-
面试记录_
1: ❀公司
三道编程题,可以运用你最擅长的语言编写:可以尝试搜索、查找、暴力遍历等方法
稍微复杂点的题目,基本上通过递归、BFS/DFS 解决,暴力也可尝试。
常考知识点&算法:
1、排序
2、查找
3、字符串切割、子串查找、统计,替换
4、数的不同进制表示及转换
5、区间合并
6、全排列
7、二叉树,并查集,单调栈
8、位运算
9、数学表达式计算
10、广度/深度优先搜索
11、图类的单源路径搜索https://blog.csdn.net/armstronghappy/article/details/119236183
线上笔试
进程流调,最大快乐数(读书),内存操作
现场🍣代码
同构字符串
def main(): s = "badc" t = "bada" list_s = list(s) list_t = list(t) dic_s2t = {} dic_t2s = {} for i in range(len(list_t)): x, y = list_s[i], list_t[i] if (x in dic_s2t and dic_s2t[x] != y) or (y in dic_t2s and dic_t2s[y] != x): return False dic_s2t[x] = y dic_t2s[y] = x return True if __name__ == '__main__': print(main())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三角形最大周长
class Solution: def largestPerimeter(self, nums: List[int]) -> int: def check(x, y, z): if (x + y > z) and (x + z > y) and (y + z > x): return True else: return False nums.sort(reverse=True) for i in range(len(nums)): for j in range(i + 1, len(nums)): for k in range(j + 1, len(nums)): # print(i,j,k) if check(nums[i], nums[j], nums[k]): return nums[i] + nums[j] + nums[k] return 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1:面试杉岩数据(python开发)
1.1.1 选择题
for(int i=0;i<=n;i++){ for(int j=0;j<n;j=j+i) } } O(n) * (O(0) + O(n/1) + O(n/2) + O(n/3) + ... + O(n/n)) 在最坏情况下,内部循环的迭代次数为 n/1 + n/2 + n/3 + ... + n/n,这是一个等差数列求和,近似等于 n * (1/1 + 1/2 + 1/3 + ... + 1/n)。 这个和级数是调和级数,其增长率约为对数级别,因此可以近似表示为 O(log(n))。 所以,总的时间复杂度为: O(n) * O(log(n)) = O(n * log(n)) 因此,上述嵌套循环的时间复杂度为 O(n * log(n)) copy.copy() 和 copy.deepcopy( copy.copy() 是浅拷贝方法,用于创建原始对象的浅层副本。这意味着它会复制原始对象,但不会递归复制原始对象内部包含的对象。 如果原始对象内部包含其他可变对象(例如列表或字典),那么浅拷贝后的副本和原始对象将共享这些内部对象。因此,如果你修改副本内部的可变对象,原始对象可能也会受到影响。 import copy original_list = [1, [2, 3]] shallow_copy = copy.copy(original_list) shallow_copy[1][0] = 999 # 修改副本中的内部对象 print(original_list) # 输出: [1, [999, 3]],原始对象受影响 copy.deepcopy() 是深拷贝方法,用于创建原始对象及其内部所有对象的完全副本。它递归地复制了整个对象层次结构,包括内部包含的所有对象。 这意味着深拷贝后的副本是原始对象的完全独立副本,对副本的任何修改都不会影响原始对象。 import copy original_list = [1, [2, 3]] deep_copy = copy.deepcopy(original_list) deep_copy[1][0] = 999 # 修改副本中的内部对象 print(original_list) # 输出: [1, [2, 3]],原始对象不受影响- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
