-
真正理解浏览器渲染更新流程
浏览器渲染更新过程
文章目录
之前阅读过李兵老师的《浏览器工作原理与实践》,但还是对其中有些概念模糊,于是趁着国庆,对浏览器渲染更新原理进行梳理。本篇只是对一些优秀资料的总结及自己的理解,如果时间充裕建议阅读本文最后的引用。先放图:

帧维度解释帧渲染过程
在一个流畅的页面变化效果中(动画或滚动),渲染帧,指的是浏览器从js执行到paint的一次绘制过程,帧与帧之间快速地切换,由于人眼的残像错觉,就形成了动画的效果。那么这个“快速”,要达到多少才合适呢?
我们都知道,下层建筑决定了上层建筑。受限于目前大多数屏幕的刷新频率——60次/s,浏览器的渲染更新的页面的标准帧率也为60次/s–60FPS(frames/per second)。- 高于这个数字,在一次屏幕刷新的时间间隔16.7ms(1/60)内,就算浏览器渲染了多次页面,屏幕也只刷新一次,这就造成了性能的浪费。
- 低于这个数字,帧率下降,人眼就可能捕捉到两帧之间变化的滞涩与突兀,表现在屏幕上,就是页面的抖动,大家通常称之为卡顿
来个比喻。快递每天整理包裹,并一天一送。如果某天包裹太多,整理花费了太多时间,来不及当日(帧)送到收件人处,那就延期了(丢帧)。
标准渲染帧:
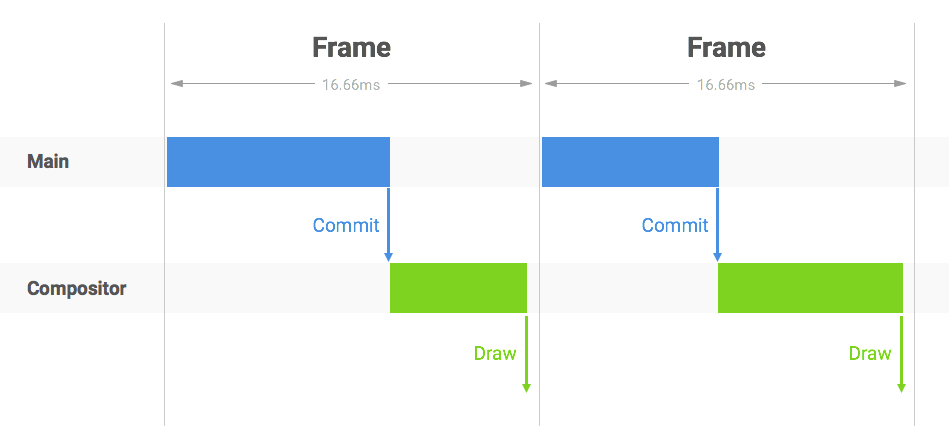
在一个标准帧渲染时间16.7ms之内,浏览器需要完成Main线程的操作,并commit给Compositor进程
丢帧:
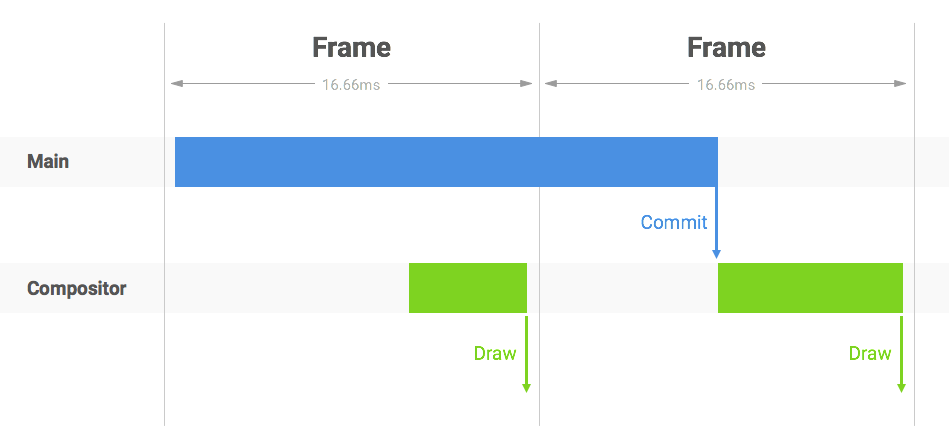
主线程里操作太多,耗时长,commit的时间被推迟,浏览器来不及将页面draw到屏幕,这就丢失了一帧一些名词解释
Renderer进程
- Main线程:浏览器渲染的主要执行步骤,包含从JS执行到Composite合成的一系列操作。负责解析html css 和主线程中的js,我们平时熟悉的那些东西,诸如:Calculate Style,Update Layer Tree,Layout,Paint,Composite Layers等等都是在这个线程中进行的。 总之,就是将我们的代码解析成各种数据,直到能被合成器线程接收去做处理。
