-
全链路自研:腾讯混元大模型释放企业全新可能性

1 通用大语言模型浪潮
生成式模型和判别式模型是两种截然不同的人工智能模型。人工智能生成内容(AI Generated Content, AIGC)相比判别式模型的独特优势,使之可以应对更多的任务,例如推动内容开发、视觉艺术创作、数字孪生、自动编程,甚至为科学研究提供AI视角、Al直觉…

通用大语言模型(Large Language Model, LLM)就是AIGC技术中的核心模型之一。从2018年
GPT约1.2亿的参数量,到2019年GPT2的15亿参数,再到2022年InstructGPT超1750亿的规模,在信息时代的浪潮中,大语言模型正以惊人的速度和无限的创造力引领着人工智能的新纪元。大语言模型不仅能够理解和分析人类语言,还能够生成高质量、富有创意的文本。从写作助手到内容创作,从自动化客服到医疗诊断,它们正在推动各行各业的创新。 这些模型不断通过海量数据进行自我学习,不断提升自己的表现。它们能够从多个领域的知识中吸取灵感,生成创新性的想法和解决方案,对人工智能研究范式和应用模式都产生深远的影响
2 腾讯混元大模型:全链路自研
据腾讯集团副总裁蒋杰介绍,腾讯混元大模型从第一个 token 开始从零训练,掌握了从模型算法到机器学习框架,再到AI基础设施的全链路自研技术。因此全链路自研是腾讯混元大模型的首要特点。
得益于全链路自研技术,腾讯混元大模型能够理解上下文的含义,并且有长文记忆能力,可以流畅地进行专业领域的多轮对话。除此之外,它还能进行文学创作、文本摘要、角色扮演等内容创作,做到充分理解用户意图,并高效、准确地给出有时效性的答复。
2.1 知识增强:实时更新、多源整合
腾讯混元就像一个超级学霸,通过学习大量的数据和文本,具备广泛的知识覆盖能力。它可以从多个来源汲取知识,包括互联网上的文章、书籍、论文等各种文本资源,使得它能够回答各种事实性问题,并提供准确的和全面的信息
它是真正的全才,可以综合各种观点、角度和知识来源,为用户提供更全面、多样化的答案。通过整合不同领域、不同来源的知识,腾讯混元大模型能够提供更准确、更具有洞察力的回答和解决方案,就像是把各种拼图拼起来,得到一个完整的图片。同时,多源整合也有助于消除信息偏差,并提供客观、准确的回答
2.2 多轮对话:语境理解、个性交互
GPT-3作为千亿级别参数规模的模型,已经具备很强的知识能力。但是,其基于概率统计的文本生成机制,容易产生不真实(Untruthful)、无用(Useless)甚至有害(Toxic/Harmful)的输出,这个问题单靠增加大语言模型的规模无法解决。针对大模型容易“胡言乱语”的问题,腾讯优化了预训练算法及策略,让腾讯混元大模型的幻觉相比主流开源大模型降低了30%至50%。腾讯混元识别陷阱问题的关键因素之一是人类反馈强化学习(RLHF),除了RLHF外,腾讯混元大模型还通过位置编码优化,提高了超长文的处理效果和性能
2.3 逻辑推理:信息综合、长推理链
腾讯混元是个推理高手,擅长建立推理链条,将前提、论据和结论相连接,进行逻辑推理的层层推导。它能够根据已有的信息和规则,通过逻辑关系的推断来得出新的结论或判断。在逻辑推断的过程中,它能够识别和纠正一些常见的逻辑错误和谬误,追踪论证过程中的局限性和不一致性,对可能存在的矛盾进行检测,并提供合理的修正建议。
用“超级大脑”形容腾讯混元在逻辑推理方面的能力再恰当不过了。它掌握了多种推理模式,例如演绎推理、归纳推理、类比推理等,因此可以根据问题的特点和上下文选择合适的推理模式,并应用相应的规则和方法进行推理,解析复杂的文章结构,分析不同观点之间的逻辑关系等任务对它来说简直小菜一碟!
