-
自己动手写编译器:实现命令行模块
在前面一系列章节中,我们完成了词法解析的各种算法。包括解析正则表达式字符串,构建 NFA 状态就,从 NFA 转换为 DFA 状态机,最后实现状态机最小化,接下来我们注重词法解析模块的工程化实现,也就是我们将所有算法集合起来完成一个可用的程序,由此在接下来的章节中,我们将重点放在工程实现上而不是编译原理算法上。
为何我们一个强调编译原理算法的专栏会花费大力气在工程实现上呢。英语有句俗语"you don’t know it if you can’t build it",也就是你做不出来就意味着你没有掌握它,这一点是我们传统教育的痛点,你上了计算机课程中的编译原理,操作系统,你掌握了一堆名词和算法描述,但完成这些课程,考试通过,那意味着你掌握这些知识了吗?如果学了操作系统,你不能做出一个可运行的系统,学了编译原理,你搞不出一个能编译代码的编译器,那说明你对所学知识根本没有真正掌握,你只是模模糊糊,一知半解。
为了真正掌握,我们必须构建出一个可运行的具体实体。在实现这个具体实体过程中,我们会发现很多我们以为理解了的算法或概念,实际上我们根本就没有掌握。本节开始我们要为 GoLex 添加更多复杂功能,当我们完成 GoLex 工具后,它的作用如下:
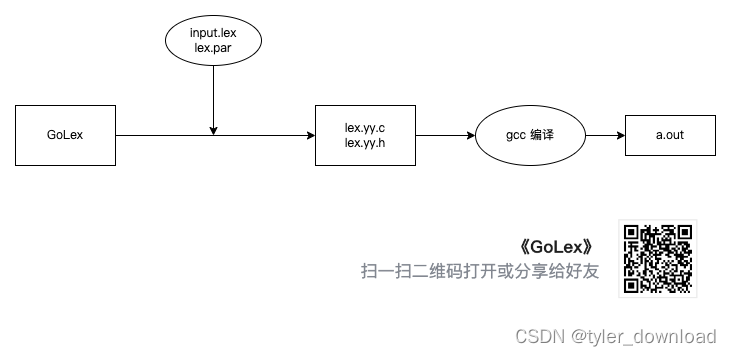
GoLex 程序运行时需要输入两个文件,分别为 input.lex 和 lex.par,其中 input.lex 我们已经认识过,lex.par 其实是一个 c 语言模板文件,它的内容我们在后面章节中会花很大力气去剖析和实现,GoLex 会读取这两个文件的内容,然后生成两个文件 lex.yy.c 和 lex.yy.h,这两个文件是给定语言词法解析器的代码,假设我们要开发一个能识别 sql 语言词法的程序,那么我们把识别 sql 语言中关键字,变量名等字符串对应的正则表达式放在 input.lex 中,然后调用 GoLex 生成 lex.yy.c,lex.yy.h 两个 c 语言源代码文件,然后再使用 gcc 对这些文件进行编译,最后得到的可执行文件 a.out 就是能用于对 sql 代码文件进行词法解析的可执行文件,也就是说 GoLex 其实是用于生成另一个可执行程序源代码的程序,这类似于微积分中的二阶求导。废话少说,能动手就不要逼逼。首先在工程目录下创建一个名为 cmd 的文件夹,然后创建一个名为 cmd.go 的文件,实现代码如下:
package command_line import ( "fmt" "time" ) type CommandLine struct { } func NewCommandLine() *CommandLine { return &CommandLine{} } func (c *CommandLine) Signon() { //这里设置当前时间 date := time.Now() //这里设置你的名字 name := "yichen" fmt.Printf("GoLex 1.0 [%s] . (c) %s, All rights reserved\n", date.Format("01-02-2006"), name) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
上面代码运行后会打印出一行”版权“信息,它能让我们感觉好像搞了什么牛逼得不行的东西,有一种老子是大神的牛逼哄哄获得感。下面我们提供一个函数叫 PrintHeader,它的作用是输出对未压缩 DFA 的 C语言注释,首先我们把原来在 main 函数中的那些代码挪到 CommandLine 对象的构造函数中,相关代码如下:
package command_line import ( "fmt" "nfa" "time" ) type CommandLine struct { lexerReader *nfa.LexReader parser *nfa.RegParser nfaConverter *nfa.NfaDfaConverter } func NewCommandLine() *CommandLine { lexReader, _ := nfa.NewLexReader("input.lex", "output.py") lexReader.Head() parser, _ := nfa.NewRegParser(lexReader) start := parser.Parse() nfaConverter := nfa.NewNfaDfaConverter() nfaConverter.MakeDTran(start) nfaConverter.PrintDfaTransition() return &CommandLine{ lexerReader: lexReader, parser: parser, nfaConverter: nfaConverter, } } func (c *CommandLine) PrintHeader() { //针对未压缩的 DFA 状态就,输出对应的 c 语言注释 c.nfaConverter.PrintUnCompressedDFA() //打印基于 c 语言的跳转表 c.nfaConverter.PrintDriver() } func (c *CommandLine) Signon() { //这里设置当前时间 date := time.Now() //这里设置你的名字 name := "yichen" fmt.Printf("GoLex 1.0 [%s] . (c) %s, All rights reserved\n", date.Format("01-02-2006"), name) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
