-
IO流(字节流与字符流) 和 File对象 详解与使用
IO流 和 File对象 理论概念
为什么需要io流呢?
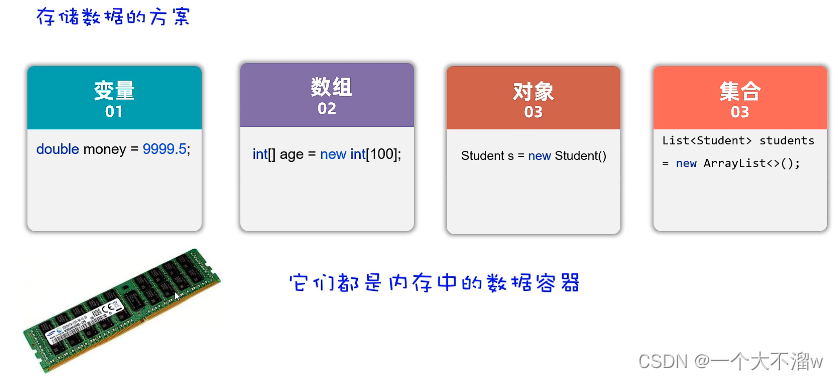
如上图这些基本数据类型和对象以及列表都是内存中的数据,只要断电或者程序停止,这些数据将会永久消失。那么如果我需要长久保存一些数据怎么办?(持久化)
那么就需要使用File对象 和 io流配合了。

file对象是什么?
File对象是Java中用于表示文件或目录的抽象。它提供了一些方法来查询和操作文件系统中的文件和目录。
通过File对象,你可以获取文件或目录的相关信息,如文件名、路径、大小、修改时间等。你还可以创建新的文件或目录,重命名或删除现有的文件或目录,以及进行文件系统的导航和搜索。
需要注意的是,File对象只是一个路径名的抽象表示,并不一定对应着实际的文件或目录。它可以指向存在的文件或目录,也可以指向还没有创建的文件或目录。

那么如何读写文件里面存储的数据呢?
那就是使用IO流进行读写了,io流可以读写文件中的数据或者是网络中的数据。IO流是什么?