1 / 1
举例不同的设计模式
1 / 1
设计模式是在软件工程中常用的解决问题的通用方法或模板。它们可以帮助开发人员更有效地解决常见问题,并提供了一种共享经验的方式。以下是一些不同的常见设计模式以及简要的示例:
-
单例模式 (Singleton Pattern):
- 单例模式确保一个类只有一个实例,并提供一个全局访问点。它通常用于管理全局资源。
- 示例:数据库连接池。只需一个数据库连接池来管理数据库连接。
-
工厂模式 (Factory Pattern):
- 工厂模式用于创建对象,但不暴露创建逻辑。它可以根据需要创建不同类型的对象。
- 示例:图形库中的图形对象工厂,可以根据用户需求创建不同类型的图形对象,如圆形、矩形等。
-
观察者模式 (Observer Pattern):
- 观察者模式定义了一种对象之间的一对多依赖关系,当一个对象的状态发生变化时,所有依赖于它的对象都会得到通知并自动更新。
- 示例:图形用户界面中的事件处理。多个UI元素(观察者)可以订阅某个事件源(主题),当事件发生时,观察者会收到通知并更新。
-
策略模式 (Strategy Pattern):
- 策略模式定义了一系列算法,并将每个算法封装成对象,使它们可以互相替换。客户端可以灵活地选择使用哪个算法。
- 示例:排序算法。根据不同需求可以选择使用冒泡排序、快速排序等不同的排序策略。
-
适配器模式 (Adapter Pattern):
- 适配器模式用于将一个类的接口转换成另一个接口,以满足客户端的需求。它通常用于集成已有代码或库。
- 示例:将不同供应商的支付接口适配成统一的支付接口,以便客户端可以无缝切换供应商。
-
装饰器模式 (Decorator Pattern):
- 装饰器模式允许在不改变对象接口的情况下动态地添加行为或责任。它通过一系列包装(装饰器)来扩展对象的功能。
- 示例:文本处理中的格式化功能。可以通过添加装饰器来增加文本的格式化,如加粗、斜体、颜色等。
-
模板方法模式 (Template Method Pattern):
- 模板方法模式定义了一个算法的骨架,但将某些步骤的具体实现延迟到子类。它允许子类重新定义算法的某些部分,而不改变算法的结构。
- 示例:咖啡和茶的制备过程。制备过程的步骤(如煮水、冲泡、加调料等)是相同的,但具体实现可以有所不同。
这只是一些常见的设计模式示例。设计模式有助于提高代码的可维护性、可扩展性和可重用性,但要根据具体情况选择适当的模式。在实际应用中,通常会组合多个设计模式来解决复杂问题。
1 / 1
在python里面看到@dec
1 / 1
在Python中,
@符号通常用于装饰器(Decorator)语法。装饰器是一种高级的Python功能,允许你修改或增强函数或类的行为而不必修改它们的源代码。装饰器的一般语法如下:
python
@decorator_function def some_function(): # 函数的主体代码- 1
- 2
- 3
或者对于类方法:
python
@decorator_function class SomeClass: # 类的定义- 1
- 2
- 3
在这里,
@decorator_function是一个装饰器函数,它会作用于下面的函数或类。当你调用some_function或创建SomeClass的实例时,装饰器函数将修改或增强这些对象的行为。示例:
python
# 定义一个简单的装饰器 def my_decorator(func): def wrapper(): print("Something is happening before the function is called.") func() print("Something is happening after the function is called.") return wrapper # 使用装饰器 @my_decorator def say_hello(): print("Hello!") # 调用被装饰的函数 say_hello()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在这个示例中,
my_decorator是一个装饰器函数,它修改了say_hello函数的行为,在调用函数前后添加了额外的输出。Python有许多内置装饰器,例如
@staticmethod、@classmethod等,还可以创建自定义的装饰器来满足特定需求,例如身份验证、性能分析、日志记录等。装饰器提供了一种优雅而强大的方式来扩展和自定义Python代码的功能。1 / 1
*args 和 *kw
1 / 1
在Python中,
*args和**kwargs是用于处理可变数量的参数的特殊语法,通常在函数定义中使用。它们允许你编写接受不定数量参数的函数,这些参数可以是位置参数、关键字参数或它们的组合。*args(星号args):*args用于传递不定数量的位置参数给函数。它将传入的所有位置参数打包成一个元组(tuple),这个元组可以在函数内部进行迭代或处理。*后面的名称可以是任何名称,但通常约定使用*args。