2.4 内容创作:情感表达、灵感启发
腾讯混元具备情感表达和文笔调整的能力,能够根据给定的情感要求,生成相应的情感色彩的文本。如果你想要写一封浪漫的情书,它可以帮你用甜蜜动人的文字打动对方的心。同时,它也可以根据不同的写作风格和语言调调整文本的表达方式,使写作更加生动、有趣或正式、专业。
腾讯混元可以借助其庞大的知识库,生成与特定主题相关的文本,为创意和灵感的产生提供启发。它能够提供新颖、独特的观点和想法,帮助创作者克服创作难题,拓展思维。而且,腾讯混元大模型还灵活多样,它可以生成不同角度、不同风格的文本,适应不同需求。无论你是要写一篇幽默搞笑的短文,还是要写一份专业严肃的报告,大语言模型都能根据你的要求进行调整,让你的作品更具个性和魅力
2.5 终身学习:实践中来、实践中去
同时,腾讯混元大模型是一个“从实践中来,到实践中去”的实用级大模型。当前,腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ 浏览器等超过 50 个腾讯业务和产品,已经接入腾讯混元大模型测试,并取得初步效果。腾讯混元大模型将终身学习,继续不断迭代,以追求更卓越的性能
3 API调用与小程序体验
3.1 API调用
首先需要按照以下步骤获取用户信息:
接着,我们构造这样一个对象
import time import urllib import uuid import json import requests import sseclient import hmac import hashlib import base64 _SIGN_HOST = "hunyuan.cloud.tencent.com" _SIGN_PATH = "hyllm/v1/chat/completions" _URL = "https://hunyuan.cloud.tencent.com/hyllm/v1/chat/completions" class TencentHyChat: def __init__(self, appid, secretid, secretkey, enable_stream): self.appid = appid self.secretid = secretid self.secretkey = secretkey self.enable_stream = enable_stream def run(self, content): request = self.__get_parm(content) signature = self.__gen_signature(self.__gen_sign_params(request)) # print(signature) headers = { "Content-Type": "application/json", "Authorization": str(signature) } print('Input:\n{} | {} | {}'.format(_URL, headers, request)) URL = _URL resp = requests.post(URL, headers=headers, json=request, stream=True) print('Output:') if self.enable_stream == 1: client = sseclient.SSEClient(resp) for event in client.events(): if event.data != '': data_js = json.loads(event.data) try: if data_js['choices'][0]['finish_reason'] == 'stop': print("\n") print(event.data) break print(data_js['choices'][0]['delta']['content'], end='', flush=True) except Exception as e: print(e) print(data_js) else: print(resp.json()) def __get_parm(self, content): timestamp = int(time.time()) + 10000 json_data = { "app_id": self.appid, "secret_id": self.secretid, "query_id": "test_query_id_" + str(uuid.uuid4()), "messages": [ # 第一条role应为user {"role": "user", "content": content} ], "temperature": 