然后我们进入文件 nfa_to_dfa,在类NfaDfaConverter中增加上面调用到的两个函数,其实现如下:
func (n *NfaDfaConverter) PrintUnCompressedDFA() { fmt.Fprint(n.fp, "ifdef __NEVER__\n") fmt.Fprint(n.fp, "/*------------------------------------------------\n") fmt.Fprint(n.fp, "DFA (start state is 0) is :\n *\n") nrows := n.nstates charsPrinted := 0 for i := 0; i < nrows; i++ { dstate := n.dstates[i] if dstate.isAccepted == false { fmt.Fprintf(n.fp, "* State %d [nonaccepting]", dstate.state) } else { //这里需要输出行数 //fmt.Fprintf(n.fp, "* State %d [accepting, line %d <", i, ) fmt.Fprintf(n.fp, "* State %d [accepting, line %d, <%s>]\n", i, dstate.LineNo, dstate.acceptString) if dstate.anchor != NONE { start := "" end := "" if (dstate.anchor & START) != NONE { start = "start" } if (dstate.anchor & END) != NONE { end = "end" } fmt.Fprintf(n.fp, " Anchor: %s %s", start, end) } } lastTransition := -1 for j := 0; j < MAX_CHARS; j++ { if n.dtrans[i][j] != F { if n.dtrans[i][j] != lastTransition { fmt.Fprintf(n.fp, "\n * goto %d on ", n.dtrans[i][j]) charsPrinted = 0 } fmt.Fprintf(n.fp, "%s", n.BinToAscii(j)) charsPrinted += len(n.BinToAscii(j)) if charsPrinted > 56 { //16 个空格 fmt.Fprintf(n.fp, "\n * ") charsPrinted = 0 } lastTransition = n.dtrans[i][j] } } fmt.Fprintf(n.fp, "\n") } fmt.Fprintf(n.fp, "*/ \n\n") fmt.Fprintf(n.fp, "#endif\n") } func (n *NfaDfaConverter) PrintDriver() { text := "输出基于 DFA 的跳转表,首先我们将生成一个 Yyaccept数组,如果 Yyaccept[i]取值为 0," + "\n\t那表示节点 i 不是接收态,如果它的值不是 0,那么节点是接受态,此时他的值对应以下几种情况:" + "\n\t1 表示节点对应的正则表达式需要开头匹配,也就是正则表达式以符号^开始," + "2 表示正则表达式需要\n\t末尾匹配,也就是表达式以符号$结尾,3 表示同时开头和结尾匹配,4 表示不需要开头或结尾匹配" comments := make([]string, 0) comments = append(comments, text) n.comment(comments) //YYPRIVATE YY_TTYPE 是 c 语言代码中的宏定义,我们将在后面代码提供其定义 //YYPRIVATE 对应 static, YY_TTYPE 对应 unsigned char fmt.Fprintf(n.fp, "YYPRIATE YY_TTYPE Yyaccept[]=\n") fmt.Fprintf(n.fp, "{\n") for i := 0; i < n.nstates; i++ { if n.dstates[i].isAccepted == false { //如果节点i 不是接收态,Yyaccept[i] = 0 fmt.Fprintf(n.fp, "\t0 ") } else { anchor := 4 if n.dstates[i].anchor != NONE { anchor = int(n.dstates[i].anchor) } fmt.Fprintf(n.fp, "\t%-3d", anchor) } if i == n.nstates-1 { fmt.Fprint(n.fp, " ") } else { fmt.Fprint(n.fp, ", ") } fmt.Fprintf(n.fp, "/*State %-3d*/\n", i) } fmt.Fprintf(n.fp, "};\n\n") //接下来的部分要在实现函数 DoFile 之后才好实现 //TODO }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
