-
MYSQL——二、理论基础
一、什么是数据库
数据: 描述事物的符号记录, 可以是数字、 文字、图形、图像、声音、语言等,数据有多种形式,它们都可以经过数字化后存入计算机。
数据库: 存储数据的仓库,是长期存放在计算机内、有组织、可共享的大量数据的集合。数据库中的数据按照一定数据模型组织、描述和存储,具有较小的冗余度,较高的独立性和易扩展性,并为各种用户共享,总结为以下几点:
- 1、数据结构化
- 2、数据的共享性高,冗余度低,易扩充
- 3、数据独立性高
- 4、数据由 DBMS 统一管理和控制(安全性、完整性、并发控制、故障恢复)
数据库原理:
- 数据库是一些相关数据的集合,可以使用一定的原则以及方法进行添加、编辑以及删除数据的内容,进而对所有数据进行搜索、分析以及优化,最后得到可用的信息以及所需的结果。
- 每一个数据表都是由一个一个字段组合起来,只要按照一个一个字段的设置输入数据,就可以完成一个完整的数据库。
二、数据库管理系统(DBMS)
数据库系统成熟的标志就是数据库管理系统的出现。数据库管理系统(DataBase Management System,简称DBMS)是管理数据库的一个软件,它充当所有数据的知识库,并对它的存储、安全、一致性、并发操作、恢复和访问负责。是对数据库的一种完整和统一的管理和控制机制。
数据库管理系统不仅让我们能够实现对数据的快速检索和维护,还为数据的安全性、完整性、并发控制和数据恢复提供了保证。数据库管理系统的核心是一个用来存储大量数据的数据库。DBMS是所有数据的知识库,并对数据的存储、安全、一致性、并发操作、恢复和访问负责。
DBMS有一个数据字典(有时被称为系统表),用于贮存它拥有的每个事物的相关信息,例如名字、结构、位置和类型,这种关于数据的数据也被称为元数据(metadata)。
三、数据库与文件系统的区别
-
文件系统: 文件系统是操作系统用于明确存储设备(常见的是磁盘)或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。
-
数据库系统: 数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称 DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。
对比区别:
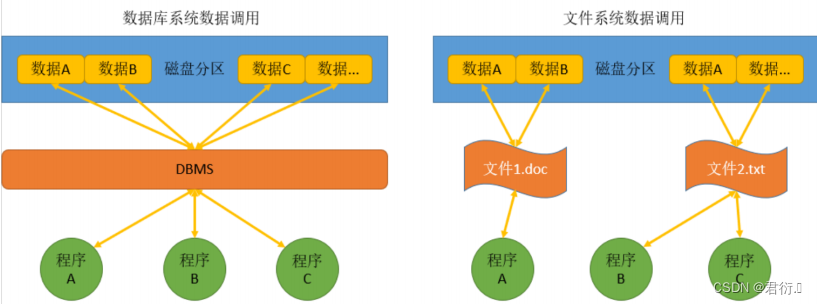
- 管理对象不同: 文件系统的管理对象是文件,并非直接对数据进行管理,不同的数据结构需要使用不同的文件类型进行保存(举例: txt 文件和 doc 文件不能通过修改文件名完成转换) ;而数据库直接对数据进行存储和管理
- 存储方式不同:文件系统使用不同的文件将数据分类(.doc/.mp4/.jpg) 保存在外部存储上;数据库系统使用标准统一的数据类型进行数据保存(字母、 数字、符号、时间)
- 调用数据的方式不同:文件系统使用不同的软件打开不同类型的文件;数据库系统由 DBMS 统一调用和管理。
优缺点总结:
- 由于 DBMS 的存在,用户不再需要了解数据存储和其他实现的细节,直接通过 DBMS 就能获取数据,为数据的使用带来极大便利。
- 具有以数据为单位的共享性,具有数据的并发访问能力。 DBMS 保证了在并发访问时数据的一致性。
- 低延时访问,典型例子就是线下支付系统的应用,支付规模巨大的时候,数据库系统的表现远远优于文件系统。
- 能够较为频繁的对数据进行修改,在需要频繁修改数据的场景下,数据库系统可以依赖 DBMS 来对数据进行操作且对性能的消耗相比文件系统比较小。
- 对事务的支持。 DBMS 支持事务,即一系列对数据的操作集合要么都完成, 要么都不完成。在DBMS上对数据的各种操作都是原子级的。
四、数据库技术构成及发展史
1、技术构成
- 数据库系统
数据库系统有3个主要的组成部分: -
- 数据库:用于存储数据的地方
-
- 数据库管理系统:用于管理数据库的软件
-
- 数据库应用程序:为了提高数据库系统的处理能力所使用的管理数据库的软件补充
- SQL语言
SQL语言包含以下4部分: -
- 1、数据定义语言(DDL):DROP、CREATE、ALTER语句
-
- 2、数据操作语言(DML):INSERT(插入)、UPDATE(修改)、DELETE(删除)语句
-
- 3、数据查询语言(DQL):SELECT语句
-
- 4、数据控制语言(DCL):GRANT、REVOKE、COMMIT、ROLLBACK语句
- 数据库访问技术
不同的程序设计语言会有各自不同的数据库访问技术、程序语言通过这些技术、执行SQL语句,进行数据库管理,主要的数据库访问技术有: -
