-
BIT-6自定义类型和动态内存管理(11000字详解)
一:自定义类型
1.1:结构体
在生活中,基本数据类型可以描述绝大多数的物体,比如说名字,身高,体重,但是还有一部分物体还不足够被描述,比如说我们该如何完整的描述一本书呢?包括书的名字,价格,作者。页数,等等,由此便有了结构体这个概念
C语言中的结构体是一种自定义的数据类型,它允许我们将不同类型的数据组合在一起,形成一个逻辑上相关的数据单元。结构体可以包含不同的数据类型,如整型、字符型、浮点型、指针等,并且可以根据需要添加多个成员变量。
结构体的定义使用关键字struct,后面跟着结构体的名称和花括号。在花括号中定义结构体的成员变量,每个成员变量由数据类型和名称组成,中间用分号分隔。
例如,下面是一个定义了一个简单的学生结构体的例子:
struct Student { int id; char name[20]; float score; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中Student是结构体的名字,
int id; char name[20]; float score;- 1
- 2
- 3
是结构体的成员
1.1.1结构体成员的赋值
当我们想要给结构体成员赋值时,我们可以使用点操作符(
.)或箭头操作符(->),具体取决于我们的操作对象是结构体变量还是指向结构体的指针。结构体成员的访问有两种方式:
- 第一是通过 . 操作符
- 第二是通过 ->操作符
下面是代码示例:
#includestruct Stu { char name[20]; int age; char sex[5]; char id[15]; }; int main() { struct Stu s = { "张三", 20, "男", "20180101" }; printf("name = %s age = %d sex = %s id = %s\n", s.name, s.age, s.sex, s.id); struct Stu* ps = &s; printf("name = %s age = %d sex = %s id = %s\n", ps->name, ps->age, ps->sex, ps -> id); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
当声明结构体的同时声明变量并进行初始化时,可以使用以下方式:
struct Student { int id; char name[20]; float score; } sn1 = { 123456, "John Doe", 85.5 };- 1
- 2
- 3
- 4
- 5
在上述代码中,我们声明了一个名为
Student的结构体,并创建了名为sn1的变量。同时,我们使用大括号{ }初始化了sn1的成员变量。sn1.id被初始化为123456sn1.name被初始化为"John Doe"sn1.score被初始化为85.5
请注意,结构体变量的初始化方式与结构体成员的顺序要相同,如果不想相同的话可以这样:
struct Student { int id; char name[20]; float score; } sn1 = { .score = 85.5, .name = "John Doe", .id = 123456};- 1
- 2
- 3
- 4
- 5
注意:
#includestruct Student { int id; char name[20]; float score; }; int main() { Student sn1 = { 123456, "John Doe", 85.5 }; //这是错的 struct Student sn1 = { 123456, "John Doe", 85.5 };//这才是正确的 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1.1.2结构体的自引用
下面请问代码1和代码2哪个是正确的:
//代码1 struct Node { int data; struct Node next; }; //代码2 struct Node { int data; struct Node* next; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在结构体中包含一个类型为该结构本身的成员是不可以的
第一个代码是错误的,因为在结构体Node中,next成员的类型是"struct Node"。这将导致结构体Node的大小无限增长,因为结构体包含一个嵌套的结构体实例,而嵌套的结构体实例也包含一个嵌套的结构体实例,以此类推。这会导致无限递归,使结构体的大小变得无法确定。
