-
逆向入门及实战
一、逆向工程介绍
1.1 什么是逆向工程
提到逆向工程可能大多数人第一印象就是非道德层面的软件破解,其实不然,逆向工程又称为逆向技术,是一种产品设计技术再现过程,即对一项目产品进行逆向分析及研究,从而演绎并得出该产品的处理流程、组织结构、功能特性及技术规格等设计要素,以制作出功能相近,但又不完全一样的产品。
逆向技术不仅仅是用在商业方面,在军事领域尤为重要,例如越南战争期间我国通过获取4万多块美军战机碎片逆向获得300多项新技术。从这个案例可以看出来,逆向技术不仅仅包含软件逆向,也包含硬件逆向,材料逆向等等。所以下面就软件逆向来介绍其相关知识。
1.2 软件逆向实际应用
软件逆向技术作用有很多,大多数人应该都使用过逆向出来的盗版软件。实际上这种做法在道德和版权层面来说肯定不被作者所接受,而且会带来较大危害性,会影响到软件开发者的利益,不利于软件市场的健康发展等等。从使用者角度来说其实也有不利影响,例如一些破解软件里可能夹带有病毒或者安全漏洞,被不法人士利用则会造成使用者的数据泄漏或者经济损失等。
对于这种非道德层面的逆向产品我们要知道其危害,但是也要知道逆向技术的正向应用,下面介绍几点:
恶意软件的作者几乎不会提供源代码,除非是基于脚本的病毒。由于缺乏源代码,要准确地了解恶意软件的运行机制,动态分析和静态分析是分析恶意软件的两种主要技术手段。动态分析是指在严格控制的环境(沙盒)中执行恶意软件并使用系统检测实用工具记录其所有行为。相反,静态分则试图通过浏览程序代码来理解程序的行为。此时,要查看的就是对恶意软件进行逆向之后得到的代码清单,通常是汇编代码。在了解到恶意软件的行为之后就可以制定对应有效的防御措施。

安全审核过程划先简单分成3个步骤:发现漏洞、分析漏洞、开发破解程序。无论是否拥有源代码,都可以采用这些步骤来进行安全审核。在没有源代码只有二进制文件情况下,就只能选择逆向方式进行分析。这个过程的第一个步骤,是发现程序中潜在的可供利用的条件。一旦发现漏洞,通常需要对其进行深入分析,以确定该漏洞是否可被利用,如果可利用,可在什么情况下利用。以帮助研究人员了解漏洞的触发条件、影响范围和控制流程等,从而制定更有效的修复措施。

由于编译器(或汇编器)的用途是生成机器语言,不同的编译器对源码翻译出的机器语言可能有差异,这些差异可能不影响功能,但是对性能可能有着巨大差异。所以在这方面可以使用逆向技术来查看编译器翻译出来的机器语言是否符合预期,从而使编译器开发人员能够对编译器进行优化,以达到代码优化验证目的。因此优秀的反汇编工具通常需要验证编译器是否符合设计规范。分析人员还可以从中寻找优化编译器输出的机会,从安全角度来看,还可查知编译器本身是否容易被攻破,以至于可以在生成的代码中插人后门等等。

逆向工程可能会被误认为是对知识产权的严重侵害,但是在实际应用上,反而可能会保护知识产权所有者。例如在软件或者硬件领域,如果怀疑某公司侵犯知识产权,可以用逆向技术逆向对方的产品寻找其侵权证据。