- Compositor(合成)线程:
- 接收一个vsync信号,表示这一帧开始
- 接收用户的一些交互操作(比如滚动) ,然后commit给Main线程
- 唤起Main线程进行操作
- 接收Main线程的操作结果
- 将图层划分为图块(tile),并交给栅格化线程
- 拿到栅格化线程的执行结果,它的结果就是一些位图
- commit给真正把页面draw到屏幕上的GPU进程
- Compositor Tile Work(s)线程:Compositor调起Compositor Tile Work(s)来辅助处理页面。Rasterize意为光栅化。这里的 Tile 其实就是位图的意思(下文会详细说明),合成线程会将图层划分为图块(tile),生成位图的操作是由栅格化来执行的。栅格化线程不止一个,可能有多个栅格化线程。
GPU进程
整个浏览器共用一个。主要是负责把Renderer进程中绘制好的tile位图作为纹理上传至GPU,并调用GPU的相关方法把纹理draw到屏幕上。GPU进程里只有一个线程:GPU Thread。
这里其实只需要知道:GPU进程把 render进程的结果 draw 到 页面上。rendering(渲染) vs painting(绘制)⭐
这里的 painting 也可以理解成上面的 draw,火焰图中也会出现这两个关键词。
我们可以想象成 除了浏览器之外,还有一个后台工人,浏览器使用双缓冲,始终有两张图- rendering 渲染:后台工人画的过程,这里就是 浏览器的render进程
- painting 绘制:当后台工人画好后往浏览器页面上放的过程,GPU进程负责将画好的东西paint(draw)到浏览器上
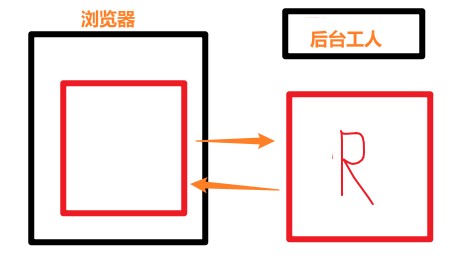
后台工人先render一张,render完毕后,把浏览器的那张图替换下来叫paint(draw),然后后台工人又开始在替换下来的那张图上进行render
浏览器每一帧会替换一次,保证动画是连续的,很像动画那样一帧一帧位图