第二个代码是正确的。在结构体Node中,next成员的类型是指针类型"struct Node*"。这意味着next成员存储的是指向下一个结构体Node的指针,而不是实际的结构体实例。通过使用指针类型,可以避免无限递归并确保结构体的大小是固定的。
下面再来看一个代码:
//代码3 typedef struct { int data; Node* next; }Node; //代码4 typedef struct Node { int data; struct Node* next; }Node;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
代码3是错误的,因为在结构体定义中使用Node* next;时,编译器尚未知道Node的定义。在代码3中,Node只是一个未知的标识符,编译器错误地指示Node未定义。
代码4是正确的,因为在结构体内部使用struct Node* next;,这样编译器可以识别Node作为结构体类型的名称,并分配正确的内存空间。这样做允许了自引用结构体,因为指针变量next指向同一类型的结构体。
因此,代码4是正确的方式来定义自引用结构体。
1.1.3 结构体内存对齐
我们都知道,在c语言中,一个int类型占4字节,一个char类型占1字节,那么对于一个结构体,我们该如何知道它的大小呢?下面看一段代码:
int main() { struct S3 { double d; char c; int i; }; printf("%d\n", sizeof(struct S3)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们可能会觉得,double占8字节,char占1字节,int占4字节,那么这个结构体就应该占13个字节,事实真的是这样吗?请看运行结果:

下面讲解一下c语言的内存对齐规则:-
第一个成员在与结构体变量偏移量为0的地址处。
-
其他成员变量要对齐到对齐数的整数倍的地址处。
-
对齐数 = 编译器对齐数默认值与该成员大小的较小值。
-
VS中默认的值为8
-
结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
-
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
下面通过例子讲解:
int main() { //练习1 struct S1 { char c1; int i; char c2; }; printf("%d\n", sizeof(struct S1)); //练习2 struct S2 { char c1; char c2; int i; }; printf("%d\n", sizeof(struct S2)); //练习3 struct S3 { double d; char c; int i; }; printf("%d\n", sizeof(struct S3)); //练习4-结构体嵌套问题 struct S4 { char c1; struct S3 s3; double d; }; printf("%d\n", sizeof(struct S4)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
运行结果是:
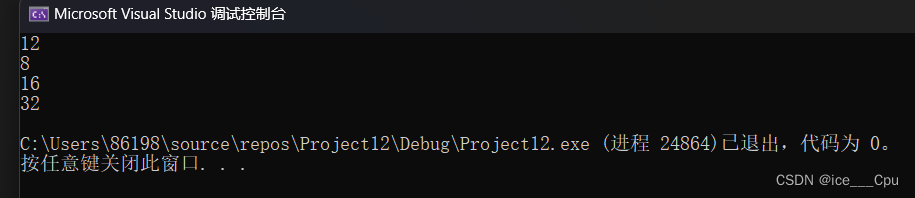
下面进行讲解:
1:首先,第一个成员在0偏移量处,所以把c1放在0处
2:接着,其他成员要对齐到对齐数上,vs默认对齐数是8,而int是4字节,所以int的对齐数是4,i要放在4开头处
3:同样的,c2放在8开头处,
4:所以整个的大小为9,结构体中的最大对齐数是4,9不是4的倍数,所以要提升到12
5:所以结果为12
1:首先,第一个成员在0偏移量处,所以把c1放在0处
2:同样的,c2放在1开头处,
3:接着,其他成员要对齐到对齐数上,vs默认对齐数是8,而int是4字节,所以int的对齐数是4,i要放在4开头处
4:所以整个的大小为8,结构体中的最大对齐数是4,8刚好是4的倍数
5:所以结果为8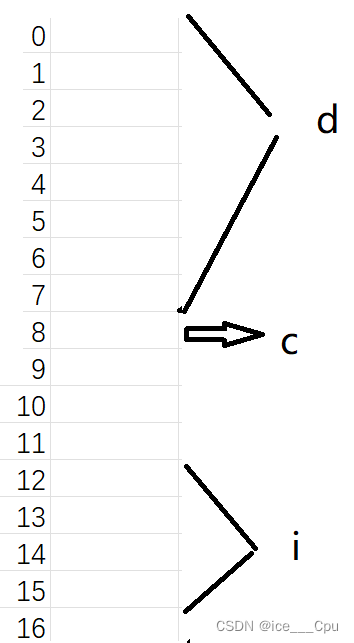
1:首先,第一个成员在0偏移量处,所以把d放在0处
2:同样的,c放在8开头处,
3:接着,其他成员要对齐到对齐数上,vs默认对齐数是8,而int是4字节,所以int的对齐数是4,i要放在12开头处
4:所以整个的大小为16,结构体中的最大对齐数是8,16刚好是8的倍数
5:所以结果为16
1:首先,第一个成员在0偏移量处,所以把c1放在0处
2:结构体的对齐数是是这个结构体中的最大对齐数,由上一题可以知道是8
3:所以结构体放在8开头的地方,长度为16
4:d的对齐数为8,所以要放在24处,长度为8
5:所以和为32,这个结构体中最大的对齐数是16,32刚好是16的倍数1.1.3.1修改默认对齐数
在C语言中,我们可以使用