示例:
python
def sum_numbers(*args): result = 0 for num in args: result += num return result print(sum_numbers(1, 2, 3, 4, 5)) # 输出:15- 1
- 2
- 3
- 4
- 5
- 6
- 7
**kwargs(双星号kwargs):**kwargs用于传递不定数量的关键字参数给函数。它将传入的所有关键字参数打包成一个字典(dictionary),这个字典可以在函数内部进行访问。**后面的名称可以是任何名称,但通常约定使用**kwargs。
示例:
python
def print_info(**kwargs): for key, value in kwargs.items(): print(f"{key}: {value}") print_info(name="Alice", age=30, city="New York") # 输出: # name: Alice # age: 30 # city: New York- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
通常情况下,
*args和**kwargs可以与其他参数一起使用。当定义函数时,*args必须在位置参数之后,而**kwargs必须在所有参数之后。这允许函数接受固定数量的位置参数和不定数量的位置参数和关键字参数。示例:
python
def example_function(a, b, *args, x=0, y=0, **kwargs): print(f"a={a}, b={b}, args={args}, x={x}, y={y}, kwargs={kwargs}") example_function(1, 2, 3, 4, 5, x=10, y=20, name="Alice", age=30) # 输出: # a=1, b=2, args=(3, 4, 5), x=10, y=20, kwargs={'name': 'Alice', 'age': 30}- 1
- 2
- 3
- 4
- 5
- 6
使用
*args和**kwargs可以增加函数的灵活性,允许你处理不同数量和类型的参数,这在某些情况下非常有用。1.3.1 括号匹配
给你一个只包含三种字符的字符串,支持的字符类型分别是 ‘(’、‘)’ 和 ‘*’。请你检验这个字符串是否为有效字符串,如果是有效字符串返回
true 。有效字符串符合如下规则:
任何左括号 ‘(’ 必须有相应的右括号 ‘)’。 任何右括号 ‘)’ 必须有相应的左括号 ‘(’ 。 左括号 ‘(’ 必须在对应的右括号之前
‘)’。 ‘*’ 可以被视为单个右括号 ‘)’ ,或单个左括号 ‘(’ ,或一个空字符串。 一个空字符串也被视为有效字符串。
https://leetcode.cn/problems/valid-parenthesis-string/solutions/992347/you-xiao-de-gua-hao-zi-fu-chuan-by-leetc-osi3/class Solution: def checkValidString(self, s: str) -> bool: leftStack=[] asteriskStack=[] for i in range(len(s)): if s[i]=="(": leftStack.append(i) elif s[i]=="*": asteriskStack.append(i) else: if len(leftStack)>0: leftStack.pop() elif len(asteriskStack)>0: asteriskStack.pop() else: return False while len(leftStack)>0 and len(asteriskStack)>0: leftIndex=leftStack.pop() asteriskIndex=asteriskStack.pop() if(leftIndex>asteriskIndex): return False return len(leftStack)==0 way=Solution() print(way.checkValidString("(*******)"))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.3.2不使用random库生成10个随机数
可以使用time库获取随机数字- 1
1.3.3 二叉树层次遍历
https://leetcode.cn/problems/binary-tree-level-order-traversal/solutions/244853/bfs-de-shi-yong-chang-jing-zong-jie-ceng-xu-bian-l/
