-
七、2023.10.1.Linux(一).7
文章目录
- 1、 Linux中查看进程运行状态的指令、查看内存使用情况的指令、tar解压文件的参数。
- 2、文件权限怎么修改?
- 3、说说常用的Linux命令?
- 4、说说如何以root权限运行某个程序?
- 5、 说说软链接和硬链接的区别?
- 6、说说静态库和动态库怎么制作及如何使用,区别是什么?
- 7、简述GDB常见的调试命令,什么是条件断点,多进程下如何调试。
- 8、说说什么是大端小端,如何判断大端小端?
- 9、说说进程调度算法有哪些?
- 10、简述操作系统如何申请以及管理内存的?
- 11、简述Linux系统态与用户态,什么时候会进入系统态?
- 12、简述LRU算法及其实现方式?
- 13、 一个线程占多大内存?
- 14、什么是页表,为什么要有?
- 15、简述操作系统中的缺页中断。
1、 Linux中查看进程运行状态的指令、查看内存使用情况的指令、tar解压文件的参数。
- 查看进程运行状态的指令:ps命令。“ps -aux | grep PID”,用来查看某PID进程状态
- 查看内存使用情况的指令:free命令。“free -m”,命令查看内存使用情况。
- tar解压文件的参数:
五个命令中必选一个 -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 这几个参数是可选的 -z:有gzip属性的 -j:有bz2属性的 -Z:有compress属性的 -v:显示所有过程 -O:将文件解开到标准输出- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2、文件权限怎么修改?
Linux文件的基本权限就有九个,分别是owner/group/others三种身份各有自己read/write/execute
- 权限
修改权限指令:chmod
举例:文件的权限字符为 -rwxrwxrwx 时,这九个权限是三个三个一组。其中,我们可以使用数字来代表各个权限。各权限的分数对照如下:

每种身份(owner/group/others)各自的三个权限(r/w/x)分数是需要累加的,
例如当权限为: [-rwxrwx—] ,则分数是:
owner = rwx = 4+2+1 = 7
group = rwx = 4+2+1 = 7
others= — = 0+0+0 = 0
所以我们设定权限的变更时,该文件的权限数字就是770!变更权限的指令chmod的语法是这样的:
[root@www ~]# chmod [-R] xyz 文件或目录 选项与参数: xyz : 就是刚刚提到的数字类型的权限属性,为 rwx 属性数值的相加。 -R : 进行递归(recursive)的持续变更,亦即连同次目录下的所有文件都会变更 # chmod 770 douya.c //即修改douya.c文件的权限为770- 1
- 2
- 3
- 4
- 5
3、说说常用的Linux命令?
- cd命令:用于切换当前目录
- ls命令:查看当前文件与目录
- grep命令:该命令常用于分析一行的信息,若当中有我们所需要的信息,就将该行显示出来,该命令通常与管道命令一起使用,用于对一些命令的输出进行筛选加工。
- cp命令:复制命令
- mv命令:移动文件或文件夹命令
- rm命令:删除文件或文件夹命令
- ps命令:查看进程情况
- kill命令:向进程发送终止信号
- tar命令:对文件进行打包,调用gzip或bzip对文件进行压缩或解压
- cat命令:查看文件内容,与less、more功能相似
- top命令:可以查看操作系统的信息,如进程、CPU占用率、内存信息等
- pwd命令:命令用于显示工作目录。
4、说说如何以root权限运行某个程序?
sudo chown root app(文件名)
sudo chmod u+s app(文件名)5、 说说软链接和硬链接的区别?
- 定义不同
软链接又叫符号链接,这个文件包含了另一个文件的路径名。可以是任意文件或目录,可以链接不同文件系统的文件。
硬链接就是一个文件的一个或多个文件名。把文件名和计算机文件系统使用的节点号链接起来。因此我们可以用多个文件名与同一个文件进行链接,这些文件名可以在同一目录或不同目录。 - 限制不同
硬链接只能对已存在的文件进行创建,不能交叉文件系统进行硬链接的创建;软链接可对不存在的文件或目录创建软链接;可交叉文件系统; - 创建方式不同
硬链接不能对目录进行创建,只可对文件创建;软链接可对文件或目录创建; - 影响不同
删除一个硬链接文件并不影响其他有相同 inode 号的文件。删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
6、说说静态库和动态库怎么制作及如何使用,区别是什么?
