \frac{\text{总时钟周期数}}{\text{执行的指令数}}]
-
CPU执行时间: CPU执行时间表示程序运行所需的时间,通常以秒为单位。
按照题意,程序P的指令总数为10000,其中80%的指令CPI为1,20%的指令CPI为10。首先计算平均CPI:
平均CPI = (80% × 1 + 20% × 10) = 2.8
计算机主频为1GHz,即1 × 10^9 Hz。现在可以计算CPU执行时间:
CPU执行时间 = 10000 × 2.8 / (1 × 10^9) = 28μs
所以,程序P的平均CPI是2.8,CPU执行时间是28μs。
正确答案是 A. 2.8,28μs。
20. 高级语言程序转换为可执行目标文件的过程
问题: 将高级语言源程序转换为可执行目标文件的主要过程是什么?
A. 预处理→编译→汇编→链接
B. 预处理→汇编→编译→链接
C. 预处理→编译→链接→汇编
D. 预处理→汇编→链接→编译
解答:
基础知识:
将高级语言源程序转换为可执行目标文件的主要过程通常包括以下步骤:
-
预处理(Preprocessing): 在这个阶段,预处理器根据预处理指令(如宏定义、条件编译等)对源代码进行处理。预处理器会展开宏定义、包含头文件等,生成经过预处理的源代码。
-
编译(Compilation): 在这个阶段,编译器将预处理后的源代码转换为汇编代码。编译器对代码进行词法分析、语法分析、语义分析,生成相应的中间代码或汇编代码。
-
汇编(Assembly): 在这个阶段,汇编器将汇编代码转换为机器码指令。汇编器将汇编代码中的每条指令翻译成机器码表示。
-
链接(Linking): 在这个阶段,链接器将各个源文件编译生成的目标文件及所需的库文件合并在一起,生成最终的可执行目标文件。链接器会解析符号引用关系,将函数和变量的引用与其定义进行匹配,并进行地址重定位等操作,使得程序能够正确地执行。
因此,正确的过程是:预处理→编译→汇编→链接,选项A是正确的。
答案是 A. 预处理→编译→汇编→链接。
拓展
例如gcc编译器将hello.c转换为可执行目标文件hello的过程如下:
对应的命令如下:
预处理:gcc -E hello.c -o hello.i
编译:gcc –S hello.i –o hello.s
汇编:gcc –c hello.s –o hello.o
链接:gcc hello.o –o hello408 - 2021
12. 计算机浮点运算速度与操作次数的关系
问题:2017 年公布的全球超级计算机 TOP 500 排名中,我国“神威·太湖之光”超级计算机蝉联第一,其浮点运算速度为93.0146 PFLOPS,说明该计算机每秒钟内完成的浮点操作次数约为?
A. 9.3×10^13次
B. 9.3×10^15次
C. 9.3 千万亿次
D. 9.3 亿亿次答案:D
基础知识:
PFLOPS(PetaFLOPS)表示每秒钟完成的浮点操作次数达到了10^15次。根据题目中提供的数据,神威·太湖之光超级计算机的浮点运算速度为93.0146 PFLOPS~每秒9.3×10次浮点运算,因此每秒钟完成的浮点操作次数约为9.3×10^16次。未完待续,逐张试卷整理中,会一直更新到2009
-
相关阅读:
GO 语言处理并发的时候我们是选择sync还是channel
超宽带uwb精准定位,厘米级室内定位技术,实时高精度方案应用
基于Python实现的负载均衡模拟(语言类综合项目实践)
Bitmap加载内存分析
我为什么写博客?写博客给我带来了什么?
实战指南:使用 xUnit.DependencyInjection 在单元测试中实现依赖注入【完整教程】
python爬取某网站的猫咪销售情况(内置源码)
Android 基础知识3-1项目目录结构
记GitLab服务器迁移后SSH访问无法生效的问题解决过程
一次搞定33种python机器学习回归算法!超级全!
- 原文地址:https://blog.csdn.net/qq_42531954/article/details/133465731