-
心法利器[102] | 大模型落地应用架构的一种模式
心法利器
本栏目主要和大家一起讨论近期自己学习的心得和体会,与大家一起成长。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。
2022年新一版的文章合集已经发布,累计已经60w字了,获取方式看这里:CS的陋室60w字原创算法经验分享-2022版。(2023在路上了!)
往期回顾
经过几个月的实践和探索,看过也经历过一些成型的项目了,如果是奔着落地去的,我们的目光不能只盯着大模型本身,而应该放眼甚至是需要投入精力去建设很多我们别的工作上,有关的观点和讨论我其实在之前的文章里面都有聊过,我把链接放出来供大家参考:
而本文,着重讲的是,我的理解下现实成型的项目中大模型的有关地位,以及这样放的一些具体原因和逻辑。
事先叠个甲,都是个人理解吧,这里可能也有一些技术理念的问题,没有绝对的对错只是选择和权衡,有新的想法可以交流~
大模型系统的架构
首先摆出来的,是整个分层的逻辑架构:
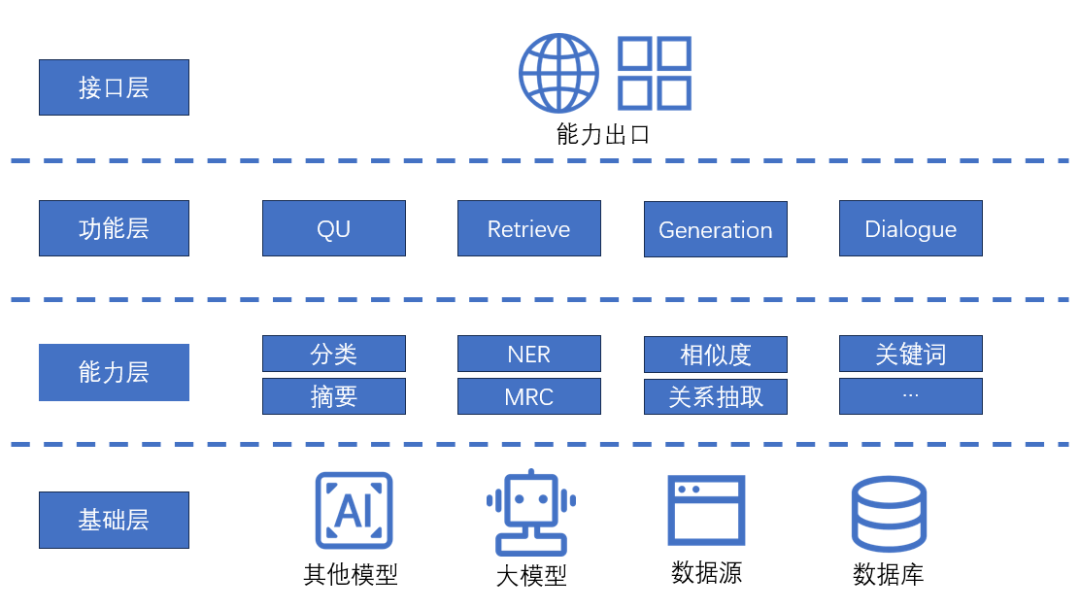
这里,我把各个系统模块主要分为4层:
基础层:基础的、底层的能力,是所有算法能力或者功能的基础,所谓“巧妇难为无米之炊”,这些基础能力就是“米”,没有这些基础,上层的各种产品和功能无从谈起。
能力层:针对的是多种NLP能力(当然这里是只针对NLP项目了),这些能力是抽象的、业务无关的,但却是完成后续各种功能的必备部分。
功能层:产品的核心就是功能,说白了就是需要完成的具体任务,可以是QU(query理解)、检索、生成,甚至是完整的对话系统。
接口层:或者可以叫产品层,其实就是各个功能对外开放的接口了。
这个架构其实非常符合过去几年经常聊及的“中台”或者是“平台”的概念,越往底层,就是更加通用的能力。例如数据,其实是为了很多应用场景服务的,对于算法而言,就是用作特征、训练集、测试集、在线监控等,而算法要搭建起来,最关键的就是模型和数据了,模型在现阶段,更多是指应对多种传统NLP任务的预训练模型,即BERT等,以及现在字字不离的“大模型”,这两种模型基本支撑起现阶段很大部分的算法任务,当然原有的一些类似TextCNN、BiLSTM-CRF等更加经典的模型,在特定场景也会使用,但是更一般的,在算法资源比较充足的环境下,BERT系列方案和预训练模型已经成为了NLP算法能力的中坚力量。
在数据和模型的支撑下,就能够构建最基础的算法能力,对于NLP而言,那就是各种NLP相关的,被拆解的各种任务,一方面是我们熟悉的理解和抽取任务,分类NER等,另一方面就是现在逐渐变得重要的生成任务,例如摘要、阅读理解等,这些任务,可以用数据支撑的词典、规则,也可以靠bert系模型快速构造baseline,也可以用大模型配合prompt快速达成一个无监督的baseline。
有了这些基础的能力和baseline时,很多现实的任务就能够做起来了,从而形成各种各样的功能,小到意图识别、槽位抽取,大到整个检索模块、生成模块等,甚至是一个对话系统,做起来基本就是组装和工程任务了。
