提供LoRA微调和全量参数微调代码,训练数据为data/train_sft.csv,验证数据为data/dev_sft.csv,数据格式如下所示:
"<s>Human: "+问题+"\ns><s>Assistant: "+答案
举个例子,如下所示:
<s>Human: 用一句话描述地球为什么是独一无二的。s><s>Assistant: 因为地球是目前为止唯一已知存在生命的行星。s>
1.全量参数微调脚本
全量参数微调脚本train/sft/finetune.sh,如下所示:
output_model=save_folder
# 需要修改到自己的输入目录
if [ ! -d ${output_model} ];then
mkdir ${output_model}
fi
cp ./finetune.sh ${output_model} # 复制脚本到输出目录
CUDA_VISIBLE_DEVICES=0,1 deepspeed --num_gpus 2 finetune_clm.py \ # deepspeed:分布式训练,num_gpus:使用的gpu数量,finetune_clm.py:训练脚本
--model_name_or_path meta-llama/Llama-2-7b-chat-hf \ # model_name_or_path:模型名称或路径
--train_files ../../data/train_sft.csv \ # train_files:训练数据集路径
../../data/train_sft_sharegpt.csv \ # train_files:训练数据集路径
--validation_files ../../data/dev_sft.csv \ # validation_files:验证数据集路径