#pragma pack指令来设置对齐规则。该指令会告诉编译器按照指定的对齐数对结构体进行对齐。对齐数可以是任何正整数,代表以字节为单位的对齐要求。下面是一个使用
#pragma pack指令修改默认对齐数的示例:#pragma pack(1) // 设置对齐数为 1 字节 struct MyStruct { char a; int b; char c; }; #pragma pack() // 恢复默认对齐数 int main() { // 访问结构体中的成员 struct MyStruct s; s.a = 'A'; s.b = 10; s.c = 'C'; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在上面的示例中,我们使用
#pragma pack(1)将对齐数设置为1字节,即无论成员的类型大小为多少,都按照1字节对齐。这样可以确保结构体中的每个成员都以最小的内存开销进行对齐。然后,我们使用#pragma pack()恢复默认对齐数。需要注意的是,修改默认对齐数可能会影响性能和可移植性。因此,在实际开发中,我们应该谨慎使用,并确保了解目标系统的对齐需求和编译器的默认规则。
并且对齐数一般都是2的次方,1,2,4,8,16等等
1.1.4 结构体传参
struct S { int data[1000]; int num; }; struct S s = { {1,2,3,4}, 1000 }; //结构体传参 void print1(struct S s) { printf("%d\n", s.num); } //结构体地址传参 void print2(struct S* ps) { printf("%d\n", ps->num); } int main() { print1(s); //传结构体 print2(&s); //传地址 return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
上面的 print1 和 print2 函数哪个好些?
答案是:首选print2函数。
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。所以结构体传参的时候,最好要传结构体的地址。
1.2 位段
C语言中的位段(bit-fields)是一种特殊的数据类型,用于在结构体中按位对内存进行分配。通过位段,我们可以灵活地定义和操作数据的位级别细节,例如位宽和位域的顺序。
位段的语法形式如下:
struct { type fieldName : width; };- 1
- 2
- 3
其中,
type表示位段的数据类型,必须是int、unsigned int、signed int其中一种;fieldName是位段的名称;width表示位域的宽度,即占用的位数。位段的主要作用是优化内存空间的利用,可以用较少的位数占用更少的内存。在结构体中,位段可以按照成员的顺序进行紧凑排列,节省内存空间。
下面是一个示例代码,说明了如何使用位段:
#includestruct { unsigned int flag1 : 1; unsigned int flag2 : 2; unsigned int flag3 : 3; } myFlags; int main() { myFlags.flag1 = 1; myFlags.flag2 = 2; myFlags.flag3 = 3; printf("flag1: %d\n", myFlags.flag1); printf("flag2: %d\n", myFlags.flag2); printf("flag3: %d\n", myFlags.flag3); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在上述代码中,定义了一个匿名结构体,其中包含了三个位段
flag1、flag2和flag3。flag1占用1位,flag2占用2位,flag3占用3位。在
main函数中,我们对这些位段进行赋值,并使用printf函数输出它们的值。输出结果为:flag1: 1 flag2: 2 flag3: 3- 1
- 2
- 3
这说明了位段可以正常工作,并且按照指定的位宽正确地进行赋值和输出。
需要注意的是,位段的使用具有一定的限制。由于位宽是有限的,因此不能超过位宽所能表示的范围。此外,位段的行为在不同的编译器和平台上可能有所差异,因此在使用时应该注意兼容性。
例如:
flag1的位数是1,那么它的取值就只有2种(0或者1)
flag2的位数是2,那么它的取值只有4种(0 ~ 3)
flag3的位数是3,那么它的取值只有8种(0 ~ 7)注意:
- 位宽不能超过所属类型的位数。比如,int类型一般有32位,因此不能超过32位。
- 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