就是数据结构里常说的位图。你想在绘制出一个图片,你应该怎么做,显然首先是把这个图片表示为一种计算机能理解的数据结构:用一个二维数组,数组的每个元素记录这个图片中的每一个像素的具体颜色。所以浏览器可以用位图来记录他想在某个区域绘制的内容,绘制的过程也就是往数组中具体的下标里填写像素而已。纹理
纹理其实就是GPU中的位图,存储在GPU video RAM中。前面说的位图里的元素存什么你自己定义好就行,是用3字节存256位rgb还是1个bit存黑白你自己定义即可,但是纹理是GPU专用的,GPU和CPU是分离的,需要有固定格式,便于兼容与处理。所以一方面纹理的格式比较固定,如R5G6B5、A4R4G4B4等像素格式, 另外一方面GPU 对纹理的大小有限制,比如长/宽必须是2的幂次方,最大不能超过2048或者4096等。
总结:render进程中的叫位图,GPU进程中的叫纹理,生成位图(纹理)的这个过程叫栅格化,ok,过…
Rasterize(光栅化)
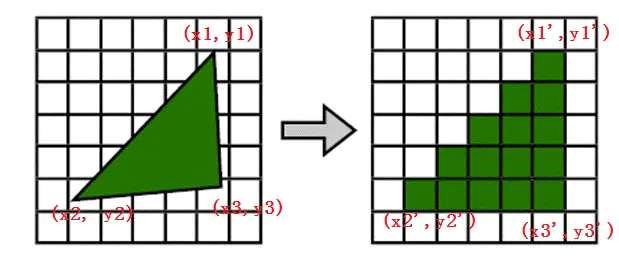

在纹理里填充像素不是那么简单的自己去遍历位图里的每个元素然后填写这个像素的颜色的。就像前面两幅图。光栅化的本质是坐标变换、几何离散化,然后再填充。
同时,光栅化从早期的 Full-screen Rasterization基本都进化到了现在的Tile-Based Rasterization, 也就是不是对整个图像做光栅化,而是把图像分块(tile,亦有翻译为瓦片、贴片、瓷片…)后,再对每个tile单独光栅化。光栅化好了将像素填充进纹理,再将纹理上传至GPU。
原因一方面如上文所说,纹理大小有限制,即使你整屏光栅化也是要填进小块小块的纹理中,不如事先根据纹理大小分块光栅化后再填充进纹理里。另一方面是为了减少内存占用(整屏光栅化意味着需要准备更大的buffer空间)和降低总体延迟(分块栅格化意味着可以多线程并行处理)。
看到下图中蓝色的那些青色的矩形了吗?他们就是tiles。

可以想见浏览器的一次绘制过程就是先把想绘制的内容如文字、背景、边框等通过分块Rasterize绘制到很多纹理里,再把纹理上传到gpu的存储空间里,gpu把纹理绘制到屏幕上。
上面balabala说了一大堆,看得懂就看,看不懂就直接看总结…