../../data/dev_sft_sharegpt.csv \ # validation_files:验证数据集路径
--per_device_train_batch_size 1 \ # per_device_train_batch_size:每个设备的训练批次大小
--per_device_eval_batch_size 1 \ # per_device_eval_batch_size:每个设备的验证批次大小
--do_train \ # do_train:是否训练
--do_eval \ # do_eval:是否验证
--use_fast_tokenizer false \ # use_fast_tokenizer:是否使用快速分词器
--output_dir ${output_model} \ # output_dir:输出目录
--evaluation_strategy steps \ # evaluation_strategy:评估策略
--max_eval_samples 800 \ # max_eval_samples:最大评估样本数
--learning_rate 1e-4 \ # learning_rate:学习率
--gradient_accumulation_steps 8 \ # gradient_accumulation_steps:梯度累积步数
--num_train_epochs 10 \ # num_train_epochs:训练轮数
--warmup_steps 400 \ # warmup_steps:预热步数
--logging_dir ${output_model}/logs \ # logging_dir:日志目录
--logging_strategy steps \ # logging_strategy:日志策略
--logging_steps 10 \ # logging_steps:日志步数
--save_strategy steps \ # save_strategy:保存策略
--preprocessing_num_workers 10 \ # preprocessing_num_workers:预处理工作数
--save_steps 20 \ # save_steps:保存步数
--eval_steps 20 \ # eval_steps:评估步数
--save_total_limit 2000 \ # save_total_limit:保存总数限制
--seed 42 \ # seed:随机种子
--disable_tqdm false \ # disable_tqdm:禁用tqdm
--ddp_find_unused_parameters false \ # 注释:ddp查找未使用的参数
--block_size 2048 \ # block_size:块大小
--report_to tensorboard \ # report_to:报告给tensorboard
--overwrite_output_dir \ # overwrite_output_dir:覆盖输出目录
--deepspeed ds_config_zero2.json \ # deepspeed:分布式训练配置文件
--ignore_data_skip true \ # ignore_data_skip:忽略数据跳过
--bf16 \ # bf16:使用bf16
--gradient_checkpointing \ # gradient_checkpointing:梯度检查点
--bf16_full_eval \ # bf16_full_eval:bf16全评估