位段大小的计算:
位段每次开辟空间是以int(4字节)或者char(1字节)来开辟空间的,当我们将位段中所有成员的位数加起来,小于等于32,那么这个位段就是4字节,同理,大于32小于64,就是8字节,大于64小于96就是12字节,以此类推
1.3:联合(共用体)
当涉及到在 C 语言中共享内存的需求时,联合(Union)是一个非常有用的工具。联合允许不同的数据类型共享相同的内存空间,这意味着它们可以在相同的内存位置存储不同的值。在这个过程中,联合的大小将取决于其最大成员的大小。
下面是一个简单的代码示例来说明联合的使用:
#include// 定义一个联合 union Data { int i; float f; char str[20]; }; int main() { union Data data; // 声明一个联合变量 printf("Memory size occupied by data : %d\n", sizeof(data)); data.i = 10; // 设置 data 的整数成员 printf("data.i : %d\n", data.i); data.f = 220.5; // 设置 data 的浮点数成员 printf("data.f : %f\n", data.f); strcpy(data.str, "C Programming"); // 设置 data 的字符串成员 printf("data.str : %s\n", data.str); printf("Memory size occupied by data : %d\n", sizeof(data)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
运行结果如图所示:
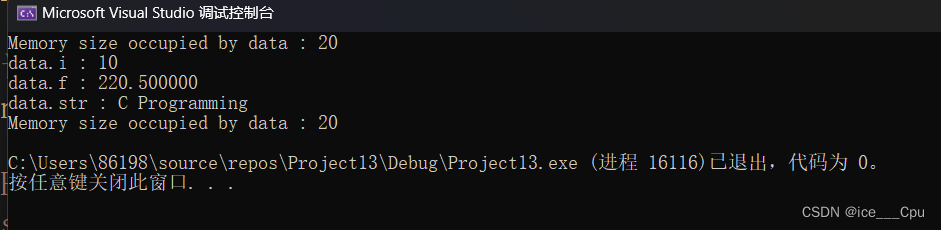
请注意,当我们设置一个成员的值后,其他成员的值就会发生改变,因为它们共享同一内存空间。这也是为什么在打印
data.str之后,你会看到data.i和data.f的值改变了。二:动态内存管理
首先为什么存在动态内存分配,它的需求是什么?我们已经掌握的内存开辟方式有:
int val = 20;//在栈空间上开辟四个字节 char arr[10] = {0};//在栈空间上开辟10个字节的连续空间- 1
- 2
但是上述的开辟空间的方式有两个特点:
- 空间开辟大小是固定的。
- 数组在申明的时候,必须指定数组的长度,它所需要的内存在编译时分配。
但是对于空间的需求,不仅仅是上述的情况。有时候我们需要的空间大小并不是固定的,而是能够动态变换的,因此便有了动态内存分配
2.1 malloc
malloc() 函数是 C 语言中用于动态分配内存的函数,其原型如下:
void* malloc(size_t size);- 1
该函数用于在运行时从堆中分配指定大小的内存空间(单位是字节),并返回一个指向该内存空间起始位置的指针。
- 如果开辟成功,则返回一个指向开辟好空间的指针。
- 如果开辟失败,则返回一个NULL指针,因此malloc的返回值一定要做检查。
- 返回值的类型是 void* ,所以malloc函数并不知道开辟空间的类型,具体在使用的时候使用者自己来决定。
- 如果参数 size 为0,malloc的行为是标准是未定义的,取决于编译器。
下面是一个使用 malloc() 函数的示例代码,说明如何动态分配一个整型数组并进行操作:
#include#include int main() { int n, i; int* arr; printf("Enter the size of the array: "); scanf("%d", &n); // 分配内存空间 arr = (int*)malloc(n * sizeof(int)); // 检查内存分配是否成功 if (arr == NULL) { printf("Memory allocation failed.\n"); return 0; } printf("Enter %d elements:\n", n); // 从键盘获取数组元素 for (i = 0; i < n; i++) { scanf("%d", &arr[i]); } printf("The elements in the array are: "); for (i = 0; i < n; i++) { printf("%d ", arr[i]); } // 释放内存空间 free(arr); arr = NULL; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
在上述代码中,首先通过
malloc(n * sizeof(int))分配了一个大小为 n 个整型元素的数组所需的内存空间。然后,使用 for 循环从键盘获取用户输入的数组元素,并将其存储在动态分配的数组中。最后,使用free()函数释放了之前分配的内存空间,将指针设置为 NULL。注意:使用完动态分配的内存后,务必调用
