-
MIP精确算法的关键——确定界 篇一
目录
MIP精确算法包含,分支定界、分支切割、分支定价还有benders分解等等。前者是以分支定界为框架的一类算法;后者是以分解为框架的一类算法。甚至还包括拉格朗日松弛等等,我觉得除了算法细则需要搞清楚外,更关键的是弄懂界。
因为拉格朗日算法目前不熟,所以下面我具体总结分支定界的一类算法和benders分解算法界的确定原则。
本篇以min问题为例。
1.界是什么?
界包含上界UB,和下界LB。
我们做启发式算法的时候,有时候会被审稿专家提一个问题,就是你这个算法质量没有保证,所以一般我们会提供一个下界作为参考。比如:调度问题中,不相关并行机问题,我们松弛为相同的机器,以工件j在所有机器的最小加工时间
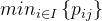 为工件的加工时间
为工件的加工时间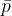 ,然后叠加就可以得到一个总完工时间,这个就可以作为原问题的下界。
,然后叠加就可以得到一个总完工时间,这个就可以作为原问题的下界。在精确算法中,我们会得到一个UB,和一个LB,不断提升LB,降低UB。当UB=LB的时候,我们就得到了最优解。换句话说,界和终止条件有关。
(1)UB是整数可行解,但我们降低UB的时候,就是找到更好可行解更新。
(2)LB是松弛解,像以分支定界为框架的一系列算法中,主要采用的是线性松弛解,因为约束减少,因此解的质量至少不差于(好于)原问题的解,原问题是min,不差于(好于)就是更小,即LB。
而拉格朗日松弛,采用的是不同于线性松弛的松弛方法,得到的LB更好,通常拉格朗日松弛的解≥线性松弛的解。
2. 如何更新上下界
当我们了解UB和LB了之后,下一个问题是:
(1)用什么来更新?以及
(2)更新的过程怎么保证不丢失信息,确保更新UB和LB之后得到的是精确最优解呢?
2.1 以分支定界为框架的一系列算法
先来说以分支定界为框架的一系列算法:
它的本质是隐枚举,通过剪支的操作来避免全枚举。剪支分为:不可行剪支(线性松弛后可行域变大了还不可行,那可行域是子集的原问题必定也不可行)、最优性剪支(已经是整数解了,没必要分支了)、和定界剪支(因为线性松弛后解更小,当线性松弛后解超过了UB,那肯定不松弛解更超过UB,也就是不会产生更好的解了)。
可以看到定界剪支与界(准确的说是LB)相关,以及我们在求解过程中需要不断更新,和比较UB和LB,因此界很重要。
编程的时候怎么实现呢?
我们需要定义一系列的界,包含全局UB&LB(上面说的都是这个);以及当前节点的UB&LB(为了比较和替换,也是为了更清晰的展示每个点的上下界信息);以及储存在每次迭代过程中UB&LB(比如我们想查看上下界怎么变化,就需要用到它,智能算法中显示全局解随迭代次数变化的迭代曲线一样的意思)。
总结一下,需要用到global_UB,global_LB;node.local_LB,node.local_UB,以及Global_UB_change,Global_LB_change。
后续我们需要对以上变量进行更新,具体的做法是:
(1)首先肯定是要预定义:
global_UB=正无穷,global_LB=原问题线性松弛的解;
node.local_LB=global_LB,node.local_UB=正无穷;
Global_UB_change=[],Global_LB_change = [].