- 1、ODBC
-
- 2、JDBC
-
- 3、ADO、NET
-
- 4、PDO
2、发展史
初始阶段-----人工管理:人力手工整理存储数据
萌芽阶段-----文件系统:使用磁盘文件来存储数据
初级阶段-----第一代数据库:出现了网状模型、层次模型的数据库
中级阶段-----第二代数据库:关系型数据库和结构化查询语言
高级阶段------新一代数据库:NOSQL型数据库五、常见数据库
1、关系型数据库
- 关系型数据库是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。 简单说,关系型数据库是由多张能互相联接的二维行列表格组成的数据库。
- 关系模型就是指二维表格模型, 因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。当前主流的关系型数据库有Oracle、DB2、Microsoft SQL Server、MicrosoftAccess、MySQL、浪潮K-DB 、武汉达梦、南大通用、人大金仓等。
- 实体关系模型简称 E-R 模型,是一套数据库的设计工具,它运用真实世界中事物与关系的观念,来解释数据库中的抽象的数据架构。实体关系模型利用图形的方式(实体-关系图)来表示数据库的概念设计,有助于设计过程中的构思及沟通讨论。
2、ACID原则
关系型数据库强调ACID规则
(即:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)),可以满足对事务性要求较高或者需要进行复杂数据查询的数据操作,而且可以充分满足数据库操作的高性能和操作稳定性的要求。并且关系型数据库十分强调数据的强一致性,对于事务的操作有很好的支持。关系型数据库可以控制事务原子性细粒度,并且一旦操作有误或者有需要,可以马上回滚事务。面试题对于关系型数据库来说具备的四大特性:
- 原子性,事务里的所有操作要么全部做完,要么都不做。(一个事务要么完全提交要么完全回滚,不会结余二者之间)
例:从A账户向B账户转1000元,往账户B加上1000,所以在此案例中必须具备原子性才能保证不出现意外问题。(原子性,一致性(不管谁发起转账以及是否成功A,B账户的存款总额不变)) - 一致性,数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。(发起一个查询后不管数据发生多少变化,查询结果应当为发起查询时间一致的数据)
- 隔离性,是指并发的事务之间不会互相影响。(提交不同事务时显示的效果是串行的换句话说,不同事务按照提交的先后顺序执行)
- 持久性,一旦事务提交后,它所做的修改将会永久的保存在数据库上。
3、关系型数据库的优缺点
优点:
- 1、易于维护:都是使用表结构,格式一致;
- 2、使用方便:SQL语言通用,可用于复杂查询;
- 3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
- 1、读写性能比较差,尤其是海量数据的高效率读写;
- 2、固定的表结构,灵活度稍欠;
- 3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
4、非关系型数据库
- 1、含义:
非关系型数据库,又被称为NoSQL(Not Only SQL ),意为不仅仅是SQL( Structured QueryLanguage,结构化查询语言),据维基百科介绍,NoSQL最早出现于1998 年,是由Carlo Storzzi最早开发的个轻量、开源、不兼容SQL 功能的关系型数据库,2009 年,在一次分布式开源数据库的讨论会上,再次提出了NoSQL 的概念,此时NoSQL主要是指非关系型、分布式、不提供ACID (数据库事务处理的四个基本要素)的数据库设计模式。同年,在亚特兰大举行的“NoSQL(east)”讨论会上,对NoSQL 最普遍的定义是“非关联型的”,强调Key-Value 存储和文档数据库的优点,而不是单纯地反对RDBMS,至此,NoSQL 开始正式出现在世人面前。
(存储方式有更多的选择:"键-值"对存储,列存储,文档存储,图形数据库等,没有声明性查询语言,没有预定义的模式,非结构化和不可预知的数据,高性能,高可用性和可伸缩性。)
- 2、常见的非关系型数据库有Redis, Amazon DynamoDB, Memcached,Microsoft Azure Cosmos DB和Hazelcast
- 3、不遵循ACID原则
- 4、使用范围:分布式数据库,近几年分布式数据库用的比较火的是redis