所以,什么是光栅化,光栅化本质也是生成位图(纹理),不过会先分块,然后对每一块进行生成位图,这个分块的过程是由合成线程实现的,生成位图的过程是栅格化线程实现的。为什么要先分块,再栅格化,而不直接对整块屏幕做栅格化?为了减少内存占用和多线程处理(那这就意味着栅格化线程不止一个,可能有多个栅格化线程)。名词解释完了,开始详细介绍浏览器渲染的每一步。再次摆出整个渲染流程图。
或者另外一张类似的流程图
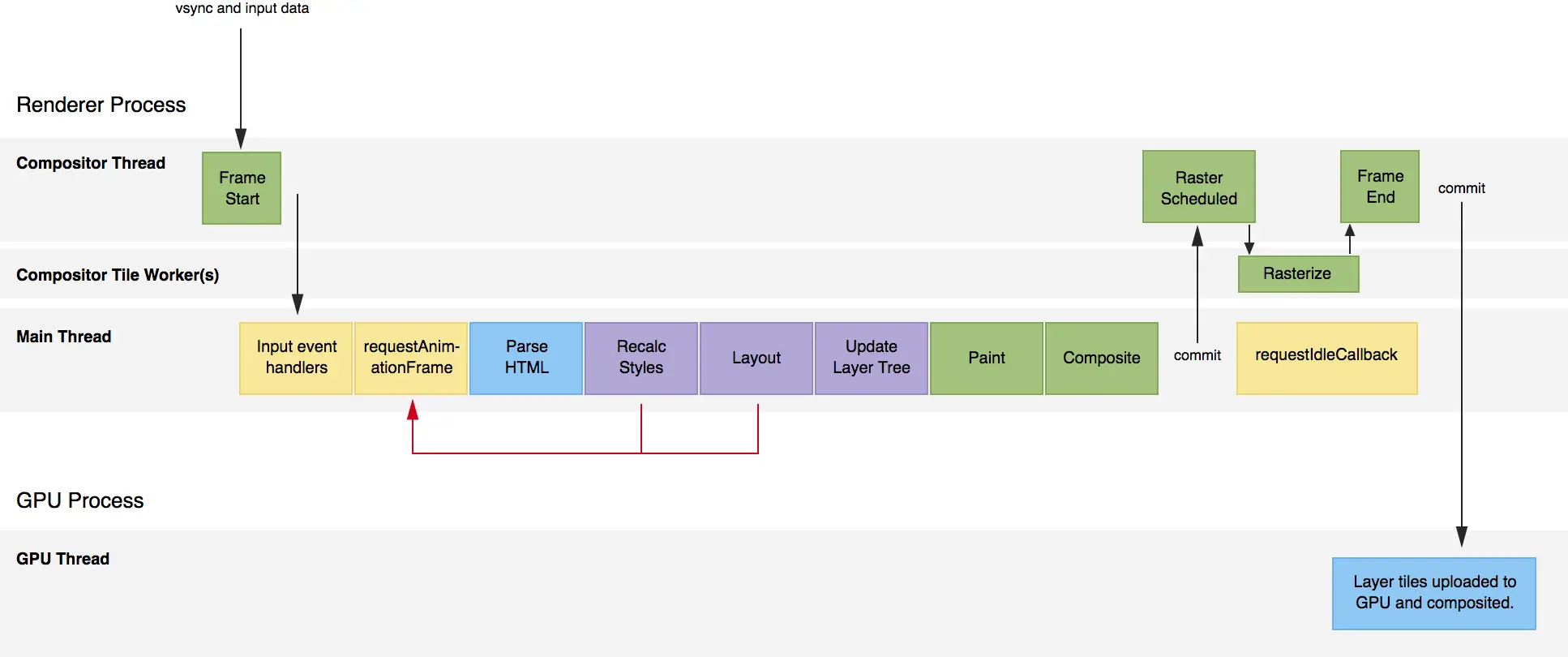
1. 浏览器的某一帧开始:vsync
Compositor(合成)线程接收一个vsync信号,表示这一帧开始
2. Input event handlers
Compositor线程接收用户的交互输入(比如touchmove、scroll、click等)。然后commit给Main线程,这里有两点规则需要注意:
- 并不是所有event都会commit给Main线程,部分操作比如单纯的滚动事件,打字等输入,不需要执行JS,也没有需要重绘的场景,Compositor线程就自己处理了,无需请求Main线程
- 同样的事件类型,不论一帧内被Compositor线程接收多少次,实际上commit给Main线程的,只会是一次,意味着也只会被执行一次。(HTML5标准里scroll事件是每帧触发一次),所以自带了相对于动画的节流效果!scroll、resize、touchmove、mousemove等事件,由于Compositor Thread的机制原因,都会每一帧只执行一次
3. requestAnimationFrame
window.requestAnimationFrame() 这个方法,既然已经说明了它是一个方法,那它一定是在 JavaScript 中执行的。
4. 强制重排(可能存在)
Avoid large, complex layouts and layout thrashing
下面对这个引用文章进行解释:
这里本来已经走到了我们熟知的浏览器渲染过程:
js修改dom结构或样式 -> 计算style -> layout(重排) -> paint(重绘) -> composite(合成)