0.0, "top_p": 0.8, "stream": self.enable_stream, "timestamp": timestamp, "expired": timestamp + 24 * 60 * 60 } return json_data def __gen_signature(self, param): sort_dict = sorted(param.keys()) sign_str = _SIGN_HOST + "/" + _SIGN_PATH + "?" for key in sort_dict: sign_str = sign_str + key + "=" + str(param[key]) + '&' sign_str = sign_str[:-1] print(sign_str) hmacstr = hmac.new(self.secretkey.encode('utf-8'), sign_str.encode('utf-8'), hashlib.sha1).digest() s = base64.b64encode(hmacstr) s = s.decode('utf-8') return s def __gen_sign_params(self, data): params = dict() params['app_id'] = data["app_id"] params['secret_id'] = data['secret_id'] params['query_id'] = data['query_id'] # float类型签名使用%g方式,浮点数字(根据值的大小采用%e或%f) params['temperature'] = '%g' % data['temperature'] params['top_p'] = '%g' % data['top_p'] params['stream'] = data["stream"] messagestr = "" # 数组按照json结构拼接字符串 for message in data["messages"]: content = message["content"] messagestr += '{"role":"' + message["role"] + '","content":"' + content + '"},' messagestr = messagestr.strip(",") print(messagestr) params['messages'] = r"[{}]".format(messagestr) params['timestamp'] = str(data["timestamp"]) params['expired'] = str(data["expired"]) return params- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
通过HTTPS协议,以POST方式对接口
https://hunyuan.cloud.tencent.com/hyllm/v1/chat/completions发起请求,其中我们的APPId、SecretId等参数会按字典序排序,并拼接为签名原文,在对该原文使用SecretKey进行HmacSha1加密和base64编码,最终得到的签名值作为header传入,进行接口鉴权,鉴权通过后,API将返回信息我们可以尝试运行一下和腾讯混元大模型的对话
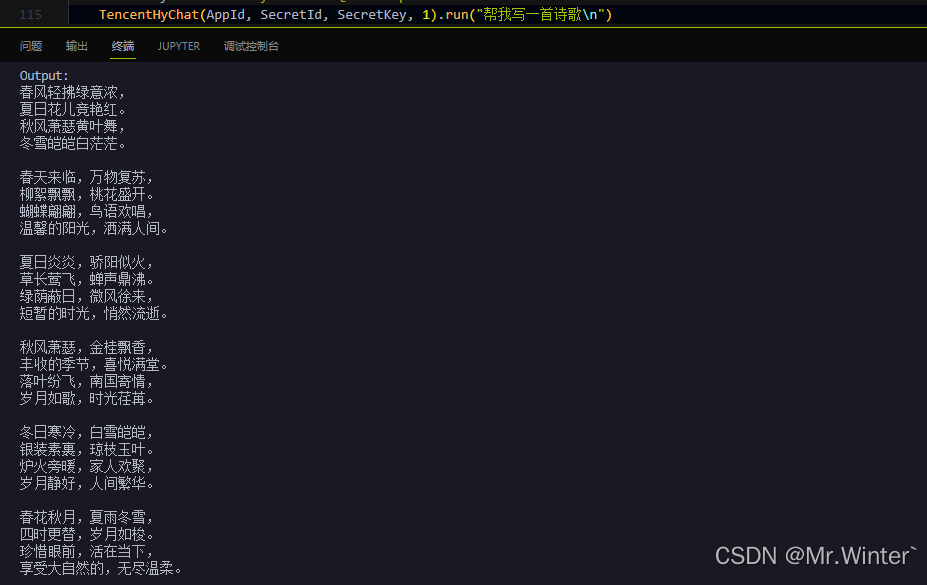
if __name__ == "__main__": # 将AppId、SecretId、SecretKey替换为自己的即可 AppId = 1319778391 SecretId = "AKIDX1WM1Uo1GRYaRcdQOFvPgnhSyGLI6i8P" SecretKey = "oNmz39D9yoWzRo7IVXQBtXCi2xxxxxxx" TencentHyChat(AppId, SecretId, SecretKey, 1).run("帮我写一首诗歌\n")- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下,这是一首以春夏秋冬为主题的诗歌,描绘了自然界万物生长的美妙场景。整体上,诗歌的用词优美,展现出不同季节的特色和变化。每个季节都有独特的气息和景色,使读者可以感受到自然四季的魅力。然而,由于AI生成的诗歌缺乏情感和灵魂上的体验,因此诗歌的意境和深度相对较浅。在一些地方,诗歌的表述可能显得过于平淡或常见。因此在创造力和真实感方面仍有提升的空间。
3.2 小程序交互
搜索