IO流指的是输入/输出流,是计算机程序中用于处理输入和输出的数据流。在程序中,输入流用于读取数据,输出流用于写入数据。IO流常用于文件操作、网络通信等场景。

IO流的分类:IO流主要有两种分类。
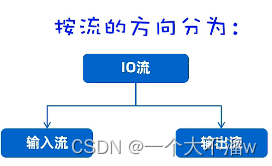
1、按照流的方向分类
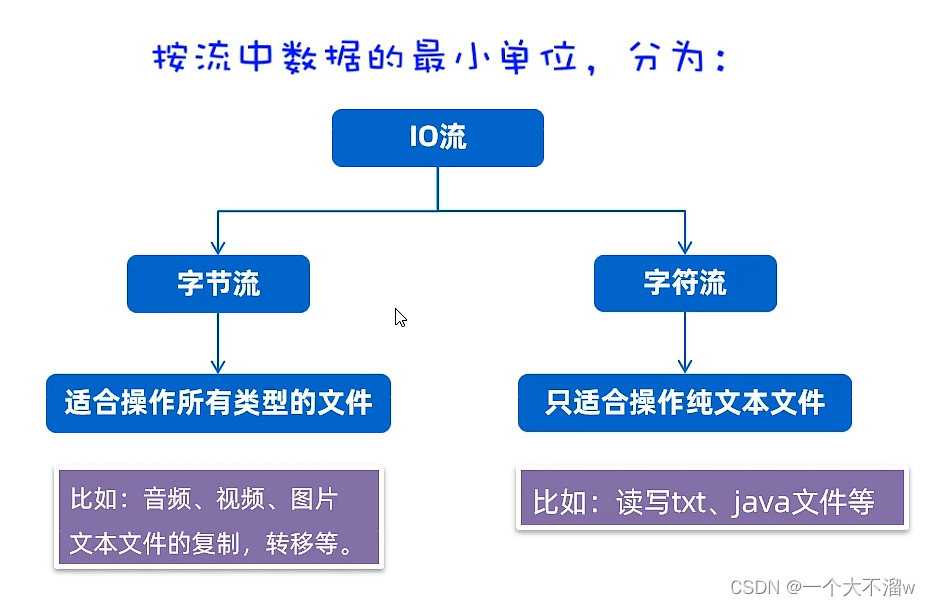
2、按照流中数据的最小单位分类
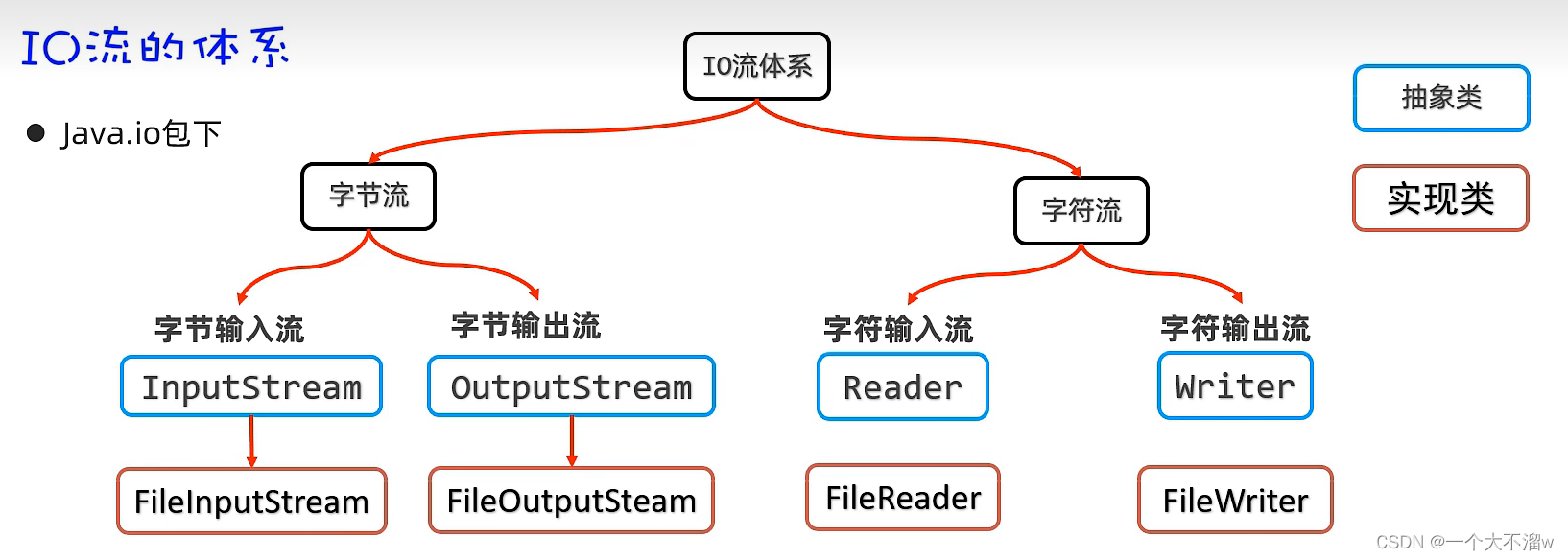
所以大致的io流体系是:
file对象使用
创建file对象
Java的
File类有三个构造器,分别如下:1.
File(String pathname):使用给定的文件路径字符串创建一个File对象。
示例:File file1 = new File("E:/path/to/file.txt");- 1
2.
File(String parent, String child):将父路径和子路径字符串组合起来创建一个File对象。
示例:File file2 = new File("E:/path/to", "file.txt");- 1
3.