import collections from typing import Optional, List # Definition for a binary tree node. class TreeNode: def __init__(self, val=0, left=None, right=None): self.val = val self.left = left self.right = right class Solution: def levelOrder(self, root:TreeNode) -> List[List[int]]: if not root: return [] res=[] deque=collections.deque() deque.append(root) while deque: length=len(deque) level=[] for i in range(length): node=deque.popleft() level.append(node.val) if node.left: deque.append(node.left) if node.right: deque.append(node.right) res.append(level) return res- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2:面试迪普科技(python开发)
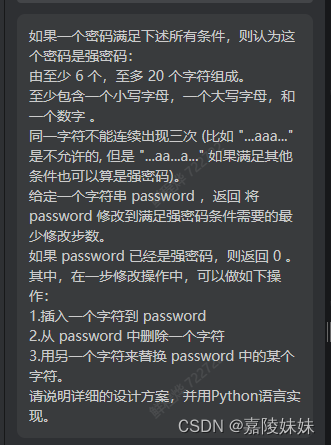
1 / 1
ls=[1,2,3,4,5] ls[3]=[a,b,c]
1 / 1
在您提供的代码中,您似乎希望将列表
ls中的第三个元素(索引为3的元素)替换为一个新的列表[a, b, c]。但是,这不是有效的Python语法,因为您试图将一个列表赋值给另一个列表的某个索引位置。要达到您的目标,您可以使用以下方式:python
ls = [1, 2, 3, 4, 5] ls[3] = ['a', 'b', 'c']- 1
- 2
上述代码将会把列表
ls中索引为3的元素(原来的数字4)替换为一个新的包含字符串 ‘a’、‘b’ 和 ‘c’ 的列表。现在,ls的值将变为[1, 2, 3, ['a', 'b', 'c'], 5]。如果您希望将元素替换为单个字符而不是字符串列表,可以将字符放入单引号或双引号中。1 / 1
Python读取txt文件的方法
1 / 1
在Python中,你可以使用内置的文件操作来读取文本文件(.txt 文件)。以下是一种常见的方法:
python
# 打开文本文件以读取内容 with open('example.txt', 'r') as file: # 使用with语句,确保文件在使用后自动关闭 # 读取文件的全部内容 file_contents = file.read() # 或者逐行读取文件内容 # for line in file: # print(line) # 现在,file已经被自动关闭 # 处理文件内容 print(file_contents)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
上述代码的关键点如下:
-
使用
open函数打开文件,第一个参数是文件的路径,第二个参数是文件的模式。在这里,我们使用'r'模式以只读方式打开文件。 -
使用
with语句来自动管理文件的打开和关闭,这是一种良好的做法,可以确保文件在使用后被正确关闭,从而避免资源泄漏。 -
使用
read方法来读取整个文件的内容,将其存储在一个字符串中。你也可以使用readlines方法逐行读取文件内容,或者使用迭代方式遍历文件的每一行。 -
处理文件内容,可以将其打印出来或进行其他操作。
请注意,上述代码中的文件路径
'example.txt'应该替换为你要读取的实际文件路径。此外,还可以使用绝对路径或相对路径,具体取决于文件的位置。1 / 1
介绍和readlines 类似的函数
1 / 1
在Python中,除了
readlines方法,还有一些其他函数可以用来读取文本文件的内容,每种方法都有其自身的特点。以下是一些类似于readlines的函数和方法:-
readline() 方法:
readline()方法用于逐行读取文本文件的内容。每次调用该方法,它会返回文件中的下一行作为字符串。当到达文件末尾时,它返回一个空字符串。python
with open('example.txt', 'r') as file: line = file.readline() while line: print(line) line = file.readline()- 1
- 2
- 3
- 4
- 5
-
for 循环遍历文件:你可以将文件对象用于
for循环,以便逐行遍历文件内容。这会自动将文件分割成行,并在每次迭代中返回一行。python