首先运行 JavaScript,然后运行样式计算,最后运行布局。然而,可以使用 JavaScript 强制浏览器提前执行布局。这称为强制同步布局。
接下来解释 强制重排,也叫强制同步布局。
首先要记住的是,当 JavaScript 运行时,前一帧中的所有旧布局值都是已知的,可供您查询。因此,例如,如果您想在帧的开头写出元素(我们称之为“盒子”)的高度,您可以编写如下代码:// Schedule our function to run at the start of the frame: requestAnimationFrame(logBoxHeight); function logBoxHeight () { // Gets the height of the box in pixels and logs it out: console.log(box.offsetHeight); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果您在询问框的高度_之前_更改了框的样式,则会出现问题:
function logBoxHeight () { box.classList.add('super-big'); // Gets the height of the box in pixels and logs it out: console.log(box.offsetHeight); }- 1
- 2
- 3
- 4
- 5
- 6
现在,为了回答高度问题,浏览器必须_首先_应用样式更改(因为添加了super-big类),_然后_运行布局。只有这样它才能返回正确的高度。这是不必要且可能昂贵的工作。这就是强制重排。
强制重排意思是可能会在JS里强制重排,当访问scrollWidth系列、clientHeight系列、offsetTop系列、ComputedStyle等属性时,会触发这个效果,导致Style和Layout前移到JS代码执行过程中
浏览器有自己的优化机制,包括之前提到的每帧只响应同类别的事件一次,再比如这里的会把一帧里的多次重排、重绘汇总成一次进行处理。