free()函数释放该内存,以避免内存泄漏问题。同时,要确保在释放内存后,将指针设置为 NULL,以防止出现悬挂指针的情况。2.2 free
C语言提供了另外一个函数free,专门是用来做动态内存的释放和回收的,函数原型如下:
void free (void* ptr);- 1
free函数用来释放动态开辟的内存。
- 如果参数 ptr 指向的空间不是动态开辟的,那free函数的行为是未定义的。
- 如果参数 ptr 是NULL指针,则函数什么事都不做。
malloc和free都声明在 stdlib.h 头文件中。
注意:malloc申请的空间如果不通过free释放掉,那么这个空间是不会被释放的,只有当你退出程序后,才会释放,所以对于动态空间,我们要及时通过free释放,并将指向这块空间的指针置空,避免野指针
2.3 calloc
calloc()是 C 语言中用于动态分配内存空间的函数,它与malloc()函数类似。不同之处在于calloc()在分配内存空间的同时会将内存块中的每个字节都初始化为零。calloc()函数的原型如下:void* calloc(size_t num, size_t size);- 1
num参数表示要分配的元素数量,size参数表示每个元素的大小。calloc()函数会为num * size个连续的字节分配内存空间,并返回一个指向分配内存空间起始地址的指针。如果内存不足,calloc()函数会返回一个空指针(NULL)。- 函数的功能是为 num 个大小为 size 的元素开辟一块空间,并且把空间的每个字节初始化为0。
- 与函数 malloc 的区别只在于 calloc 会在返回地址之前把申请的空间的每个字节初始化为全0。
举个例子:
下面是一个使用
calloc()函数的示例代码:#include#include int main() { int *nums; int length; printf("请输入数组长度:"); scanf("%d", &length); // 动态分配内存空间 nums = (int *)calloc(length, sizeof(int)); if (nums == NULL) { printf("内存分配失败!\n"); return 1; } for (int i = 0; i < length; i++) { printf("请输入第 %d 个元素:", i + 1); scanf("%d", &nums[i]); } printf("数组元素为:"); for (int i = 0; i < length; i++) { printf("%d ", nums[i]); } printf("\n"); // 释放内存空间 free(nums); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
在上面的示例代码中,我们首先使用
calloc()函数动态分配了一个length长度的整数数组,并将起始地址保存在nums指针中。然后,通过遍历循环分别接收用户输入的数组元素值,并输出这些元素。最后使用free()函数释放了动态分配的内存空间。2.4 realloc
realloc()函数是 C 语言中用于重新分配内存空间的函数。它可以修改先前由malloc()、calloc()或realloc()分配的内存块的大小。realloc()函数的声明如下:void *realloc(void *ptr, size_t size);- 1
ptr是一个指向要重新分配大小的内存块的指针,size是重新分配后的新大小。函数返回一个指向重新分配后内存块的指针,如果无法分配足够的内存,则返回NULL。下面是一个示例代码,演示了
realloc()函数的用法:#include#include int main() { // 原始内存块的初始大小为 3 int *ptr = (int *)malloc(3 * sizeof(int)); // 分配失败的情况下,返回 NULL if (ptr == NULL) { printf("内存分配失败\n"); return 1; } // 打印原始内存块的值 printf("原始内存块:\n"); for (int i = 0; i < 3; i++) { printf("%d ", ptr[i]); } printf("\n"); // 将内存块重新分配为 5,即增加了 2 个元素的空间 ptr = realloc(ptr, 5 * sizeof(int)); // 重新分配失败的情况下,返回 NULL if (ptr == NULL) { printf("内存重新分配失败\n"); return 1; } // 新增加的元素赋值 ptr[3] = 4; ptr[4] = 5; // 打印重新分配后的内存块的值 printf("重新分配后的内存块:\n"); for (int i = 0; i < 5; i++) { printf("%d ", ptr[i]); } printf("\n"); // 释放内存 free(ptr); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