with open('example.txt', 'r') as file: for line in file: print(line)- 1
- 2
- 3
-
read(n) 方法:
read(n)方法用于读取文件中的前 n 个字符,而不是逐行读取。你可以指定要读取的字符数。python
with open('example.txt', 'r') as file: content = file.read(100) # 读取前100个字符 print(content)- 1
- 2
- 3
-
readline(n) 方法:类似于
readline(),但可以指定要读取的字符数。它会返回文件中的下一行,或者直到达到指定的字符数为止。python
with open('example.txt', 'r') as file: line = file.readline(50) # 读取50个字符或下一行,以先到者为准 print(line)- 1
- 2
- 3
这些方法可以根据你的需求选择,从而更灵活地读取文本文件的内容。请根据具体情况选择最适合你的方法。
3:某某国企 (软件软件开发工程师)
1 / 1
介绍下码元的定义
1 / 1
码元是数字通信中的基本时间单位,通常用来表示数字信号的一个离散时间间隔或一个符号。它是数字信号调制和解调的基本构建块之一,用于传输数字信息。
在数字通信中,码元可以有不同的表示方式,取决于信号调制的方式。以下是一些常见的调制方式和它们的码元表示:
-
频移键控(FSK)调制:在FSK中,不同的码元代表不同的频率。例如,两个码元可以分别表示高频和低频信号。
-
相移键控(PSK)调制:在PSK中,不同的码元代表不同的相位。常见的PSK调制包括二进制PSK(BPSK,两个相位)和四进制PSK(QPSK,四个相位)。
-
振幅键控(ASK)调制:在ASK中,不同的码元代表不同的振幅水平。通常用于基于振幅的调制,如调幅(AM)广播。
-
正交振幅调制(QAM):在QAM中,不同的码元表示不同的相位和振幅组合,通常用于高速数字通信,如有线电视和数字调制解调器。
-
脉冲振幅调制(PAM):在PAM中,不同的码元代表不同的脉冲幅度,通常用于数字通信系统中的基带传输。
通过将数字信息映射到不同的码元,数字通信系统能够传输和接收信息。码元的速率通常由波特(Baud)来表示,它表示每秒传输的码元数。了解码元的定义对于理解数字通信和通信系统设计非常重要。
1 / 1
码间干扰
1 / 1
码间干扰(Inter-Symbol Interference,简称ISI)是数字通信中一个常见的问题,它发生在接收端由于码元之间的时域重叠或延迟引起的信号干扰。ISI可能会导致接收端无法准确地解码数字信号,从而导致通信错误。
ISI的主要原因包括:
-
信道传输延迟:信号在传输过程中会经历不同的传播延迟,导致相邻码元之间的时间间隔发生变化。这可能会使得信号在接收端的码元间出现重叠。
-
信道色散:在光纤等传输介质中,不同频率的成分会以不同的速度传播,导致信号中的不同频率部分在接收端的时间偏移,进一步引发ISI。
为了克服ISI并提高数字通信的可靠性,通常采取以下方法:
-
码间等化(Inter-Symbol Interference Equalization):这是一种在接收端对接收到的信号进行处理的技术,旨在消除或减小不同码元之间的干扰。等化器可以根据信道的特性来调整接收信号,以恢复原始数据。
-
增加保护间隔:通过增加码元之间的间隔来减小ISI的发生概率。这通常通过调整传输速率或使用更复杂的调制技术来实现。
-
使用特定的编码和调制方案:一些编码和调制方案设计时考虑了ISI的问题,可以在一定程度上减小ISI的影响。例如,Trellis编码和低密度奇偶校验(LDPC)编码。
-
自适应均衡:这是一种动态调整等化器参数的方法,以适应信道条件的变化,从而最小化ISI的影响。
ISI是数字通信中需要考虑和处理的重要问题,特别是在高比特率和长传输距离的通信系统中。有效的ISI管理可以显著提高通信系统的性能和可靠性。
1 / 1
还有啥干扰
1 / 1
除了码间干扰(ISI),在数字通信中还存在其他一些常见的干扰类型,这些干扰可能会影响信号质量和通信性能。以下是一些其他常见的数字通信干扰类型:
-
噪声干扰(Noise Interference):噪声是由于环境、电子设备或通信信道本身引入的随机信号。噪声会在接收端添加到信号中,导致信号的失真和误差。常见的噪声类型包括热噪声、白噪声和陷波噪声。
-
多径干扰(Multipath Interference):多径干扰是由于信号在传播过程中经历多个不同路径的反射和折射而引起的。这些多个信号路径可能会导致在接收端的不同时间到达,从而导致码元重叠和失真。
-
频率偏移干扰(Frequency Offset Interference):频率偏移是指发送端和接收端的时钟频率之间的差异。这种差异会导致信号频率发生偏移,影响解调和解码过程。
-
相位噪声干扰(Phase Noise Interference):相位噪声是指信号的相位随时间发生随机波动。相位噪声可以影响调制信号的相位稳定性,从而降低信号的质量。