File(File parent, String child):将父File对象和子路径字符串组合起来创建一个File对象。
示例:File parentDir = new File("E:/path/to"); File file3 = new File(parentDir, "file.txt");- 1
- 2
其中构造file对象时路径中的
/路径分割符,file对象也提供了一个写法,就是File.separator所以也可以写为:File file1 = new File("E:"+File.separator+"path"+File.separator+"to"+File.separator+"file.txt");- 1

一般实际编码中,使用的都是相对路径,便于代码转移。相对路径是从当前工程下寻找文件。

file对象中一些常用的方法
File类提供了很多常用的方法来操作文件和目录。以下是一些获取文件信息常用的方法和用法:1.
exists():检查文件或目录是否存在,返回值为boolean 。File file = new File("/path/to/file.txt"); boolean exists = file.exists();- 1
- 2
2.
isFile():检查File对象是否表示一个文件,返回值为boolean 。File file = new File("/path/to/file.txt"); boolean isFile = file.isFile();- 1
- 2
3.
isDirectory():检查File对象是否表示一个目录,返回值为boolean。File directory = new File("/path/to/directory"); boolean isDirectory = directory.isDirectory();- 1
- 2
4.
getName():获取文件或目录的名称,包含后缀。File file = new File("/path/to/file.txt"); String name = file.getName();- 1
- 2
5.
length():获取文件的长度(大小)(以字节为单位)。File file = new File("/path/to/file.txt"); long length = file.length();- 1
- 2
6.
getParentFile():获取文件或目录的父File对象。File file = new File("/path/to/file.txt"); File parentDir = file.getParentFile();- 1
- 2
7.
getParent():获取文件或目录的父路径。File file = new File("/path/to/file.txt"); String parent = file.getParent();- 1
- 2
8.
listFiles():获取目录中的所有文件和子目录作为File对象的数组。File directory = new File("/path/to/directory"); File[] files = directory.listFiles();- 1
- 2
9.
getPath():获取到创建文件对象时使用的路径File file = new File("E:\\io\\src\\a.txt"); String path = file.getPath();- 1
- 2
10.
.getAbsolutePath()获取到当前文件的绝对路径。File file = new File("E:\\io\\src\\a.txt"); String absolutePath = file.getAbsolutePath();- 1
- 2
File类提供了一些方法来创建和删除文件。下面是创建和删除文件的方法:-
创建文件:
-
createNewFile():创建一个新的空文件。如果文件已存在,则返回false。File file = new File("/path/to/newFile.txt"); boolean created = file.createNewFile();- 1
- 2
-