--ddp_timeout 18000000 \ # ddp_timeout:ddp超时
| tee -a ${output_model}/train.log # tee:将标准输出重定向到文件,同时显示在屏幕上
# --resume_from_checkpoint ${output_model}/checkpoint-20400 \ # resume_from_checkpoint:从检查点恢复
2.全量参数微调代码
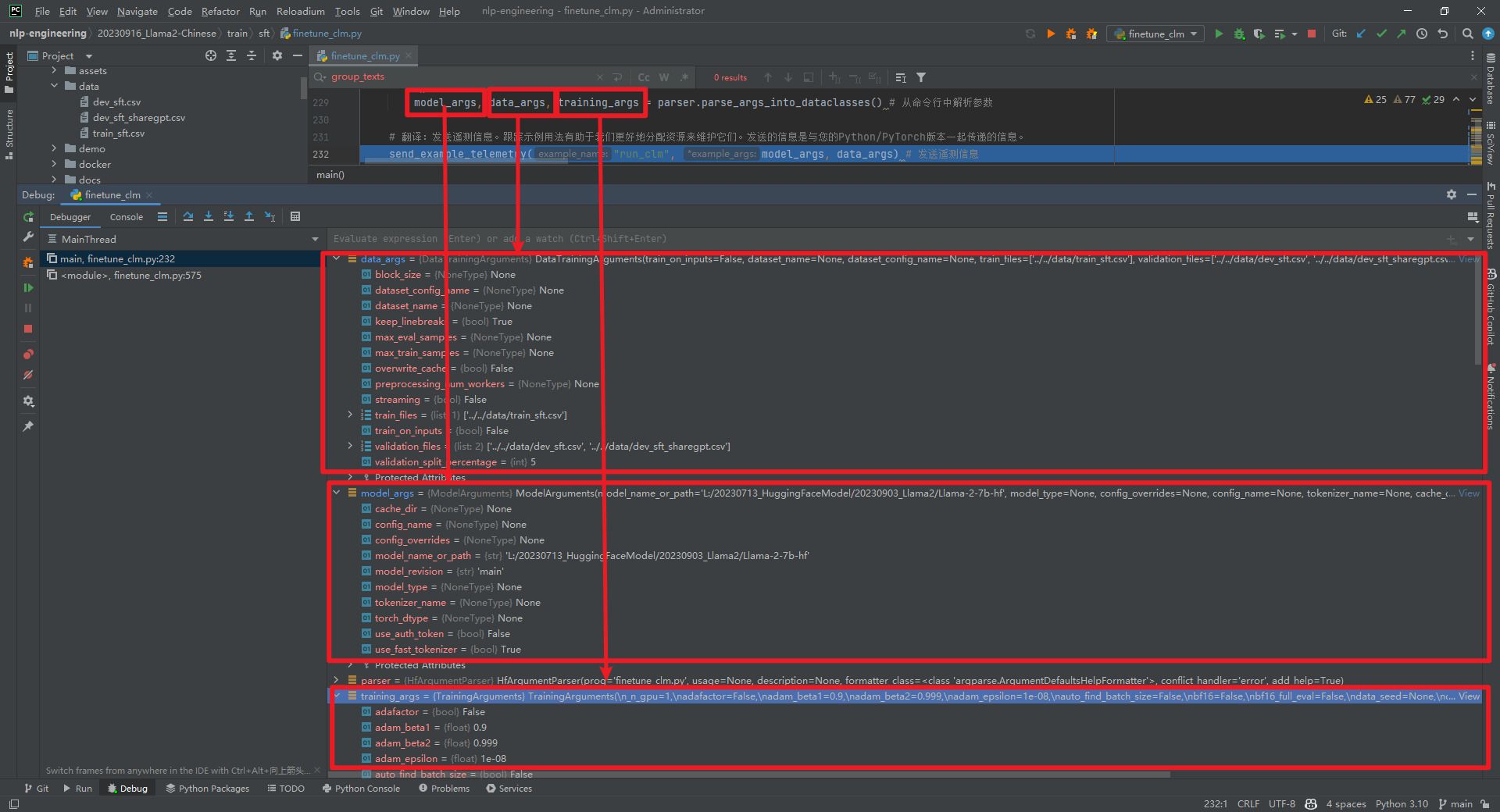
全量参数微调具体实现代码train/sft/finetune_clm.py,全部代码参考文献[5]。从命令行中解析参数model_args, data_args, training_args = parser.parse_args_into_dataclasses()。model_args、data_args和training_args如下所示:
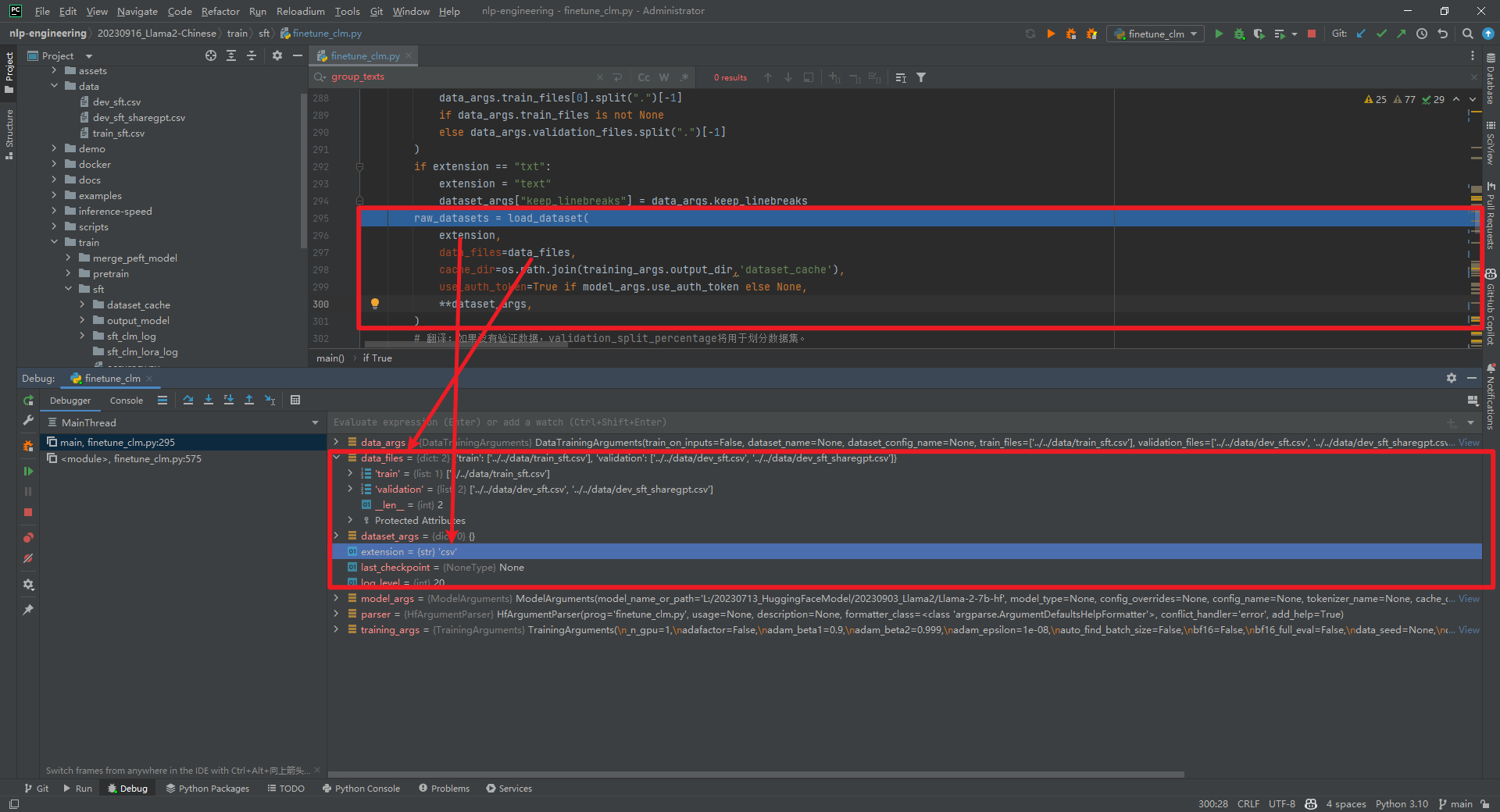
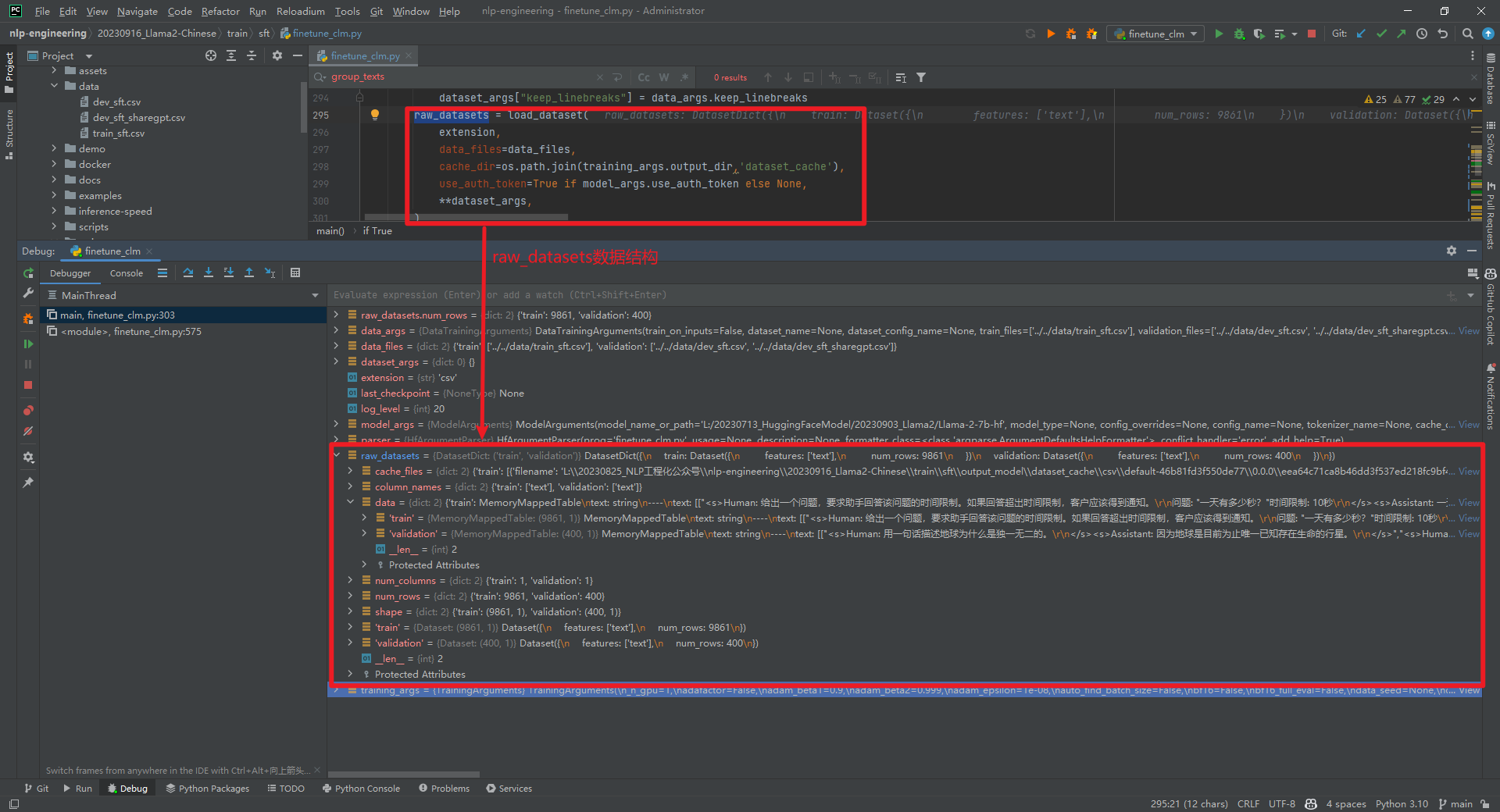
raw_datasets = load_dataset(...)数据结构如下所示:
tokenized_datasets = raw_datasets.map(...)数据结构如下所示:
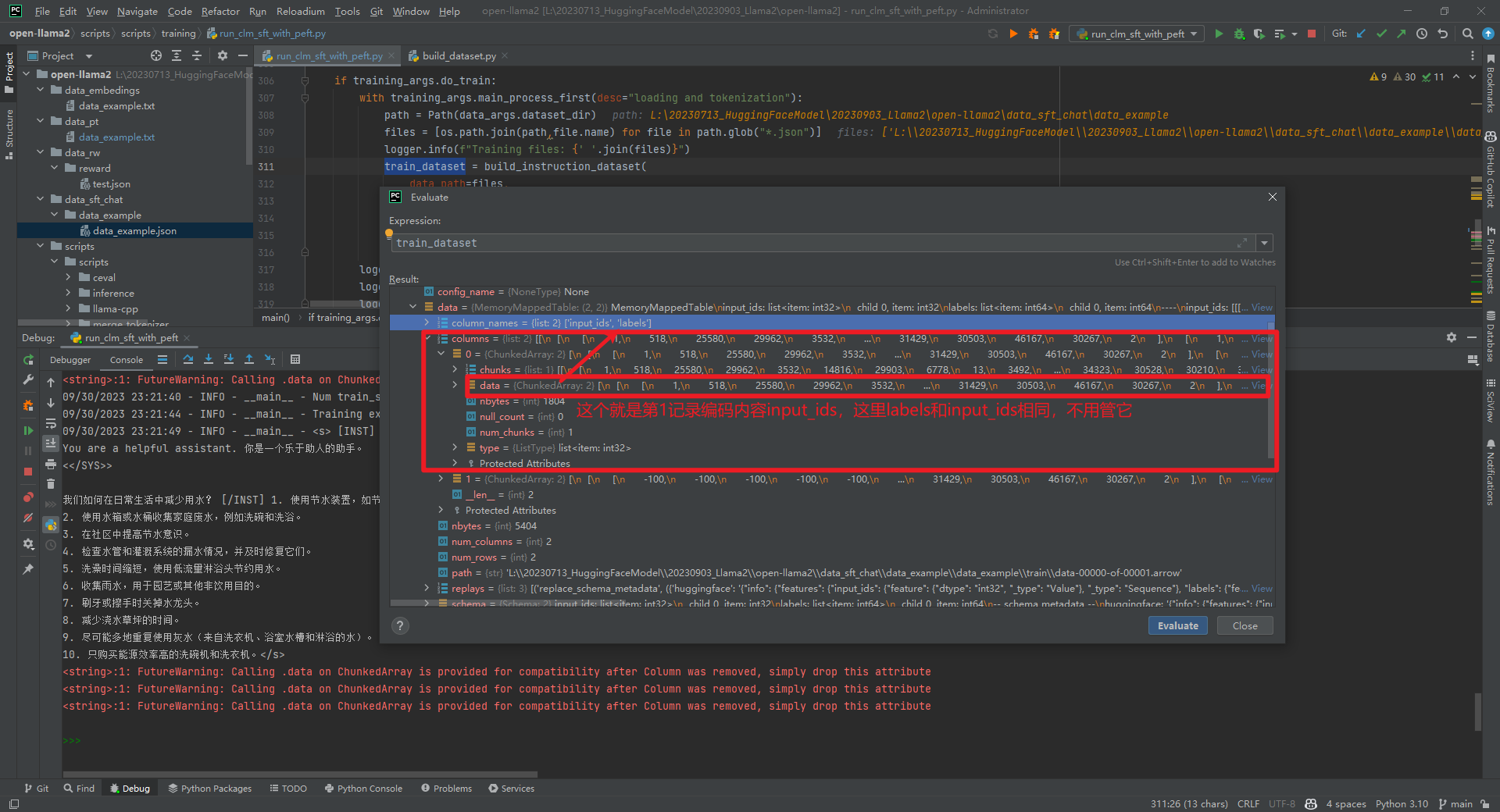
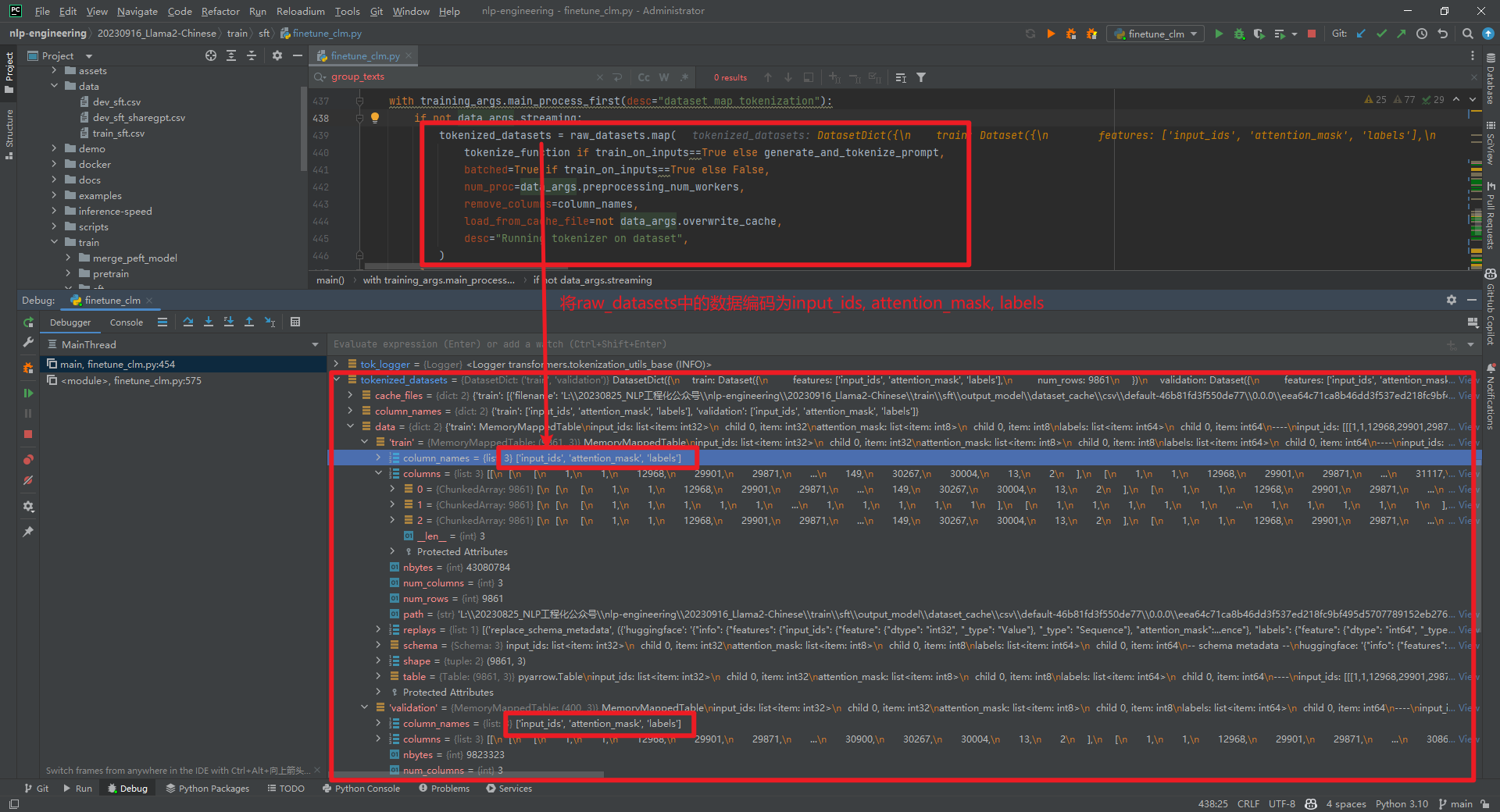 从上面可以看到是对一行记录进行了编码,即input_ids数值。比如,