而有了功能以后,可以形成接口,接入到具体的产品中,web端、各个移动端都是可以的。
大模型位置的原因
相信大家更关心的,是为什么我会把大模型放在这个位置,即为什么是基础层以及为什么和别的模型、尤其是BERT等模型区分开。
简单的说,其实是因为大模型在现在的环境下需要相对固定而且通用。
相对固定性
相对固定是因为,他的变化,会导致上层任务都要跟随他变化,例如prompt。众所周知,大模型的微调成本高风险大,微调尽管会让大模型支持更多功能或者让原有的任务做得更好,但是现阶段的prompt其实是过拟合大模型的,这意味着大模型修改后,很多prompt可能会失效,可能会带来很严重的后果,尽管我们可以通过监控等因素控制,但风险仍然存在。我们可以迭代更新,但频繁程度需要控制,版本管理也要严格关注。
相对固定性是相比其他模型而言的需要独立存在的重要原因,别的模型其实主要是框架,而且基本上落地交付后,原有的模型结构或者训练pipeline是可以独立迭代而和实际落地解耦的,但是大模型暂时做不了,在成本限制的情况下我们无法部署很多大模型,或者说不能随意按照任务去增加,对资源有限的团队总要精打细算
通用性
通用,我认为是成本是一个关键因素。在bert时代,我们尚且可以支撑每个任务微调一个bert上限处理,但到了大模型时代,在显卡等关键成本价格降到一定程度之前,我们很难支撑这种粗放的设计,因此,我们希望大模型足够通用,让他能做尽可能多的事情。
另一方面,其实我们现在的应用,也是更倾向于把大模型作为底座来做很多事情的。例如通过prompt等轻便的方法来把大模型用起来,而复杂的任务或者是知识点依赖比较重的,则可以通过外挂知识库来解决,毕竟大模型终究是笨重,对更新换代比较快的知识场景,大模型肯定不能跟的很紧,这些用法所要求的,就是大模型具备比较高的通用性和比较强的指令执行能力。
搭建和迭代思路
所谓万丈高楼平地起,如此完整地一个架构,肯定不能一蹴而就,肯定是需要慢慢一步一步地走出来的。
前期,什么都没有的时候,还要面临生存的问题,此时业务实现的优先级应该是很高的,只有业务能带动生存,而在做业务的过程,同时在方案设计的时候也注重复用性和通用性即可,为下一阶段做准备。在业务压力减小但需要拓展的过程,逐步沉淀抽象,形成通用的能力,注意沉淀要尽可能流畅,不能影响具体业务的落地的进度。
后续基础工作都有了后,就会体验到各个具体业务落地时有基础工作的快乐了,基础工作能为业务落地带来很多便利,至少baseline是能更快地跑起来,如果业务需要进一步优化,那在此基础上优化就好了,起点能更高。
大模型,在这里就是基础中的基础,早期项目开始时候就能够快速部署(例如很多开源的模型),通过prompt等基础工作开始产生价值,简单地就是能部署跑起来就好了,等到后续的优化出现瓶颈且有足够人力和机器资源了,再进行迭代优化也不迟(其实实验看来,再具体的业务落地场景,大模型只要本身不那么拉胯,短板问题都在知识库检索、prompt等人方面)。
存在问题
当然,我也深知这个模式是存在缺点的,这不只是大模型,而是这种平台/中台的泛用性模式。