- 静态库代码装载的速度快,执行速度略比动态库快。
- 动态库更加节省内存,可执行文件体积比静态库小很多。
- 静态库是在编译时加载,动态库是在运行时加载。
- 生成的静态链接库,Windows下以.lib为后缀,Linux下以.a为后缀。生成的动态链接库,Windows
下以.dll为后缀,Linux下以.so为后缀。
7、简述GDB常见的调试命令,什么是条件断点,多进程下如何调试。
GDB调试:gdb调试的是可执行文件,在gcc编译时加入 -g ,告诉gcc在编译时加入调试信息,这样gdb才能调试这个被编译的文件
gcc -g tesst.c -o test- 1
- quit:退出gdb,结束调试
- list:查看程序源代码
list 5,10:显示5到10行的代码
list test.c:5, 10: 显示源文件5到10行的代码,在调试多个文件时使用
list get_sum: 显示get_sum函数周围的代码
list test,c get_sum: 显示源文件get_sum函数周围的代码,在调试多个文件时使用 - reverse-search:字符串用来从当前行向前查找第一个匹配的字符串
- run:程序开始执行
- help list/all:查看帮助信息
- break:设置断点
break 7:在第七行设置断点
break get_sum:以函数名设置断点
break 行号或者函数名 if 条件:以条件表达式设置断点 - watch 条件表达式:条件表达式发生改变时程序就会停下来
- next:继续执行下一条语句 ,会把函数当作一条语句执行
- step:继续执行下一条语句,会跟踪进入函数,一次一条的执行函数内的代码
条件断点:break if 条件 以条件表达式设置断点
多进程下如何调试:用set follow-fork-mode child 调试子进程 或者set follow-fork-mode parent 调试父进程- 1
- 2
8、说说什么是大端小端,如何判断大端小端?
- 小端模式:低的有效字节存储在低的存储器地址。小端一般为主机字节序;常用的X86结构是小端模式。很多的ARM,DSP都为小端模式。
- 大端模式:高的有效字节存储在低的存储器地址。大端为网络字节序;KEIL C51则为大端模式。
有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
如何判断:我们可以根据联合体来判断系统是大端还是小端。
因为联合体变量总是从低地址存储。int fun1(){ union test{ char c; int i; }; test t; t.i = 1; //如果是大端,则t.c为0x00,则t.c != 1,反之是小端 return (t.c == 1); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 在进行网络通信时是否需要进行字节序转换?
相同字节序的平台在进行网络通信时可以不进行字节序转换,但是跨平台进行网络数据通信时必须进行字节序转换。
原因如下:网络协议规定接收到得第一个字节是高字节,存放到低地址,所以发送时会首先去低地址取数据的高字节。小端模式的多字节数据在存放时,低地址存放的是低字节,而被发送方网络协议函数发送时会首先去低地址取数据(想要取高字节,真正取得是低字节),接收方网络协议函数接收时会将接收到的第一个字节存放到低地址(想要接收高字节,真正接收的是低字节),所以最后双方都正确的收发了数据。而相同平台进行通信时,如果双方都进行转换最后虽然能够正确收发数据,但是所做的转换是没有意义的,造成资源的浪费。而不同平台进行通信时必须进行转换,不转换会造成错误的收发数据,字节序转换函数会根据当前平台的存储模式做出相应正确的转换,如果当前平台是大端,则直接返回不进行转换,如果当前平台是小端,会将接收到得网络字节序进行转换。 - 网络字节序
网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节?也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题; UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处);由此可见,多字节数值在发送之前,在内存中因该是以大端法存放的; 所以说,网络字节序是大端字节序; 比如,我们经过网络发送整型数值0x12345678时,在80X86平台中,它是以小端发存放的,在发送之前需要使用系统提供的字节序转换函数htonl()将其转换成大端法存放的数值;
9、说说进程调度算法有哪些?