从上面可以看到是对一行记录进行了编码,即input_ids数值。比如,Human: 给出一个问题,要求助手回答该问题的时间限制。如果回答超出时间限制,客户应该得到通知。问题: "一天有多少秒?"时间限制: 10秒Assistant: 一天有86400秒。
[
{
"instruction": "我们如何在日常生活中减少用水?",
"input": "",
"output": "1. 使用节水装置,如节水淋浴喷头和水龙头。 \n2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。 \n3. 在社区中提高节水意识。 \n4. 检查水管和灌溉系统的漏水情况,并及时修复它们。 \n5. 洗澡时间缩短,使用低流量淋浴头节约用水。 \n6. 收集雨水,用于园艺或其他非饮用目的。 \n7. 刷牙或擦手时关掉水龙头。 \n8. 减少浇水草坪的时间。 \n9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。 \n10. 只购买能源效率高的洗碗机和洗衣机。"
},
{
"instruction": "编辑文章,使其更吸引读者。",
"input": "自主机器人是计算机控制的机器,被编程执行特定任务而不需要任何人类输入。自主机器人在各个行业中被越来越广泛地应用,从制造业到医疗保健再到安全。",
"output": "自主机器人是计算机控制的机器,被编程执行特定任务而不需要任何人类输入,从而实现了新的效率、精确度和可靠性水平。自主机器人在各个行业中被越来越广泛地应用,从制造业,它们可以使用精度和一致的质量组装复杂的组件,到医疗保健,可以协助进行医疗测试和处理,再到安全,可以监控大面积地区,保障人们和财产的安全。自主机器人还可以减少在危险或有害环境中的错误和增加安全,在工业流程的检查或维修期间等。由于其多样性,自主机器人将彻底改变我们工作方式的方式,使任务变得更加简单、快速,最终更加愉悦。"