首先,这种平台甚至中台式的结构,在搭建初期是会拖累业务的。资源在一定时期下,是固定的,业务是根本,如果投入过多时间在这种基础工作,势必会影响业务的发展,而对于很多业务而言,可用性优先级更高但是对“好”和“非常好”其实会相对模糊,此时很多基础工作可能功能的优先级会比调优更重要,而对于大模型,“有”和“没有”差距很大,但“好”和“非常好”,体验上的感受就玄学起来了,很多东西其实用prompt做调整以及知识库可能就会带来提升,而非大模型自己就能答更多的题,此时配套建设也就变得重要了不少。
其次,这种平台的推广困难重重。基础工具,要想让用户用,要么是具有足够明显优势,要么就是有老板等角色的强推,否则做出来很可能就是花瓶。像现在的大模型,可以说是百花齐放,用户是有选择权的,他们倾向于选择物美价廉的(至少得占一个吧);另一方面,公司的对内推广也不容易,每个具体的业务可能都有算法,也都有一定能力去建设,这里还有权力和蛋糕的竞争,毕竟技术上确实是肥差,不那么容易放给平台,有更高层的支持推广或者是开放共建,可能都是不错的方案。
再者,依赖复用场景。诚然我们把一个东西做成可复用的工具很强,但要面临的严峻问题是,我们是否需要复用这个东西,更严谨的,复用的方式是什么样的。如果我们做的这个事是一次性的,做完不用再做了,那我们何须花精力把他做成通用。避免这个问题出现则需要有一定的前瞻性,了解未来还会有什么需求,能不能和现在做的事一起抽象出来,在做完最近的事后进行总结沉淀,就是一个不错的方案。
小结
一连几篇,其实我都在讨论大模型应该怎么做系统设计,主要是我想在这个目前好像有些浮躁的环境中先跳出来,换个角度来看——如何能把大模型用好,之前面试和有个前辈聊,他提出的一个观点我很同意,新事物的出现是需要和人做磨合的,大模型就是。我的思考是,大模型需要调教,现在也有很多人投身于此,但不只有调教这一种手段可以磨合,还可以通过改变人的使用方式,通过围绕他搭建出适合他发挥的环境来实现,我最近的几篇和大模型有关的文章就是这个思路。
考虑必要性,从而划定使用边界:心法利器[97] | 判断问题是否真的需要大模型来解决
发挥作用的条件:心法利器[98] | 除了训练,大模型还有很多重要工作
原有体系的融入:心法利器[101] | 从大模型到大模型系统
定位、实施和迭代:这篇
希望对大家有所启发,也希望能和大家进一步交流。

-
相关阅读:
GRFB-UNet:一种新的多尺度注意力网络,用于铺路分割
UE4 3DUI显示与交互案例
Linux less 命令使用介绍
io模型初探
Unity使用Visual Studio Code 调试
TrOCR模型微调【基于transformer的光学字符识别】
android.support.multidex.MultiDexApplication:DexPathList
Mysql之多表查询上篇
关于element-ui的样式覆盖问题
centos8 执行yum install ntpdate命令,报错未找到匹配的参数: ntpdate
- 原文地址:https://blog.csdn.net/baidu_25854831/article/details/133257113