- 先来先服务调度算法
- 短作业(进程)优先调度算法
- 高优先级优先调度算法
- 时间片轮转法
- 多级反馈队列调度算法
- 先来先服务调度算法:每次调度都是从后备作业(进程)队列中选择一个或多个最先进入该队列的作业(进程),将它们调入内存,为它们分配资源、创建进程,然后放入就绪队列。
- 短作业(进程)优先调度算法:短作业优先(SJF)的调度算法是从后备队列中选择一个或若干个估计运行时间最短的作业(进程),将它们调入内存运行。
- 高优先级优先调度算法:当把该算法用于作业调度时,系统将从后备队列中选择若干个优先权最高的作业装入内存。当用于进程调度时,该算法是把处理机分配给就绪队列中优先权最高的进程
- 时间片轮转法:每次调度时,把CPU 分配给队首进程,并令其执行一个时间片。时间片的大小从几ms 到几百ms。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾;然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。
- 多级反馈队列调度算法:综合前面多种调度算法。
- 非抢占式优先权算法
在这种方式下,系统一旦把处理机分配给就绪队列中优先权最高的进程后,该进程便一直执行下
去,直至完成;或因发生某事件使该进程放弃处理机时,系统方可再将处理机重新分配给另一优先权最高的进程。这种调度算法主要用于批处理系统中;也可用于某些对实时性要求不严的实时系统中。 - 抢占式优先权调度算法
在这种方式下,系统同样是把处理机分配给优先权最高的进程,使之执行。但在其执行期间,只要又出现了另一个其优先权更高的进程,进程调度程序就立即停止当前进程(原优先权最高的进程)的执行,重新将处理机分配给新到的优先权最高的进程。因此,在采用这种调度算法时,是每当系统中出现一个新的就绪进程i 时,就将其优先权Pi与正在执行的进程j 的优先权Pj进行比较。如果
Pi≤Pj,原进程Pj便继续执行;但如果是Pi>Pj,则立即停止Pj的执行,做进程切换,使i 进程投入执行。显然,这种抢占式的优先权调度算法能更好地满足紧迫作业的要求,故而常用于要求比较严格的实时系统中,以及对性能要求较高的批处理和分时系统中。
区别:
- 非抢占式(Nonpreemptive):让进程运行直到结束或阻塞的调度方式,容易实现,适合专用系统,不适合通用系统。
- 抢占式(Preemptive):允许将逻辑上可继续运行的在运行过程暂停的调度方式可防止单一进程长时间独占,CPU系统开销大(降低途径:硬件实现进程切换,或扩充主存以贮存大部分程序)。
10、简述操作系统如何申请以及管理内存的?
操作系统如何管理内存:
- 物理内存:物理内存有四个层次,分别是寄存器、高速缓存、主存、磁盘。
寄存器:速度最快、量少、价格贵。
高速缓存:次之。
主存:再次之。
磁盘:速度最慢、量多、价格便宜。
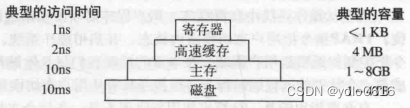
操作系统会对物理内存进行管理,有一个部分称为内存管理器(memory manager),它的主要工
作是有效的管理内存,记录哪些内存是正在使用的,在进程需要时分配内存以及在进程完成时回收内存。 - 虚拟内存:操作系统为每一个进程分配一个独立的地址空间,但是虚拟内存。虚拟内存与物理内存存在映射关系,通过页表寻址完成虚拟地址和物理地址的转换。
操作系统如何申请内存:
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:*brk和mmap。11、简述Linux系统态与用户态,什么时候会进入系统态?