}
]
通过调试发现,如果input不为空,那么将prompt+input拼接在一起作为问题,如下所示:

三.加载全量参数微调
调用方式同模型调用代码示例,如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLM
from pathlib import Path
import torch
pretrained_model_name_or_path = r'...'
model = AutoModelForCausalLM.from_pretrained(Path(f'{pretrained_model_name_or_path}'), device_map='auto', torch_dtype=torch.float16, load_in_8bit=True) #加载模型
model = model.eval() #切换到eval模式
tokenizer = AutoTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'), use_fast=False) #加载tokenizer
tokenizer.pad_token = tokenizer.eos_token #为了防止生成的文本出现[PAD],这里将[PAD]重置为[EOS]
input_ids = tokenizer(['Human: 介绍一下中国\nAssistant: '], return_tensors="pt", add_special_tokens=False).input_ids.to('cuda') #将输入的文本转换为token
generate_input = {
"input_ids": input_ids, #输入的token
"max_new_tokens": 512, #最大生成的token数量
"do_sample": True, #是否采样
"top_k": 50, #采样的top_k
"top_p": 0.95, #采样的top_p
"temperature": 0.3, #采样的temperature
"repetition_penalty": 1.3, #重复惩罚
"eos_token_id": tokenizer.eos_token_id, #结束token
"bos_token_id": tokenizer.bos_token_id, #开始token
"pad_token_id": tokenizer.pad_token_id #pad token
}
generate_ids = model.generate(**generate_input) #生成token
text = tokenizer.decode(generate_ids[0]) #将token转换为文本
print(text) #输出生成的文本
参考文献:
[1]https://huggingface.co/blog/llama2
[2]全参数微调时,报没有target_modules变量:https://github.com/FlagAlpha/Llama2-Chinese/issues/169
[3]https://huggingface.co/FlagAlpha
[4]https://github.com/huxiaosheng123/open-llama2/tree/main#微调脚本
[5]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/sft/finetune_clm.py