mkdir():创建一个新的空目录(只能创建一级)。如果目录已存在或创建失败,则返回false。File dir = new File("/path/to/newDir"); boolean created = dir.mkdir();- 1
- 2
-
mkdirs():创建一个新的目录,包括所有不存在的父目录(可以创建多级)。如果目录已存在或创建失败,则返回false。File dir = new File("/path/to/newDir/subDir"); boolean created = dir.mkdirs();- 1
- 2
-
-
删除文件或空目录:
-
delete():删除文件或空目录。如果删除成功,则返回true;否则,返回false。File file = new File("/path/to/file.txt"); boolean deleted = file.delete();- 1
- 2
File dir = new File("/path/to/directory"); boolean deleted = dir.delete();- 1
- 2
请注意,上述方法只能删除空目录或文件。如果要删除非空目录,需要使用递归删除。
public static void deleteDirectory(File directory) { if (!directory.exists()) { return; } File[] files = directory.listFiles(); if (files != null) { for (File file : files) { if (file.isDirectory()) { deleteDirectory(file); // 递归删除子目录 } else { file.delete(); // 删除文件 } } } directory.delete(); // 删除当前目录 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
调用
deleteDirectory()方法以删除非空目录:File dir = new File("/path/to/directory"); deleteDirectory(dir);- 1
- 2
-
记住,在进行文件和目录操作时,要小心处理异常情况,并确保在操作之前检查文件和目录的存在性。

File类提供了一些方法来遍历文件。下面是遍历文件的方法:
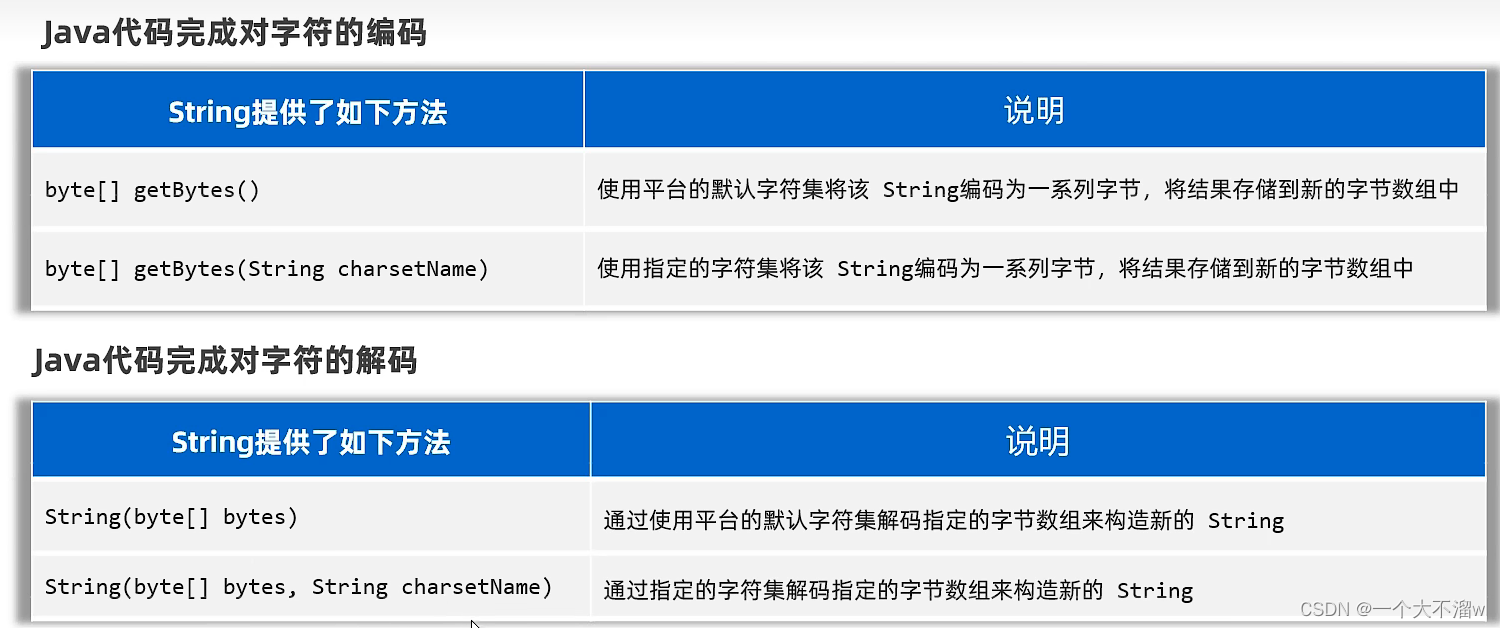
字符集的编码解码操作
主要的字符集编码有
ASCII,UTF-8,GBK等
IO流如何使用
FileInputStream(文件字节输入流)和 FileOutputStream(文件字节输出流)
FileInputStream(文件字节输入流)

使用read()读取,每次返回一个字符,代码示范:
缺点:- 读取性能差
- 中文乱码(中文占两个或者三个字节,一个一个读取把它强行拆分了,所以乱码)
package day0927; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; public class demo3 { public static void main(String[] args) { InputStream in = null; try { in = new FileInputStream("src\\a.txt"); int b; while ((b = in.read()) != -1){ System.out.print((char) b); } } catch (Exception e) { throw new RuntimeException(e); }finally { try { //读取完之后关闭流 if (in!= null) in.close(); } catch (IOException e) { throw new RuntimeException(e); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
使用
read(byte[] buffer)读取,每次读取字节数组的长度,代码示范:
优点:- 性能得到了提升。
缺点:
- 中文还是可能会乱码。