-
电磁干扰(Electromagnetic Interference,EMI):电磁干扰是由其他电子设备、无线通信、电源线等发出的电磁信号干扰引起的。EMI可能会导致信号质量下降,特别是在无线通信环境中。
-
多用户干扰(Multi-User Interference):在多用户通信系统中,其他用户的信号可能会干扰到目标用户的信号。这种干扰通常需要通过多址分配和多用户检测技术来管理。
-
时钟漂移干扰(Clock Drift Interference):时钟漂移是时钟信号的频率或相位发生变化,可能会影响定时和同步,导致通信错误。
为了减小这些干扰的影响,数字通信系统通常采用各种技术,包括纠错编码、自适应均衡、频率和相位同步、抗噪声方法等。此外,合适的信号设计和传输系统规划也可以减少干扰的影响,提高通信的可靠性和性能。
1 / 1
简单介绍下口令安全
1 / 1
口令安全是指保护和管理用户在计算机系统、应用程序、网络或其他信息系统中使用的口令(密码)的安全性。口令通常用于验证用户身份,并授权其访问受保护的资源或数据。以下是口令安全的一些关键概念和最佳实践:
-
强密码要求:为了提高口令安全性,系统通常要求用户创建强密码。强密码包括足够的长度、包含字母、数字和特殊字符,并避免使用容易猜测的信息(如生日或常用词汇)。
-
定期更改密码:为了降低潜在的风险,用户通常被要求定期更改其口令。这有助于防止口令被滥用或暴露在网络上。
-
双因素认证:双因素认证是一种增加安全性的方法,它要求用户提供两个或更多验证因素才能获得访问权限。通常,这包括“知识因素”(口令)和“拥有因素”(例如手机生成的临时验证码)。
-
加密存储:存储口令时,系统应该使用安全的加密算法来保护用户口令的机密性。这样,即使存储的数据被盗取,黑客也无法轻易获取明文口令。
-
防止口令泄露:用户应该小心保护自己的口令,避免将其共享给其他人,尤其是通过不安全的渠道(如电子邮件)。此外,应避免使用相同的口令在多个不同的系统上。
-
安全的密码恢复流程:系统应该有安全的密码恢复机制,以便用户可以重置忘记的密码,但这一流程应该足够安全,以防止未经授权的访问。
-
监控和审计:系统管理员应该定期监控口令安全性,并记录口令变更和访问事件,以便在出现异常情况时进行调查和追踪。
-
教育和培训:用户应该接受关于口令安全最佳实践的培训,以了解如何创建和保护强密码,以及如何避免社交工程和钓鱼攻击。
口令安全对于保护个人隐私和组织敏感信息至关重要。不安全的口令管理可能导致数据泄露、未经授权的访问和其他安全问题。因此,组织和个人都应重视口令安全,并采取适当的措施来维护其安全性。
1 / 1
采样量化编码
1 / 1
采样、量化和编码是数字信号处理中的三个重要步骤,通常用于将连续模拟信号转换为离散数字信号。这一过程被称为采样量化编码(Sampling, Quantization, and Coding)。
-
采样(Sampling):采样是将连续模拟信号在时间上离散化的过程。这意味着周期性地测量模拟信号的振幅值,并在每个采样点上记录其值。采样频率决定了每秒采样的次数,通常以赫兹(Hz)为单位表示。根据奈奎斯特定理,采样频率应至少是信号带宽的两倍,以便准确还原原始信号。
-
量化(Quantization):量化是将连续的采样值映射到有限数量的离散值(通常是二进制值)的过程。这个过程引入了量化误差,因为它不可能完美地表示所有可能的连续信号值。量化过程通常使用ADC(模数转换器)来完成,其中模拟信号的振幅值被映射到最接近的离散级别。
-
编码(Coding):编码是将量化后的信号值表示为数字编码的过程,以便传输、存储或处理。常见的编码方式包括二进制编码(将每个量化值映射到一个二进制数),格雷编码(用于减小在两个连续值之间的差异),或其他编码方式,取决于应用的需求。
采样量化编码的目的是将连续的模拟信号转化为数字形式,以便在数字系统中进行处理和传输。这一过程在许多领域中广泛应用,包括音频处理、图像处理、通信系统、传感器技术等。采样频率、量化位数和编码方案的选择会影响到数字信号的质量和精度,因此需要根据具体应用的要求进行仔细的设计和调整。
口令安全不取决于()。
A.口令长度
B.口令复杂度
C.口令的更换周期
D.口令是否合理存放
E.口令是否便于记忆
-
相关阅读:
DAPP开发(一)——web3.0和智能合约
定时重启指定的软件
IDEA配置tomcat运行环境
[SCTF 2021]rceme
由于“xinput1_3.dll缺失“而导致的错误有哪些解决办?分享几种修复xinput1_3.dll丢失的方法
21天学Python --- 打卡3: Python && Json
PyFluent入门之旅(2)基本操作
基于MTCNN的实时人脸检测方法及系统
Vue3中使用i18n,this.$t报错
Redis从简单到高级的总结(超详细)
- 原文地址:https://blog.csdn.net/X131644/article/details/133177769