需要注意的是,逆向技术的应用需要遵守相关法律法规和知识产权法律法规的规定,不能用于侵犯他人的合法权益。
二、 软件逆向基础知识
任何领域的逆向都不是一项简单的工作,软件逆向技术的应用也需要具备一定的专业知识和技能,需要经过专门的学习和实践才能掌握。这里列举一些对于入门而言所需要的基本知识:
2.1 计算机体系结构(x86-CPU指令集)
计算机体系结构是指根据属性和功能不同而划分的计算机理论组成部分及计算机基本工作原理、理论的总称。其中计算机理论组成部分并不单与某一个实际硬件相挂钩,如存储部分就包括寄存器、内存、硬盘等。在学习逆向时首选得弄懂什么是CPU,什么是寄存器,什么是内存?(其他如输入设备,输出设备都很重要,这里不做展开介绍)
- CPU即中央处理器,是一块超大规模的集成电路,是计算机的运算核心和控制核心,主要是解释计算机指令以及处理计算机软件中的数据,包括运算器和高速缓冲存储器及实现它们之间联系的数据、控制及状态的总线;
- 寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果。
- 内存是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。
上述提到CPU解释计算机指令的作用,这里的指令一般是由01二进制数据组成,使用助记符一 一对应就形成了汇编指令。汇编指令在不同体系架构有所不同,所以不同计算机体系关系到软件设计体系,例如X86,ARM, MIPS体系架构的寄存器操作,对执行过程操作可能存在一定的差异。例如x86架构采用复杂指令集(CISC)设计,意味着x86处理器具有更多的内建指令和更复杂的硬件,从而能实现更高的计算性。MIPS采用精简指令集(RISC)设计的架构,设计理念强调高吞吐量和高指令并行度。
如下图指令块分别是上述三种不同架构使用的指令集,如果我们对x86指令集比较熟悉,应该能一眼看出哪段是x86。
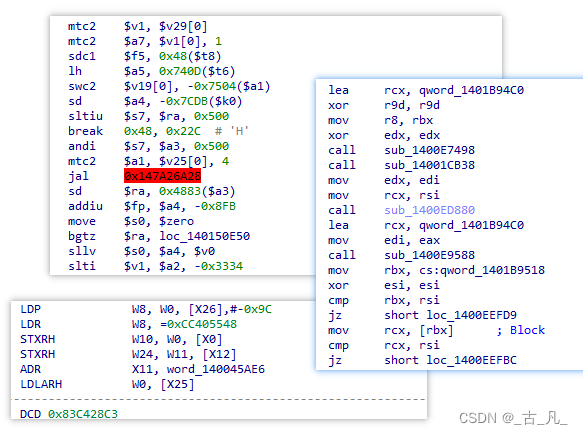
下面介绍这三种架构的几个常见的指令区别:
指令类型 / 架构
x86
ARM
MIPS
赋值,寻址
mov
LDR,MOV
move
算术运算符
add
ADD / ADC
add / addi
跳转
jz / jnz
BRA
j / jri
比较
cmp
CMP
bgtz
函数调用
call
BL
jal
堆栈操作
push, pop
push, pop
sd,sw
x86的几个通用寄存器(部分),如下图:

根据上图得到的信息:
- rax,eax,ax和al是同一个寄存器,只是位长不同,例如eax的值为0x12345678,那么al的值就是最低位一个字节的值,即0x78,其他寄存器类似。
- eax称为累加器,常用于算数运算、布尔操作、逻辑操作、返回函数结果等。
- ebx称为基址寄存器,常用于存档内存地址。
- ecx称为计数寄存器,常用于存放循环语句的循环次数,字符串操作中也常用。
- edx称为数据寄存器。
- 函数入参第1个入参默认存入rdi/edi,其次是rsi/esi,当超出一定数量(正常是6个)会使用栈空间传参。
- rsp/esp是指向栈指针。
- eip/rip是指向程序运行的寄存器。
- rbp/ebp一般指向函数的栈底。
通用寄存器的专门用途不是一成不变的,编译器在编译程序的时候会根据很多因素来决定作用,例如编译器、编译条件、操作系统等做出相应的改变。
另外还有部分标志位:
- CF(Carry Flag):进位标志位,用于表示加法运算是否产生进位。
- PF(Parity Flag):奇偶校验标志位,用于表示数据中1的个数是否为偶数。
- ZF(Zero Flag):零标志位,用于表示运算结果是否为0。
- SF(Sign Flag):符号标志位,用于表示运算结果的符号位。
- IF(Interrupt Flag):中断标志位,用于控制是否允许硬件中断。
- DF(Direction Flag):方向标志位,用于控制字符串操作时是向前还是向后扫描。
- OF(Overflow Flag):溢出标志位,用于表示加法或减法运算是否产生溢出。
举个例子说明标志位怎么用的。
cmp [esi], 0
jnz 0x152686
上述cmp类似于减法指令,只是不保存结果,判断esi所指内存的值是否等于0, 做差之后标志位ZF就会有结果(等于0就是ZF=1),然后jnz根据ZF表示是否为0决定EIP是否跳转到指定位置。
2.2 程序语言(汇编)
软件逆向出来的代码清单大多以汇编语言为主要呈现形式,也有逆向工具可生成C/C++等语言伪代码。所以入门至少对汇编语言有一定的了解,对
-
相关阅读:
JSqlParser 解析 sql
【微信小程序】一文带你了解数据绑定、事件绑定以及事件传参、数据同步
对 Android APK 进行反编译
Django 03
VMware vCenter和ESXi 升级注意事项
面向对象设计原则之里氏代换原则
语音人工智能的简单介绍
设计模式-7--代理模式(Proxy Pattern)
[C#]使用 AltCover 获得代码覆盖率 - E2E Test 和 Unit Test
CentOS8 安装 erlang 和 RabbitMQ
- 原文地址:https://blog.csdn.net/Ang_ie/article/details/133364631