package day0927; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; public class demo3 { public static void main(String[] args) { InputStream in = null; try { in = new FileInputStream("src\\a.txt"); //设置每次读取多少字节,一般是写 1024*n byte[] buffer = new byte[3]; int b; while ((b = in.read( buffer )) != -1){ //注意:读取多少就倒多少 String str = new String(buffer,0,b); System.out.print(str); } } catch (Exception e) { throw new RuntimeException(e); }finally { try { if (in!= null) in.close(); } catch (IOException e) { throw new RuntimeException(e); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
以上两种方式都是读取中文会乱码,可以使用直接读取整个文件字符,则不会乱码。

第一种方法(获取文件大小,定义一个和文件一样大小的字节数组一次性读取):package day0927; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; public class demo3 { public static void main(String[] args) { InputStream in = null; try { //获取文件的file对象 File file = new File("src\\a.txt"); //获取文件的字节长度 long length = file.length(); in = new FileInputStream(file); //字节数组的长度改为文件长度 byte[] buffer = new byte[(int) length]; //一次性读取 in.read(buffer); System.out.println(new String(buffer)); } catch (Exception e) { throw new RuntimeException(e); }finally { try { if (in!= null) in.close(); } catch (IOException e) { throw new RuntimeException(e); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
第二种方法 JDK11新增的特性
readAllBytes():
一顶是JDK11以上才可以使用否则报错。FileInputStream in = new FileInputStream("src\\a.txt"); byte[] buffer = in.readAllBytes(); System.out.println(new String(buffer));- 1
- 2
- 3
FileOutputStream(文件字节输出流)

使用write()输出字符。package day0927; import java.io.FileOutputStream; import java.io.IOException; public class demo4 { public static void main(String[] args) { FileOutputStream out = null; try { //参数1文件的位置,参数2是否是追加,默认false out = new FileOutputStream("src\\b.txt",true); out.write("你好,JAVA".getBytes()); //out.write('97'); 写入字符a } catch (Exception e) { throw new RuntimeException(e); }finally { try { if (out != null) out.close(); } catch (IOException e) { throw new RuntimeException(e); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