- 内核态与用户态:内核态(系统态)与用户态是操作系统的两种运行级别。内核态拥有最高权限,可以访问所有系统指令;用户态则只能访问一部分指令。
- 什么时候进入内核态:共有三种方式:a、系统调用。b、异常。c、设备中断。其中,系统调用是主动的,另外两种是被动的。
- 为什么区分内核态与用户态:在CPU的所有指令中,有一些指令是非常危险的,如果错用,将导致整个系统崩溃。比如:清内存、设置时钟等。所以区分内核态与用户态主要是出于安全的考虑。
12、简述LRU算法及其实现方式?
- LRU算法:LRU算法用于缓存淘汰。思路是将缓存中最近最少使用的对象删除掉
- 实现方式:利用链表和hashmap。
当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。
在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
class LRUCache { list<pair<int, int>> cache;//创建双向链表 unordered_map<int, list<pair<int, int>>::iterator> map;//创建哈希表 int cap; public: LRUCache(int capacity) { cap = capacity; } int get(int key) { if (map.count(key) > 0){ auto temp = *map[key]; cache.erase(map[key]); map.erase(key); cache.push_front(temp); map[key] = cache.begin();//映射头部 return temp.second; } return -1; } void put(int key, int value) { if (map.count(key) > 0){ cache.erase(map[key]); map.erase(key); } else if (cap == cache.size()){ auto temp = cache.back(); map.erase(temp.first); cache.pop_back(); } cache.push_front(pair<int, int>(key, value)); map[key] = cache.begin();//映射头部 } }; /** * Your LRUCache object will be instantiated and called as such: * LRUCache* obj = new LRUCache(capacity); * int param_1 = obj->get(key); * obj- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
13、 一个线程占多大内存?
一个linux的线程大概占8M内存。
linux的栈是通过缺页来分配内存的,不是所有栈地址空间都分配了内存。因此,8M是最大消耗,实际的内存消耗只会略大于实际需要的内存(内部损耗,每个在4k以内)。14、什么是页表,为什么要有?
页表是虚拟内存的概念。操作系统虚拟内存到物理内存的映射表,就被称为页表。
原因:不可能每一个虚拟内存的 Byte 都对应到物理内存的地址。这张表将大得真正的物理地址也放不下,于是操作系统引入了页(Page)的概念。进行分页,这样可以减小虚拟内存页对应物理内存页的映射表大小。
如果将每一个虚拟内存的 Byte 都对应到物理内存的地址,每个条目最少需要 8字节(32位虚拟地址->32位物理地址),在 4G 内存的情况下,就需要 32GB 的空间来存放对照表,那么这张表就大得真正的物理地址也放不下了,于是操作系统引入了页(Page)的概念。
在系统启动时,操作系统将整个物理内存以 4K 为单位,划分为各个页。之后进行内存分配时,都以页为单位,那么虚拟内存页对应物理内存页的映射表就大大减小了,4G 内存,只需要 8M 的映射表即可,一些进程没有使用到的虚拟内存,也并不需要保存映射关系,而且Linux 还为大内存设计了多级页表,可以进一页减少了内存消耗。15、简述操作系统中的缺页中断。
- 缺页异常:malloc和mmap函数在分配内存时只是建立了进程虚拟地址空间,并没有分配虚拟内存对应的物理内存。当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常,引发缺页中断。
- 缺页中断:缺页异常后将产生一个缺页中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存。
-
相关阅读:
大学生HTML作业节日网页 HTML作业节日文化网页期末作业 html+css+js节日网页 HTML学生节日介绍 HTML学生作业网页视频
Windows OpenGL 图像单色
图文详解 HDFS 的工作机制及其原理
动静分离LNMP
怎么降低Linux内核驱动开发的风险?
开源组件与中间件的学习笔记5
193页5万字智慧物流园解决方案
【ManageEngine】如何利用好OpManager的报表功能
乘法逆元代码模板
【错误记录】exe4j 打包程序无法设置 jar 包依赖的问题 ( 将源码 和 依赖库打包到同一个 jar 包中 )
- 原文地址:https://blog.csdn.net/weixin_54447296/article/details/133468691
