-
统计模型----决策树
决策树
(1)决策树是一种基本分类与回归方法。它的关键在于如何构建这样一棵树。决策树的建立过程中,使用基尼系数来评估节点的纯度和划分的效果。基尼系数是用来度量一个数据集的不确定性的指标,其数值越小表示数据集的纯度越高。决策树的节点划分方式可以根据不同的算法和参数设置而不同。节点划分方式不同,但是基尼系数的下降效果却是一样的,只是具体数值不同。决策树的深度可以根据需求进行设置,如果不限制决策树的深度,它将一直延伸下去,直到所有叶子节点的均方误差为0。
模型特点:优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配的问题
适用数据类型:数值型和标称型
(3)决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。
(4)决策树的构造决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
1)开始:构建根节点,将所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
2)如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
3)如果还有子集不能够被正确的分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点,如果递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
4)每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树。(5)决策树分析举例(理解)
例如:小熊毕业了来到一家银行工作,刚刚入行的小熊仔细整理了客户的基本信息。如下图
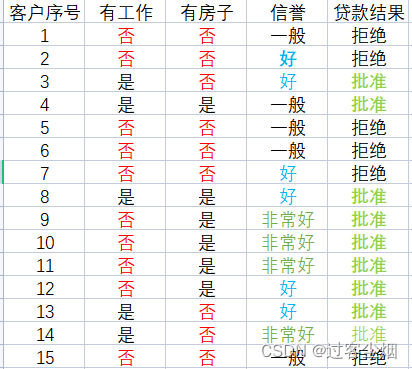

小熊根据以上信息得出基本结论:
(1)按有工作分类:
(2)按信誉分类的话:
以上样本结果好像与数据结果相悖
那如果按有工作和信誉因素分类的话:
如果客户有工作那就可以批准贷款,如果客户没有工作的话,我们再考虑他的信誉情况做出判断,这就是利用决策树进行分类的过程。
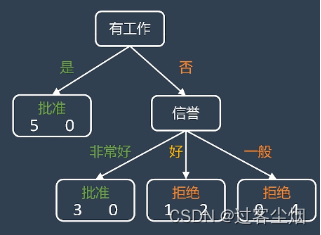
标准可以用一个基尼系数来定义:
采用基尼系数进行运算的决策树也称为CART决策树。
基尼系数(gini)用于计算一个系统中的失序现象,即系统的混乱程度(纯度)。基尼系数越高,系统的混乱程度就越高(不纯),建立决策树模型的目的就是降低系统的混乱程度(体高纯度),从而得到合适的数据分类效果。
基尼系数的计算公式如下:
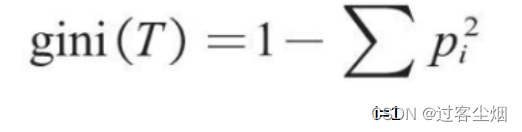
选择基尼数最小的来作为决策树下一级的标准。
Gini= 1-p(批准)2-p(拒绝)2
当p(批准)=1 p(拒绝)=0 Gini=1-1=0
当p(批准)=0 p(拒绝)=1 Gini=1-0-1=0
当p(批准)=0.5 p(拒绝)=0.5 Gini=1-0.25-0.25=0.5
以以上例子可以得出
Gini= 1-p(9/15)2-p(6/15)2=0.48
Gini(工作,是)=1-(5/5)-0=0
Gini(工作,否)=1-(4/10)-(6/10)=0.48
Gini(工作)=5/15Gini(工作,是)+10/15Gini(工作,否)=0.32
依次算出:Gini(房子)=0.27 Gini(信誉)=0.28
以上可知有房子的基尼系数最小,所以依此为下一次分类的依据: -
相关阅读:
Linux常见指令2
Arm 架构 Ubuntu 使用 Docker 安装 Gitlab 并使用
基于springboot医院碳排放管理平台设计与实现-计算机毕业设计源码+LW文档
python程序打包——基础准备、源代码打包、二进制打包、setuptools基础
js实现广告条+缓冲效果/键盘事件实现小人跑步
手写RISC-V处理器--开篇
springboot和vue的药品管理系统
30 华三华为STP
java基于springboot+vue+elementui的漫画投稿交流平台 前后端分离
Python用RNN神经网络LSTM优化EMD经验模态分解交易策略的股票价格MACD分析
- 原文地址:https://blog.csdn.net/qq_41309350/article/details/133429592