-
【数据结构】深度剖析最优建堆及堆的经典应用 - 堆排列与topk问题
🚩纸上得来终觉浅, 绝知此事要躬行。
🌟主页:June-Frost
🚀专栏:数据结构
🔥该文章分别探讨了向上建堆和向下建堆的复杂度和一些堆的经典应用 - 堆排列与topk问题。
❗️该文章内的思想需要用到实现堆结构的一些思想(如向上调整和向下调整等),可以在另一篇文章《堆的顺序实现》中再次了解一下,其中一些接口有具体的实现💖。
🌍 建堆
建堆的常见方式有两种:向上建堆和向下建堆。
🔭 向下建堆

这些交换其实就是向下调整的过程,所以向下建堆只要通过不断的向下调整就可以实现。int arr[] = { 10,20,25,35,60,36,15 }; int n = sizeof(arr) / sizeof(arr[0]); int i = 0; for (i = (n - 1 - 1) / 2; i >= 0; i--) { AdjustDown(arr, n, i);//向下调整 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
✈️时间复杂度

将每层数据个数 * 向下移动的层数求和,得到 T(h) = 2(h-2)*1 + 2(h-3)*2+…+21 *(h-2) + 20 *(h-1) 。通过错位相减,可以得到T(h) = 2h-1-h。因为是满二叉树,所以假设节点为N,则N = 2h - 1 , h = log2(N+1) ,将h换为N,可以得到向下调整建堆合计调整次数 T(N) = N-log(N+1),所以时间复杂度为: O(N) 。
🔭 向上建堆

同样,这些交换的思想就是向上调整,通过不断调整就可以建堆。int i = 0; for (i = 1; i < n; i++) { AdjustUp(arr, i);//向上调整 }- 1
- 2
- 3
- 4
- 5
✈️时间复杂度

将次数求和,T(h) = 21*1 +222+…+2h-2 * (h-2) + 2h-1 * (h-1)。将h与N换算,得到T(N) = -N+(N-1)(log(N+1)-1)+1 ,总的来说,时间复杂度为 O(N * logN) 。
📙一棵满二叉树的最后一层节点数大概占据总数的50%,向上建堆在最后一层非常吃亏,不仅节点多,调整次数也多,而向下建堆避开了最后一层,时间复杂度也优于向上建堆,所以向下建堆比向上建堆更优。
🌎 堆的经典应用
堆是一种特殊的数据结构,通过大堆和小堆所带来的特性可以使得堆在许多应用中成为非常有效的数据结构。
🔭 堆排序
堆排序是一种基于堆数据结构的排序算法,它利用了堆的性质来实现高效的排序。对于一个数组,虽然可以通过堆结构来帮助排序,但是实现一整个堆的数据结构并不容易,并且在建堆时会有额外空间的浪费。
例如:通过堆数据结构进行排序
int main() { int arr[] = { 10,20,25,35,60,36,5 }; HP heap; HeapInit(&heap); for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) { HeapPush(&heap, arr[i]); } int i = 0; while (!HeapEmpty(&heap)) { arr[i++] = HeapTop(&heap); HeapPop(&heap); } HeapDestroy(&heap); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
基于这样的一些缺点,所以最好可以实现原地排序。对于任意一个数组是可以看作一个完全二叉树,但是不一定是堆,那么第一个步骤就是建堆。
类比堆的插入,可以将第一个数组元素看作堆,从第二个元素开始进行向上调整(前提 - 左右子树依旧是堆),这样就可以建堆。
void HeapSort(int* arr, int n) { //第一步:建堆 int i = 0; for (i = 1; i < n; i++) { AdjustUp(arr, i); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
⚠注意:
- 升序:建大堆。
- 降序:建小堆。
📗分析:如果升序建造小堆
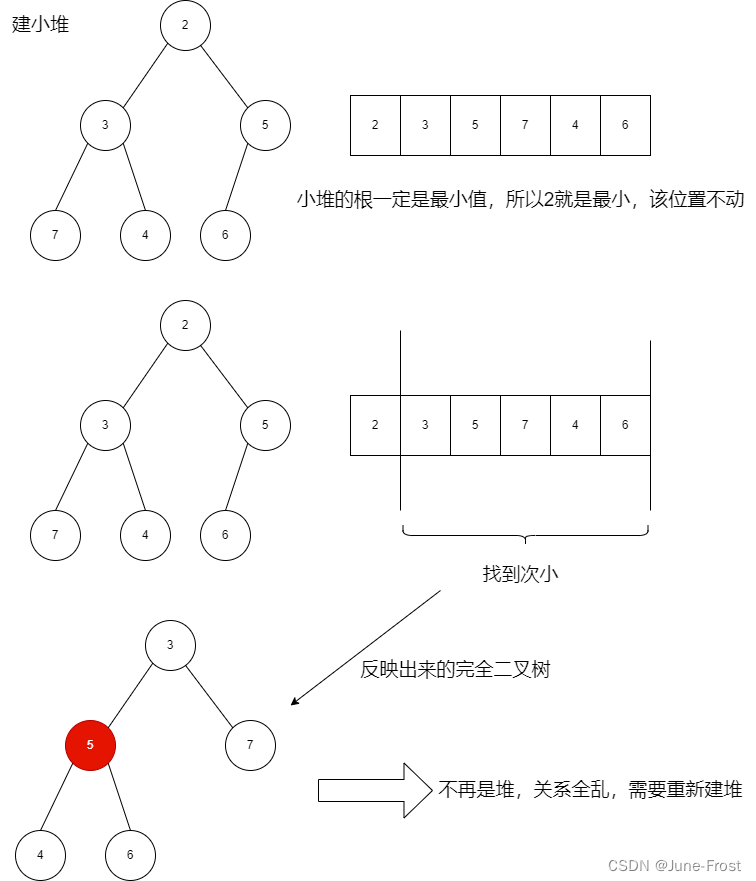
这样的操作代价太大了,为 N*(N*logN),甚至不如直接遍历,丧失了堆的价值。当我们想排升序,建造好大堆后,就可以利用堆删除思想来进行排序。