flush队列是浏览器进行重排、重绘等操作的队列,所有会引起重排重绘的操作都包含在内,比如dom修改、样式修改等。如果每次js操作都去执行一次重排重绘,那么浏览器一定会卡卡卡卡卡,所以浏览器通常是在一定的时间间隔(一帧)内,批量处理队列里的操作。但是,对于有些操作,比如获取元素相对父级元素左边界的偏移值(Element.offsetLeft),但在此之前我们进行了样式或者dom修改,这个操作还攒在flush队列里没有执行,那么浏览器为了让我们获取正确的offsetLeft(虽然之前的操作可能不会影响offsetLeft的值),就会立即执行队列里的操作。
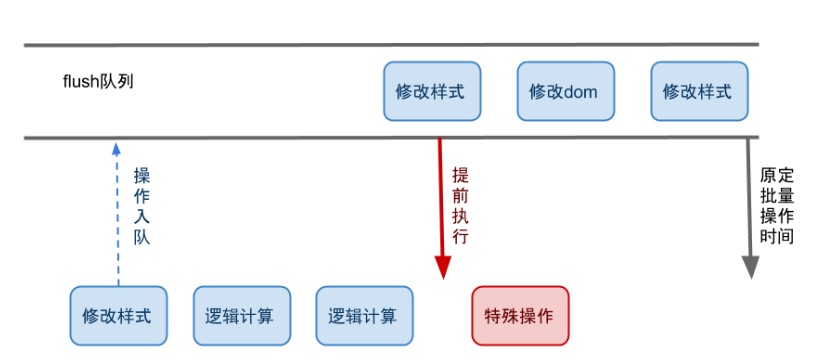
所以我们知道了,就是这个特殊操作会影响浏览器正常的执行和渲染,假设我们频繁执行这样的特殊操作,就会打断浏览器原来的节奏,增大开销。
而这个特殊操作,具体指的就是:- elem.offsetLeft, elem.offsetTop, elem.offsetWidth, elem.offsetHeight, elem.offsetParent
- elem.clientLeft, elem.clientTop, elem.clientWidth, elem.clientHeight
- elem.getClientRects(), elem.getBoundingClientRect()
- elem.scrollWidth, elem.scrollHeight
- elem.scrollLeft, elem.scrollTop
- …
更多会触发强制重排的属性:See more:What forces layout / reflow
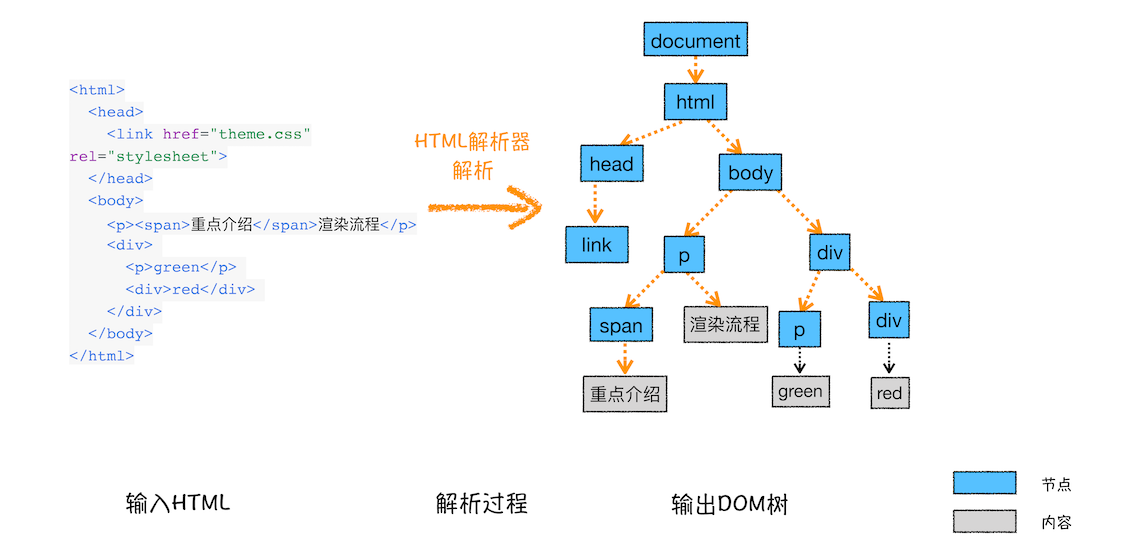
5. parse HTML(构建DOM树)
如果有DOM变动,那么会有解析DOM的这一过程。
6. 计算样式
样式计算的目的是为了计算出DOM节点中每个元素的具体样式,这个阶段大体可分为三步来完成
6.1 把CSS转换为浏览器能够理解的结构
那CSS样式的来源主要有哪些呢?你可以先参考下图:
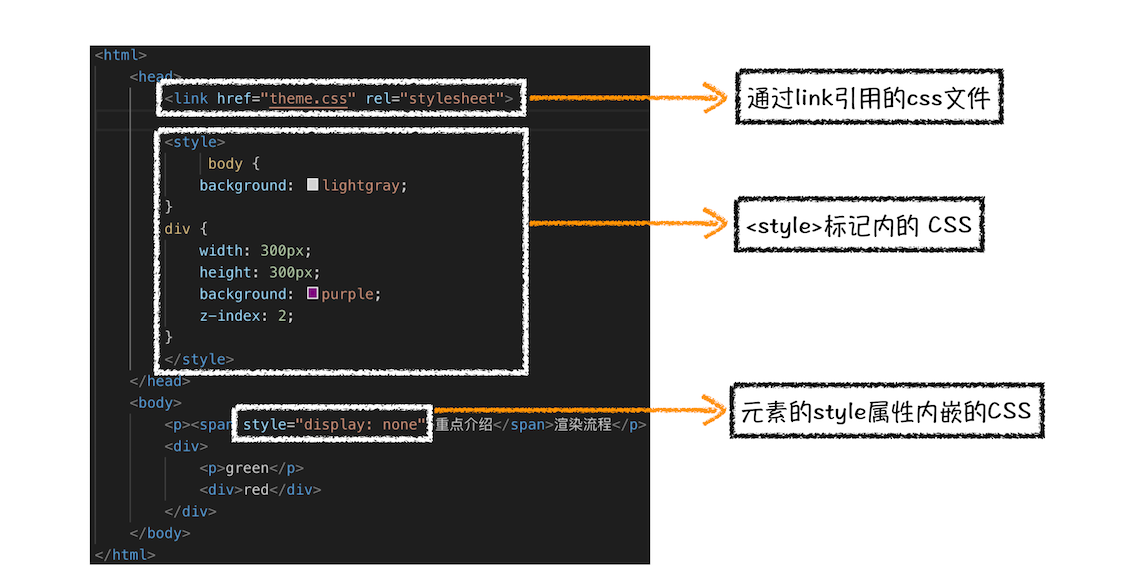
从图中可以看出,CSS样式来源主要有三种:- 通过link引用的外部CSS文件