5、非关系数据库的优点
高可扩展性;分布式计算;低成本;架构的灵活性;没有复杂的关系。缺点:没有标准化;有限的查询功能
6、DBMS支持的数据模型
层次模型
若用图来表示,层次模型是一棵倒立的树。在数据库中,满足以下条件的数据模型称为层次模型:- 有且仅有一个节点无父节点,这个节点称为根节点
- 其他节点有且仅有一个父节点。桌面型的关系模型数据库
网状模型
在现实世界中,事物之间的联系更多的是非层次关系的,用层次模型表示非树型结构是很不直接的,网状模型则可以克服这一弊病。网状模型是一个网络。在数据库中,满足以下两个条件的数据模型称为网状模型。A.允许一个以上的节点无父节点;B.一个节点可以有多于一个的父节点。
从以上定义看出,网状模型构成了比层次结构复杂的网状结构,适宜表示
关系模型
以二维表的形式表示实体和实体之间联系的数据模型称为关系数据模型。从模型的三要素角度看,关系模型的内容为:
数据结构:一张二维表格。
数据操作:数据表的定义、检索、维护、计算等。
数据约束条件:表中列的取值范围即域值的限制条件。
概念模型: 基于客户的想法和观点所形成的认识和抽象。
实体(Entity):客观存在的、可以被描述的事物。例如员工、部门。
属性(Attribute):用于描述实体所具有的特征或特性。如使用编号、姓名、工资等来属性来描述员工的特征。
关系(Relationship):实体之间的联系。一对一: 人 和 身份证
一对多: 班级 和 学生
多对多: 学生 和 课程数据模型: 也叫关系模型,是实体、属性、关系在数据库中的具体体现。
关系数据库:用于存储各种类型数据的”仓库”,是二维表的集合。
表:实体的映射
行和列:行代表一个具体的实体的数据。也叫一条记录。列是属性的映射,用于描述实体的。
主键和外键。7、运维对数据库的要求
7.1 程序员对数据库要求
- 基本的SQL操作、CRUD操作
- 多表连接查询、分组查询和子查询。
- 常用数据库的的单行函数。
- 常用数据库的基本命令。
- 常用数据库的开发工具。
- 事务概念。
- 索引、视图、存储过程和触发器。
7.2 运维对数据库要求
- 部署环境
- 数据库安装、参数配置、权限分配
- 备份/还原
- 监控
- 故障处理
- 性能优化
- 容灾
- 升级/迁移
- 系统用户反馈的数据库问题
7.3 数据库运维工作总原则
- 1、能不给数据库做的事情不要给数据库,数据库只做数据容器。
- 2、对于数据库的变更必须有记录,可以回滚。
六、MySQL简介
- 创始人:Monty Widenius
MySQL是一个小型关系数据库管理系统,开发者为瑞典MySQL AB公司。在2008年1月16号被sun公司10亿美金收购。2009年,SUN又被Oracle以74亿美金收购。
目前MySQL被广泛地应用在Internet上的中小型网站中。由于体积小、速度快、总体拥有成本低,尤其是开放源代码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。
1、MySQL的特性
- 使用C和C++编写,并使用了多种编译器进行测试,保证源代码的可移植性。
- 支持AIX、BSDi、FreeBSD、HP-UX、Linux、Mac OS、Novell Netware、NetBSD、OpenBSD、OS/2 Wrap、Solaris、SunOS、Windows等多种操作系统。
- 为多种编程语言提供了API。这些编程语言包括C、C++、C#、Delphi、Eiffel、Java、Perl、PHP、Python、Ruby和Tcl等。
- 支持多线程,充分利用CPU资源,支持多用户。
- 优化的SQL查询算法,有效地提高查询速度。
- 既能够作为一个单独的应用程序应用在客户端服务器网络环境中,也能够作为一个库而嵌入到其他的软件中。
- 提供多语言支持,常见的编码如中文的GB 2312、BIG5,日文的Shift_JIS等都可以用作数据表名和数据列名。
- 提供TCP/IP、ODBC和JDBC等多种数据库连接途径。
- 提供用于管理、检查、优化数据库操作的管理工具。
- 可以处理拥有上千万条记录的大型数据库。
2、MySQL获取
版本介绍:
- Alpha版:开发版,公司内部使用
- Beta版:完成开发后,用户体验版
- RC版:生产环境发布之前的一个小版本或称候选版
- GA版:正式发布版本
MySQL官网地址: http://www.mysql.com/
- 从官方网站下载安装包
- 从官方网站下载源代码包
- 从官方网站下载二进制包
- 从发行版本光盘中获取安装包
MySQL 常见版本:
- MySQL Community Server 社区版本,开源免费,但不提供官方技术支持。
- MySQL Enterprise Edition 企业版本,需付费,可以试用 30 天。
- MySQL Cluster 集群版,开源免费。可将几个 MySQL Server 封装成一个 Server。
- MySQL Cluster CGE 高级集群版,需付费
3、MySQL在企业中应用
数据库排名: http://db-engines.com/en/ranking
适用场景:
互联网公司web网站系统、数据仓库系统、日志记录系统、嵌入式系统MySQL典型用户:
google、雅虎、腾讯、北电、思科、YouTube、SecondLife 百度、优酷网、新浪、中国电子科学研究院
数商3.0、一大把、哈票网、短信网关、IP通讯
MySQL在云中获得普遍采用:4、MySQL体系结构
Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的。
- Connectors指的是不同语言中与SQL的交互。
- Management Serveices & Utilities: 系统管理和控制工具。
- Connection Pool:连接池。管理缓冲用户连接,线程处理等需要缓存的需求。
- SQL Interface:SQL接口,接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface。
- Parser: 解析器。SQL命令传递到解析器的时候会被解析器验证和解析。
- Optimizer:查询优化器。SQL语句在查询之前会使用查询优化器对查询进行优化。
- Cache和Buffer: 查询缓存。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
- Engine:存储引擎。存储引擎是MySql中具体的与文件打交道的子系统。
#查看最大连接数 show variables like '%max_connections%';- 1
- 2
# 查询缓存配置情况 show variables like '%query_cache%';- 1
- 2
一条SQL语句执行流程:
连接层 (1)提供连接协议:TCP/IP 、SOCKET (2)提供验证:用户、密码,IP,SOCKET (3)提供专用连接线程:接收用户SQL,返回结果 通过以下语句可以查看到连接线程基本情况 mysql> show processlist; SQL层 (1)接收上层传送的SQL语句 (2)语法验证模块:验证语句语法,是否满足SQL_MODE (3)语义检查:判断SQL语句的类型 DDL :数据定义语言 DCL :数据控制语言 DML :数据操作语言 DQL: 数据查询语言 ... (4)权限检查:用户对库表有没有权限 (5)解析器:对语句执行前,进行预处理,生成解析树(执行计划),说白了就是生成多种执行方案. (6)优化器:根据解析器得出的多种执行计划,进行判断,选择最优的执行计划 代价模型:资源(CPU IO MEM)的耗损评估性能好坏 (7)执行器:根据最优执行计划,执行SQL语句,产生执行结果 执行结果:在磁盘的xxxx位置上 (8)提供查询缓存(默认是没开启的),会使用redis tair替代查询缓存功能 (9)提供日志记录(日志管理章节):binlog,默认是没开启的。 存储引擎层(类似于Linux中的文件系统) 负责根据SQL层执行的结果,从磁盘上拿数据。 将16进制的磁盘数据,交由SQL结构化化成表, 连接层的专用线程返回给用户。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
-
相关阅读:
HEC-RAS水动力模型的一维二维及耦合建模
Docker设置开启远程访问
Python之staticmethod:让你的代码更简洁高效
C++ 中的 Pimpl 惯用法
智慧粮仓粮库解决方案:视频+AI识别技术赋能,守护大国粮仓
操作系统文件管理-----索引分配
卫星影像-航拍影像-数据叠加到AutoCAD
java基于springboot+vue+elementui的校园新闻网站 前后端分离
【SA8295P 源码分析 (三)】125 - MAX96712 解串器 start_stream、stop_stream 寄存器配置 过程详细解析
0014Java程序设计-springboot旅行景点推荐系统
- 原文地址:https://blog.csdn.net/weixin_63172698/article/details/133307052