FileInputStream和FileOutputStream案列(文件复制)
当学会了文件输出输入流之后,就可以完成文件的拷贝案例了。
使用文件输出输入流是所有的文件都可以进行复制的,下面是代码示范:package day0927; import java.io.*; public class demo5 { public static void main(String[] args) { InputStream in = null; OutputStream out = null; try { in = new FileInputStream("D:\\asdf.jpg"); out = new FileOutputStream("E:\\asdf.jpg"); byte[] buffer = new byte[1024]; int b; while ((b = in.read(buffer))!= -1){ out.write(buffer,0,b); } } catch (Exception e) { throw new RuntimeException(e); }finally { try { if (out != null) out.close(); if (in != null) in.close(); } catch (IOException e) { throw new RuntimeException(e); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
如上代码看起来写得特别的臃肿,因为各种释放资源,所以这里就要使用到 JDK7提出得新特性:
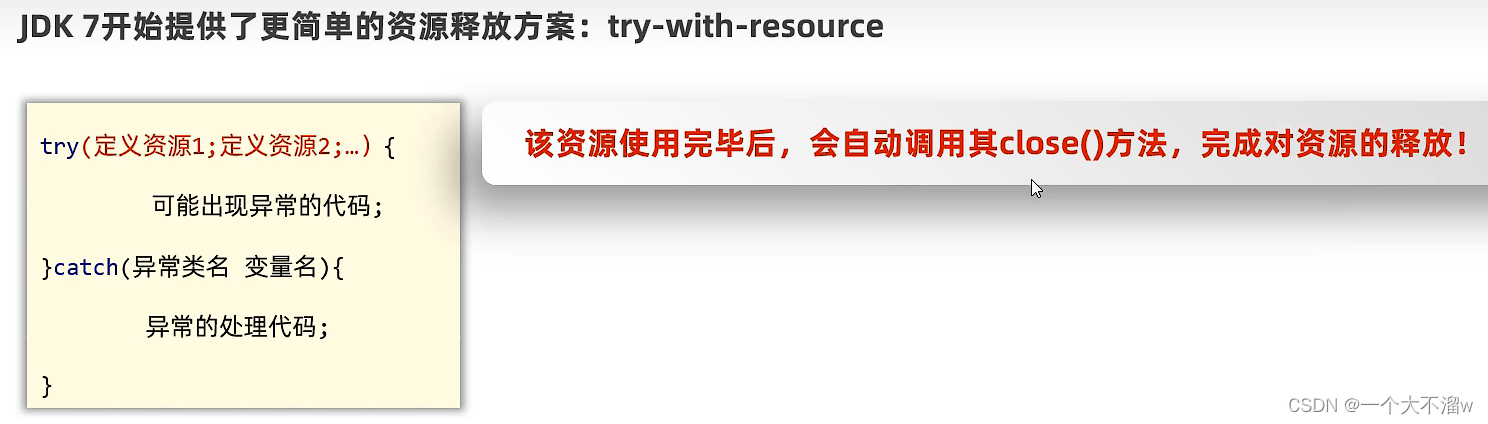
如图在try中写资源,当执行完之后会自动调用其close()方法。示范代码:package day0927; import java.io.*; public class demo5 { public static void main(String[] args) { try ( InputStream in = new FileInputStream("D:\\asdf.jpg"); OutputStream out = new FileOutputStream("E:\\asdf.jpg"); ){ byte[] buffer = new byte[1024]; int b; while ((b = in.read(buffer))!= -1){ out.write(buffer,0,b); } } catch (Exception e) { throw new RuntimeException(e); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
FileReader(字符输入流)和 FileWriter(文件字节输出流)
FileReader(字符输入流)

以下代码示范就是字符流读取文件,分别有一次读取一个字符和读取多个字符。package day0927; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class demo6 { public static void main(String[] args) { try ( FileReader reader = new FileReader("src\\a.txt"); ){ //一次读一个字符,性能消耗较高 // int d; // while ((d = reader.read())!=-1){ // System.out.print((char)d); // } //一次读多个字符,性能消耗低 char[] buffer = new char[3]; int d; while ((d = reader.read(buffer))!=-1){ //读多少就倒多少 System.out.print(new String(buffer,0,d)); } } catch (Exception e) { throw new RuntimeException(e); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