按照这个逻辑不断交换和调整就可以完成排序,时间代价为 N*logN 。void HeapSort(int* arr, int n) { //第一步:建堆 int i = 0; for (i = 1; i < n; i++) { AdjustUp(arr, i);//向上调整 } //第二部:排序 int end = n - 1; while (end > 0) { Swap(&arr[0], &arr[end]);//交换 AdjustDown(arr, end, arr[0]);//向下调整 end--; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
🔭TOPK问题
TOPK问题是指从大量数据中获取最大(或最小)的K个数据,例如:有大量的数据,这些数据在内存中存储不下,只能以文件形式存储,现需要找出最大的前k个数。
方式:
1.读取文件前k个数据,在内存数组中建立一个小堆。
2.依次读取剩下的数据,如果大于堆顶元素就进行替换,并向下调整。当文件的数据全部读取完成后,堆里的数据就是最大的前k个数。
🗼这里以10000个数据为例:
void PrintTok(const char* filename,int k) { //用前k个数据建造一个小堆 FILE* fout = fopen(filename, "r"); if (fout == NULL) { perror("fopen fail"); exit(-1); } int* minheap = (int*)malloc(sizeof(int) * k); if (minheap == NULL) { perror("malloc fail"); exit(-1); } int i = 0; for (i = 0; i < k; i++) { fscanf(fout, "%d", &minheap[i]); } //向下调整建堆 for (i = (k - 2)/2 ; i >= 0; i--) { AdjustDown(minheap, k, i); } //遍历剩下的数据,大的数替代堆顶元素,然后向下调整 int x = 0; while (fscanf(fout, "%d", &x) != EOF) { //如果大于堆顶元素就替换 if (x > minheap[0]) { minheap[0] = x; AdjustDown(minheap, k, 0); } } for (i = 0; i < k; i++) { printf("%d ", minheap[i]); } printf("\n"); fclose(fout); free(minheap); } //造数据 void CreateNDate() { int n = 10000; srand((unsigned int)time(NULL)); const char* file = "Data.txt"; FILE* fin = fopen(file, "w"); if (fin == NULL) { perror("fopen fail"); exit(-1); } for (int i = 0; i < n; i++) { int x = rand() % 1000000; fprintf(fin, "%d\n", x); } fclose(fin); } int main() { //CreateNDate();//造数据 PrintTok("Data.txt", 10); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
❤️ 结语
文章到这里就结束了,如果对你有帮助,你的点赞将会是我的最大动力,如果大家有什么问题或者不同的见解,欢迎大家的留言~
-
相关阅读:
工业智能化转型升级难?华为云这三招,加速商业变现
【C语言】结构体+位段+枚举+联合(2)
开发一个商城需要多少钱 做一个电商网站大概多少钱
vue中的watch的实际开发笔记
【FAQ】应用内支付服务无法拉起支付页面常见原因分析和解决方法
Excel VBA高级编程-微信群发(支持发送文件)
Day44 动态规划part04
Spring Boot 集成MyBatis-Plus
JDBC中对象的解释与statement对象详解
Redis 内存淘汰策略
- 原文地址:https://blog.csdn.net/m0_75219751/article/details/133001521