在这个示例代码中,我们首先使用
malloc()分配了一个大小为 3 的内存块,并将其指针赋值给ptr。然后,我们使用循环将原始然后,我们手动为新增加的两个元素赋值,并使用循环打印重新分配后的内存块的内容。
最后,我们使用 free() 函数释放了内存块。
注意:realloc在调整内存空间的是存在两种情况
- 情况1:原有空间之后有足够大的空间
- 情况2:原有空间之后没有足够大的空间
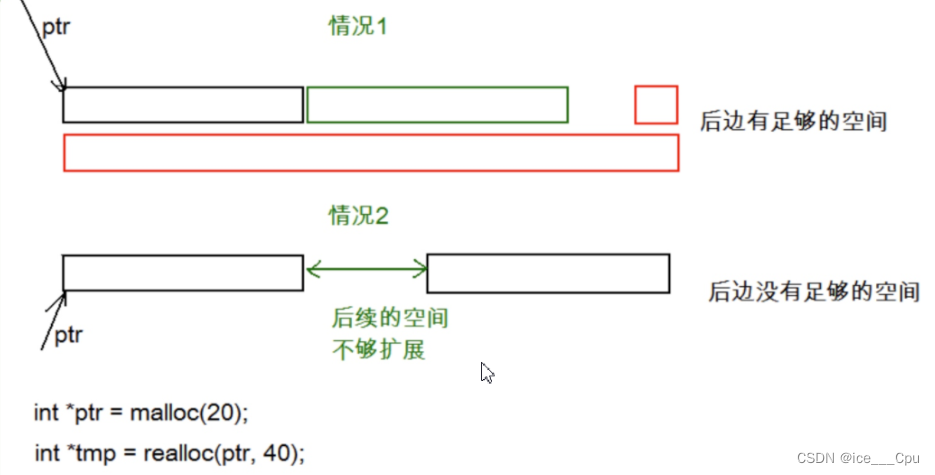
情况1:当是情况1 的时候,要扩展内存就直接原有内存之后直接追加空间,原来空间的数据不发生变化。
情况2:当是情况2 的时候,原有空间之后没有足够多的空间时,扩展的方法是:在堆空间上另找一个合适大小的连续空间来使用。这样函数返回的是一个新的内存地址。
由于上述的两种情况,realloc函数的使用就要注意一些。
2.4 有关动态内存分配容易出问题的地方
1:对NULL指针的解引用操作:
void test() { int *p = (int *)malloc(INT_MAX/4); *p = 20;//如果p的值是NULL,就会有问题 free(p); }- 1
- 2
- 3
- 4
- 5
- 6
2:对动态开辟空间的越界访问
void test() { int i = 0; int *p = (int *)malloc(10*sizeof(int)); if(NULL == p) { exit(EXIT_FAILURE); } for(i=0; i<=10; i++) { *(p+i) = i;//当i是10的时候越界访问 } free(p); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3:对非动态开辟内存使用free释放(free的空间必须是动态开辟的)
void test() { int a = 10; int *p = &a; free(p);//ok? }- 1
- 2
- 3
- 4
- 5
- 6
4:使用free释放一块动态开辟内存的一部分(要释放就释放完)
void test() { int *p = (int *)malloc(100); p++; free(p);//p不再指向动态内存的起始位置 }- 1
- 2
- 3
- 4
- 5
- 6
5:对同一块动态内存多次释放(没有free动态空间,出了test函数p就被销毁了,没有指针可以和申请的动态空间关联了,造成了内存泄漏)
void test() { int *p = (int *)malloc(100); free(p); free(p);//重复释放 }- 1
- 2
- 3
- 4
- 5
- 6
6:动态开辟内存忘记释放(内存泄漏)
void test() { int *p = (int *)malloc(100); if(NULL != p) { *p = 20; } } int main() { test(); while(1); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
三:c/c++程序内存开辟
c/c++中程序内存区域划分如图所示:

C/C++程序内存分配的几个区域:-
栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返回地址等。(栈区开辟效率高)
-
堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS(操作系统)回收 。分配方式类似于链表。
-
数据段(静态区)(static)存放全局变量、静态数据。程序结束后由系统释放。
-
代码段:存放函数体(类成员函数和全局函数)的二进制代码。
-
相关阅读:
ESP8266-Arduino编程实例-BMP280+SI7021(GY-21P)组合模块驱动
中文编程工具开发语言开发的实际案例:触摸屏点餐软件应用场景实例
对软件建模的全面认识
VD6283TX环境光传感器驱动开发(3)----测试闪烁频率代码
Redis实战篇(二)查询缓存
LeetCode 热题 100 | 图论(三)
【面试复盘】阿里蚂蚁后端面试
try-except 搭配装饰器使用
内网渗透-Hash传递攻击
fork主仓库后拉取主仓库的最新代码,拉取后更新fork的仓库
- 原文地址:https://blog.csdn.net/weixin_73232539/article/details/133484112