(2)求解每一个叶子节点current_node,会得到它的解current_node.model.ObjVal。
(3)假如是整数解,且该解比之前可行解都好,即current_node.model.ObjVal
假如不是整数解,即小数解,不需要进行任何操作。
- # update the LB and UB
- if (is_integer == True):
- feasible_sol_cnt += 1 # 整数可行解的计数
- # For integer solution node, update the LB and UB
- current_node.is_integer = True
- current_node.local_LB = current_node.model.ObjVal
- current_node.local_UB = current_node.model.ObjVal
- # if the solution is integer, update the UB of global and update the incumbent
- if (current_node.local_UB < global_UB): # 整数可行解更优,更min,则更新上界,同时更新当前最好的整数可行解incumbent_node
- global_UB = current_node.local_UB
- incumbent_node = Node.deepcopy_node(current_node)
- if (is_integer == False):
- # For integer solution node, update the LB and UB also
- current_node.is_integer = False
- current_node.local_UB = global_UB
- current_node.local_LB = current_node.model.ObjVal
(可以看到每个点current_node的下上界信息也进行了更新,是为了展示各个节点的上下界情况。整数节点,上下界相等,都为current_node.model.ObjVal;非整数节点,上界为global_UB,下界为本身(因为是松弛解))。
(4)因为我们在分支的时候,把所有的子节点(一系列模型)放在队列Queue中 ,因此我们探测这些叶子节点的信息,来更新全局下界(是所有叶子节点解的最小值)>>>>(是保证不缺失信息的关键)。
注意:上界UB可以用更好的可行解信息来代替,但是下界LB不能,下界LB要全部探测所有节点方可确定。
- # update the global LB, explore all the leaf nodes
- temp_global_LB = np.inf
- for node in Queue:
- node.model.optimize()
- if (node.model.status == 2):
- if (node.model.ObjVal <= temp_global_LB and node.model.ObjVal <= global_UB):
- temp_global_LB = node.model.ObjVal # 下界是剩余节点集合Q中节点对应的LP中obj的最小值
(5)更新全局LB和UB,更新界的迭代信息列表Global_UB_change,Global_LB_change
- global_LB = temp_global_LB
- Global_UB_change.append(global_UB)
- Global_LB_change.append(global_LB)
可以看到,全局UB直接更新(出现好的就更新,类似于我们说的贪婪更新),而下界LB是探测所有。 然后把每次迭代过程中的全局UB和LB放在界的迭代列表Global_UB_change,Global_LB_change中,因为我们在先前已经比较过了,因此LB一定是增大(因为我们不断添加界,相当于可行域变小,所以即使探测所有节点,解一定是变大的,不会出现更小的情况),UB一定是减小的。
(6)当所有节点都探测完毕,别忘了再更新下全局上下界和界的迭代信息列表。
- # all the nodes are explored, update the LB and UB
- incumbent_node.model.optimize()
- global_UB = incumbent_node.model.ObjVal
- global_LB = global_UB
- Gap = round(100 * (global_UB - global_LB) / global_LB, 2)
- Global_UB_change.append(global_UB)
- Global_LB_change.append(global_LB)
我们知道分支切割,和分支定价是在分支定界的基础上进行的,界的更新过程差不多。区别是分支数的样子。
2.2 benders分解
benders分解的初衷是因为原模型中含有两类变量,复杂变量和简单变量。它们之间具有耦合关系,所以我们想的是把它们拆开,复杂变量和简单变量分开,分成两个问题/模型,即我们说的主问题和子问题。但分开后的两个模型之间要建立一定的联系,才能和原模型等价。具体的做法是加约束(可行割和最优割),即缺失的信息。也就是说原模型等价于主问题+一系列的割。这些割是不断添加的,因此benders分解被也称为行生成。
所以我们可以看到,benders分解的关键在于,如何分解为主问题和子问题。以及界是如何更新的。
本篇我们主要谈界的更新,benders算法中界主要和算法终止条件有关。以下谈具体思路。
假设复杂变量是y,简单变量是x。
(1)则主问题MP是只看y,无视/忽略x(x相关的信息,即x对y的影响反映在不断添加的割上),目标函数是min(fy+q),其中q是原始模型中目标函数min(fy+cx)中关于x的部分cx的下界;
(2)子问题SP是给了一个具体的y_bar后关于x的模型,目标函数是min(cx)。
以下是关于UB和LB的详细说明:
(1)因为子问题是给一个具体的y_bar后求解的得到x值的模型,因此该解必定是原问题的一个可行解,也就是子问题给出了一个上界UB=fy+Q(y)。
注:子问题的Q(y)其实子问题对偶问题的目标函数值。当子问题对偶问题最优,即子问题最优,目标函数值是相同的。
(2)再来考虑主问题,因为忽略了x,也就是对问题进行了松弛,并没有把x对y的影响全部加回来,即约束少,可行域变大(本质是松弛),因此解不弱于原来模型的解,即主问题给出了一个下界LB=fy+q。
(3)当上界UB=下界LB时,fy+Q(y)=fy+q,也就是Q(y)=q。因此判断原问题是否最优的方法是:查看主问题的q取值和子问题的Q(y)取值是否相同。
a) 当子问题最优时,即得到了一个可行解,UB=min{UB, fy+Q(y)};
b) 添加割后求解主问题,得到的就是LB。
-
相关阅读:
C/S架构学习之TCP客户端
怎样查询服务器位置和IP地址?
C++模拟鼠标键盘操作
基于CentOS 7.9离线安装CM6.3.1和CDH6.3.2大数据平台
如何使用 WPF 应用程序连接 FastReport报表
DFS与回溯专题:二叉树的最大深度
BUG:阿里巴巴图标库引入链接后,icon有时候会不显示的话svg下载到本地使用
ArcPy批量对大量遥感影像相减做差
Linux定时任务切割日志
RabbitMQ 入门系列:7、保障消息不重复消费:产生消息的唯一ID。
- 原文地址:https://blog.csdn.net/sinat_41348401/article/details/133513906
