-
利用mAP计算yolo精确度
当将yolo算法移植部署在嵌入式设备上,为了验证算法的准确率。将模型测试的结果保存为txt文件(每一个txt文件,对应一个图片)。此外,需要将数据集中的标签由[x,y,w,h]转为[x1,y1,x2,y2]。最后,运行验证代码
标签格式转换
yolo格式的txt文件,保存的坐标信息是中心点和框的高宽。如果我们要进行训练和验证的话,那么需要将yolo格式的坐标进行转换成框的左上角的坐标和右下角的坐标。
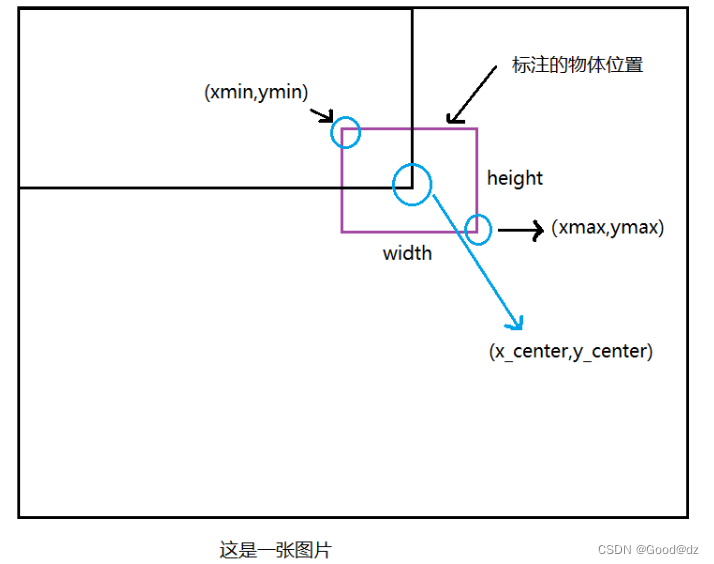
转换原理和公式如下:

下面的代码-将数据集中的标签由[x,y,w,h]转为[x1,y1,x2,y2]
import cv2 import os import numpy as np def Xmin_Ymin_Xmax_Ymax(img_path,txt_path,save_path): """ :param img_path: 图片文件的路径 :param txt_path: 坐标文件的路径 :return: """ img = cv2.imread(img_path) # 获取图片的高宽 h, w, _ = img.shape with open(save_path, "w+") as file: pass # 什么都不写入文件,把txt文件的内容清空 # 坐标转换,原始存储的是YOLOv5格式 # from [x, y, w, h] normalized to [x1, y1, x2, y2] with open(txt_path, "r") as file: for line in file: # 在这里处理每一行的内容 contline=line.split(' ') #计算框的左上角坐标和右下角坐标,使用strip将首尾空格去掉 xmin=float((contline[1]).strip())-float(contline[3].strip())/2 xmax=float(contline[1].strip())+float(contline[3].strip())/2 ymin = float(contline[2].strip()) - float(contline[4].strip()) / 2 ymax = float(contline[2].strip()) + float(contline[4].strip()) / 2 #将坐标(0-1之间的值)还原回在图片中实际的坐标位置---因此YOLOv5格式保存到x, y, w, h都是归一化后 xmin,xmax=w*xmin,w*xmax ymin,ymax=h*ymin,h*ymax datasets=str(contline[0])+' '+str(xmin)+' '+str(ymin)+' '+str(xmax)+' '+str(ymax)+'\n' with open(save_path,'a') as fp: fp.write(datasets) # #打印查看保存后txt的内容 # with open(save_path, "r") as file: # for line in file: # contline=line.split(' ') # print(contline) return (contline[0],xmin,ymin,xmax,ymax) #将所有转换之后的实际坐标保存到新的txt文件当中 def writeXYToTxt(): """ :return: """ imgsPath='input/images-optional' txtsPath='input/ground-truth_zxd' save_path='input/ground-truth/' imgs=os.listdir(imgsPath) txts=os.listdir(txtsPath) for img_,txt_ in zip(imgs,txts): img_path=os.path.join(imgsPath,img_) txt_path=os.path.join(txtsPath,txt_) Xmin_Ymin_Xmax_Ymax(img_path=img_path,txt_path=txt_path,save_path = save_path+txt_) if __name__ == '__main__': writeXYToTxt()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
参考链接:LabelImg标注的YOLO格式txt标签中心坐标和物体边界框长宽的转换
测试结果验证
使用PASCAL VOC 2012比赛中定义的mAP标准进行评判。通过计算真实标签中存在的每个类别的平均精度(AP),并计算mAP(平均精度)值以作为算法精度的性能指标。
TP TN FP FN的概念
- TP(True Positives)意思就是被分为了正样本,而且分对了。
- TN(True Negatives)意思就是被分为了负样本,而且分对了,
- FP(False Positives)意思就是被分为了正样本,但是分错了(事实上这个样本是负样本)。
- FN(False Negatives)意思就是被分为了负样本,但是分错了(事实上这个样本是正样本)。
mAP,其中代表P(Precision)精确率。AP(Average precision)单类标签平均(各个召回率中最大精确率的平均数)的精确率,mAP(Mean Average Precision)所有类标签的平均精确率。
备注:- mAP@0.5: mean Average Precision(IoU=0.5)。即将IoU设为0.5时,计算每一类的所有图片的AP,然后所有类别求平均,即mAP。
- mAP@.5:.95(mAP@[.5:.95])表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
准确率=预测正确的样本数/所有样本数,即预测正确的样本比例(包括预测正确的正样本和预测正确的负样本,不过在目标检测领域,没有预测正确的负样本这一说法,所以目标检测里面没有用Accuracy的)。
精确率也称查准率,Precision翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”。
召回率Recall:和Precision一样,脱离类别是没有意义的。说道Recall,一定指的是某个类别的Recall。Recall表示某一类样本,预测正确的与所有Ground Truth的比例。
Recall翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”。

AP指单个类别平均精确度,而mAP是所有类别的平均精确度
AP事实上指的是,利用不同的Precision和Recall的点的组合,画出来的曲线下面的面积。

当我们取不同的置信度,可以获得不同的Precision和不同的Recall,当我们取得置信度够密集的时候,就可以获得非常多的Precision和Recall。此时Precision和Recall可以在图片上画出一条线,这条线下部分的面积就是某个类的AP值。
mAP就是所有的类的AP值求平均。备注:具体实现可以下这个视频–目标检测mAP计算以及coco评价标准
绘制mAP
第一:首先在github上下载绘制mAP所需的代码:https://github.com/Cartucho/mAP
第二:在下载的代码中,将模型预测结果的txt文件放在detection-results文件夹中。预测标签的格式- 1
要注意的是:模型预测的置信度阈值要设置低一点,可以设置为0.05。

第二:在下载的代码中,将真实标签结果的txt文件放在ground-truth文件夹中。真实标签的格式[ ] - 1
第三:在下载的代码中,将原始图片放在image-optional文件夹中。其中,图片用于可视化,但是如果不需要可视化,可以不放在图片。
参考链接:
1、睿智的目标检测20——利用mAP计算目标检测精确度
2、史上最全AP、mAP详解与代码实现 -
相关阅读:
java编程基础总结——24.Map接口及其实现子类
性能优化之节流
Coredump
“智能语音指令解析“ 基于NLP与语音识别的工单关键信息提取
sort by 和 order by 的区别
【RSocket】使用 RSocket(二)——四种通信模式实践
基于springboot在线考试报名系统毕业设计源码031706
前端-vue基础24-循环结构
多源最短路径算法 -- 弗洛伊德(Floyd)算法
ZooKeeper面试那些事儿
- 原文地址:https://blog.csdn.net/qq_42178122/article/details/133428014