这里需要注意的是,PrintDriver我们只实现了一部分,剩余部分我们还需在后面章节实现 C 语言代码模板后,上面的 TODO 部分才能接着实现,不过在完成上面代码后,我们已经能看到 lex.yy.c 文件的部分内容了,在 main.go 中输入代码如下:
package main import ( "command_line" ) func main() { cmd := command_line.NewCommandLine() cmd.PrintHeader() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
完成上面代码后,执行起来,我们会得到一个 lex.yy.c 的文件,其内容如下所示:
ifdef __NEVER__ /*------------------------------------------------ DFA (start state is 0) is : * * State 0 [nonaccepting] * goto 1 on . * goto 2 on 0123456789 * State 1 [nonaccepting] * goto 3 on 0123456789 * State 2 [nonaccepting] * goto 4 on . * goto 5 on 0123456789 * State 3 [accepting, line 6, < {printf("%s is a float number", yytext); return FCON;}>] * State 4 [accepting, line 6, < {printf("%s is a float number", yytext); return FCON;}>] * goto 6 on 0123456789 * State 5 [nonaccepting] * goto 1 on . * goto 5 on 0123456789 * State 6 [accepting, line 6, < {printf("%s is a float number", yytext); return FCON;}>] * goto 7 on 0123456789 * State 7 [accepting, line 6, < {printf("%s is a float number", yytext); return FCON;}>] * goto 7 on 0123456789 */ #endif /*-------------------------------------- * 输出基于 DFA 的跳转表,首先我们将生成一个 Yyaccept数组,如果 Yyaccept[i]取值为 0, 那表示节点 i 不是接收态,如果它的值不是 0,那么节点是接受态,此时他的值对应以下几种情况: 1 表示节点对应的正则表达式需要开头匹配,也就是正则表达式以符号^开始,2 表示正则表达式需要 末尾匹配,也就是表达式以符号$结尾,3 表示同时开头和结尾匹配,4 表示不需要开头或结尾匹配 */ YYPRIATE YY_TTYPE Yyaccept[]= { 0 , /*State 0 */ 0 , /*State 1 */ 0 , /*State 2 */ 4 , /*State 3 */ 4 , /*State 4 */ 0 , /*State 5 */ 4 , /*State 6 */ 4 /*State 7 */ };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
可以看到,在输出的 c 语言文件中,我们首先使用注释输出了跳转表的内容,然后输出一个接收状态数组,如果节点 i 是接收状态,那么数组 Yyaccept[i]对应的值就不是 0,要不然它对应的值就是 0,下一节我们将深入研究 c 语言模板代码,然后完成本节的 TODO 部分代码,更多内容请在 B 站搜索 coding 迪斯尼,以便获取更加详细的调试演示视频。
-
相关阅读:
一文带你用 Mac M1 跑 RocketMQ
docker搭建nginx
基于协作搜索算法的函数寻优及工程优化
java spring cloud 企业工程管理系统源码+二次开发+定制化服务
分布式架构在云计算平台中的应用及优缺点
CSAPP-第二章学习笔记
面向6G承载网的路由优化算法研究
QT creator实现串口通信操作方法
ApplicationEvent
使用python setup.py报错:Upload failed (403) / Upload failed (400)
- 原文地址:https://blog.csdn.net/tyler_download/article/details/133347873