腾讯混元助手小程序
进入小程序后即可体验腾讯混元大模型,比API调用更直接。这里我们测试两个案例:
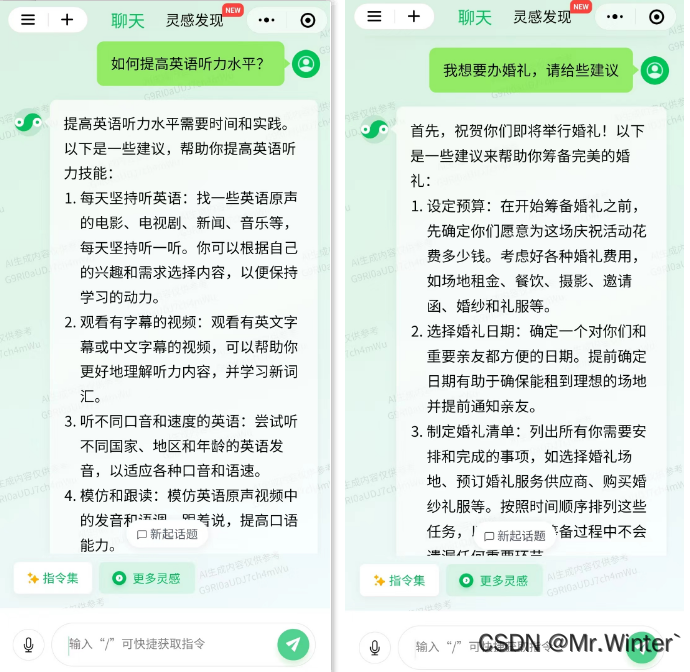
如何提高英语听力水平以及我想要办婚礼,请给些建议。从输出来看,腾讯混元大模型具备良好的语法和逻辑结构,给出的建议能够综合各个方面的需求,具有可行性和实用性,比如针对举办婚礼这种复杂任务来说,大模型可以帮助主人公更好地组织和安排工作,从宏观上确保不会遗漏重要细节。人性化的建议应该能够理解和关注人们的情感需求,并以温暖、鼓励或安慰的方式表达。这种对话应该能够传递喜悦、爱心和支持的情感色彩,应该采用友好、亲切和易于理解的语言风格,与用户建立互动,并提供积极的回应和支持,以建立信任和亲密感。令我惊讶的是,腾讯混元大模型很注重情感和情感表达,更有技术温度,例如会献上婚礼祝福、会鼓励我们好好学习英语等等。
4 释放企业全新可能性
在可预见的未来,人工智能技术的应用将会进一步扩展到更多领域。对于非人工智能领域的应用行业而言,往往需要寻求专业团队或合作伙伴的支持,可以想象,这个过程耗费人力、物力、精力。因此,如何提供一个方便快捷的完整企业级人工智能解决方案,便于下游行业快速处理柔性商业业务成为一大需求。

目前,国内企业可以借助腾讯云接入腾讯混元大模型,并根据自身需求进行个性化调整。举例而言,我们可以思考腾讯混元大模型在以下场景的可能性
4.1 文档场景
腾讯混元可以用来自动摘要和提取文档的关键信息。当你需要阅读和理解大量文档时,模型可以帮助你快速地概括每篇文档的主要内容和要点,省去了繁琐的阅读过程。这个功能非常适用于处理大量文献资料、新闻报道或市场调研数据。借助腾讯混元的强大知识库,当你遇到困惑或需要进一步了解某个主题时,只需向模型提问,它将给你详细的参考信息。同时,腾讯混元大模型就像一个协作伙伴,可以提供文档创作、文本润色、文本校阅、表格公式及图表生成等能力,为我们带来了高效、方便和准确的文档处理体验
4.2 会议场景
腾讯混元可以帮助会议组织者进行会议日程的规划和安排,想象一下,通过向模型描述会议的目标、议程和参与人员,就可以获取诸如议题顺序等建议和优化方案。在会议进行中,腾讯混元大模型可提供会中问答、会议待办项整理等能力,并自动生成会议纪要和会议记录。在会议结束后,会议总结也可以快速生成,简化会议操作并提高会议效率。更进一步延伸,腾讯混元还可以用作会议演示和演讲的辅助工具,根据演讲者的要求生成相应的演讲稿或幻灯片,甚至可以组织思路、提供相关信息和合适的表达方式,提升演讲的质量和效果
4.3 营销场景
个性化推荐是营销中的一个难点问题,腾讯混元能够生成具有多样性和新颖性的文案和图片描述,提供创意和不同的观点。这为广告、创意设计等领域提供了更多可能性。此外,腾讯混元支持自动生成文案和描述,减少了人工撰写和创作的工作量。这不仅提高了效率,还可以应对大规模生成需求或需要快速更新的场景。在营销领域,回答客户的常见问题并提供解决方案是一个基本需求,而这是腾讯混元大模型的天然优势,它可以理解客户的查询,并根据已有知识库和经验提供准确的反馈。无论是在线聊天机器人、自助服务平台还是电话客服系统,都能提供及时、一致和个性化的服务,帮助客户解决问题,增强客户满意度
5 总结
首先,腾讯混元大语言模型具有基本的语言处理能力,能够理解并回应用户的各种问题和指令,无论是简单的日常对话还是复杂的知识查询,都能给出流畅的回答;其次,腾讯混元在提供信息方面表现非常优秀,在内容生成、辅助编码等方面可以节省用户的时间和精力,而且回答通常比较自然,不会像一些其他语言模型那样过于生硬或机械,这增加了用户体验的舒适度。
总得来说,腾讯混元大模型给了我非常友好的体验感,相信在未来,腾讯会用混元技术打造更多的智能方案,惠及更多的人
- 插播一条重要消息:首批通过备案!腾讯混元大模型将陆续对公众开放
近日,腾讯混元大模型首批通过备案,将正式上线,并陆续面向公众开放。客户可以直接通过API调用,也可以将腾讯混元大模型作为基底模型,在公有云上进行精调,为不同产业场景构建专属应用。
-
相关阅读:
【回归预测-NN预测】基于文化算法优化神经网络实现数据回归预测附matlab代码
解决“你当前无权访问该文件夹”问题的8种方法
SpringBoot入门案例
Java安全之freemaker模版注入
评职称好比竞技体育 越快越好越早越好
Ubuntu搭建Mqtt服务器
移植Nokia5110屏驱动 | 我是如何将51代码转为STM32驱动代码的
2.10-CSS基础--盒子模型(下)
巧用字典树算法,轻松实现日志实时聚类分析
什么时候去检测大数据信用风险比较合适?
- 原文地址:https://blog.csdn.net/FRIGIDWINTER/article/details/132896132