FileWriter(文件字节输出流)
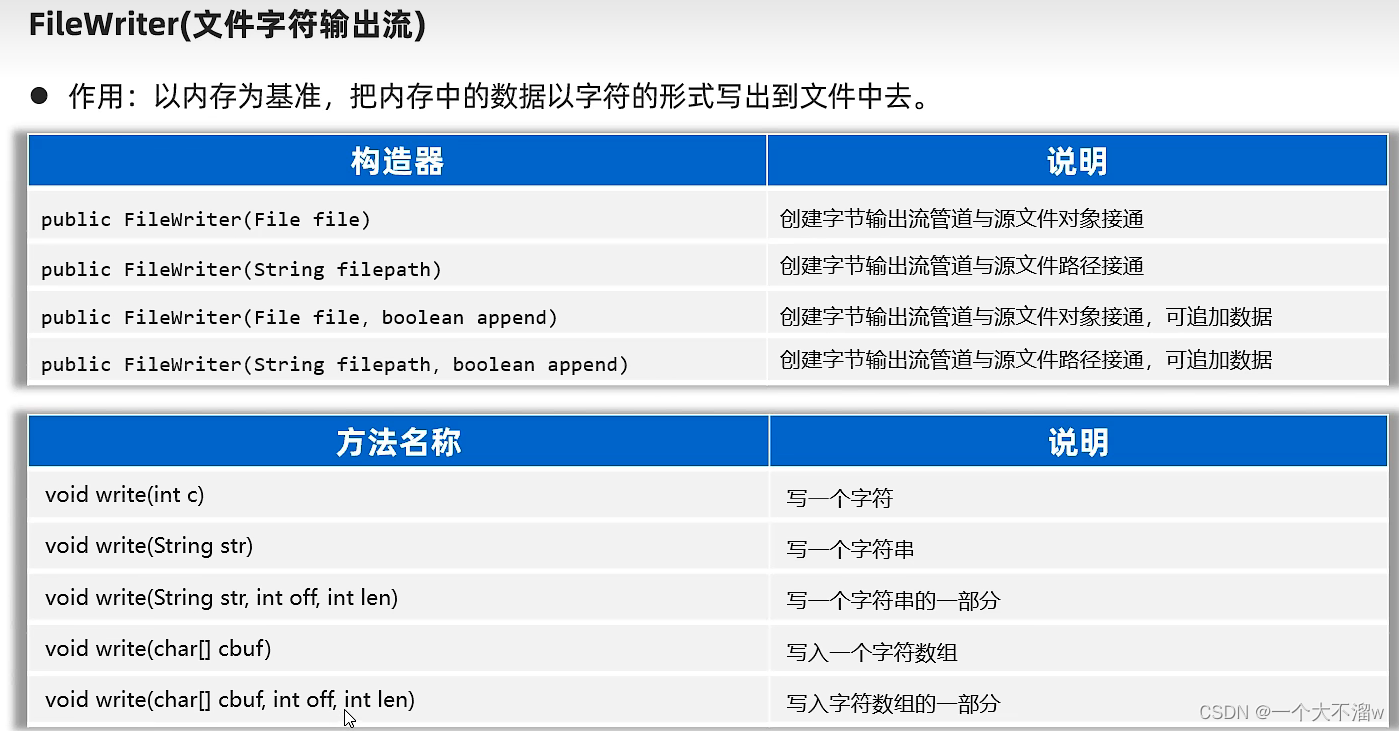
下面是FileWriter文件字符输出流的代码演示:package day0927; import java.io.FileWriter; import java.io.IOException; public class demo7 { public static void main(String[] args) { try ( //覆盖的写法 // FileWriter writer = new FileWriter("src\\c.txt"); //追加的写法 FileWriter fileWriter = new FileWriter("src\\c.txt",true); ){ //写一个字符 fileWriter.write(97); fileWriter.write("流"); fileWriter.write('a'); //写一个字符串 fileWriter.write("我爱你中国asdf"); //写一个字符串得一部分 fileWriter.write("我爱你中国asdf",0,5); //写一个字符数组 char[] chars = {98,'s','牛','马'}; fileWriter.write(chars); //写一个字符数组得一部分出去 fileWriter.write(chars,1,2); } catch (IOException e) { throw new RuntimeException(e); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
字符输入输出流复制文本案例:
package day0927; import java.io.FileReader; import java.io.FileWriter; public class demo8 { public static void main(String[] args) { try ( FileReader fileReader = new FileReader("src\\a.txt"); FileWriter fileWriter = new FileWriter("src\\d.txt"); ){ char[] buffer = new char[3]; int b; while ((b = fileReader.read(buffer)) != -1){ fileWriter.write(buffer,0,b); } } catch (Exception e) { throw new RuntimeException(e); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
重点注意:

因为使用字符流输出数据是先建立了一个缓冲区,把所有要写的字符先存到了这,而不是直接存到目标文件,所以需要flush()刷新或者close()关闭流进行保存,如果不使用flush()刷新或者不使用close()关闭流那么就不会保存,但是当缓冲区数据堆满时,它会自动进行一次flush()刷新也就是自动保存一次。小结:

-
相关阅读:
人脸自收集数据集辅助制作工具——多人在线协同标注系统
蓝桥杯 题库 简单 每日十题 day4
Element UI +Vue页面生成二维码的方法
软件著作权的好处有哪些?软著含金量高吗?
Spring Boot + BPMN流程管理引擎实践
pytorch编程知识(2)
一个Python爬虫案例,带你掌握xpath数据解析方法!
nginx+flume 数据采集
OpenTiny 的这些特色组件,很实用,但你应该没见过
RAID10如何创建?RAID10做法详细说明
- 原文地址:https://blog.csdn.net/weixin_72979483/article/details/133343801
