-
Elasticsearch 8.X:这个复杂的检索需求如何实现?
1、企业级真实问题
问题描述如下:
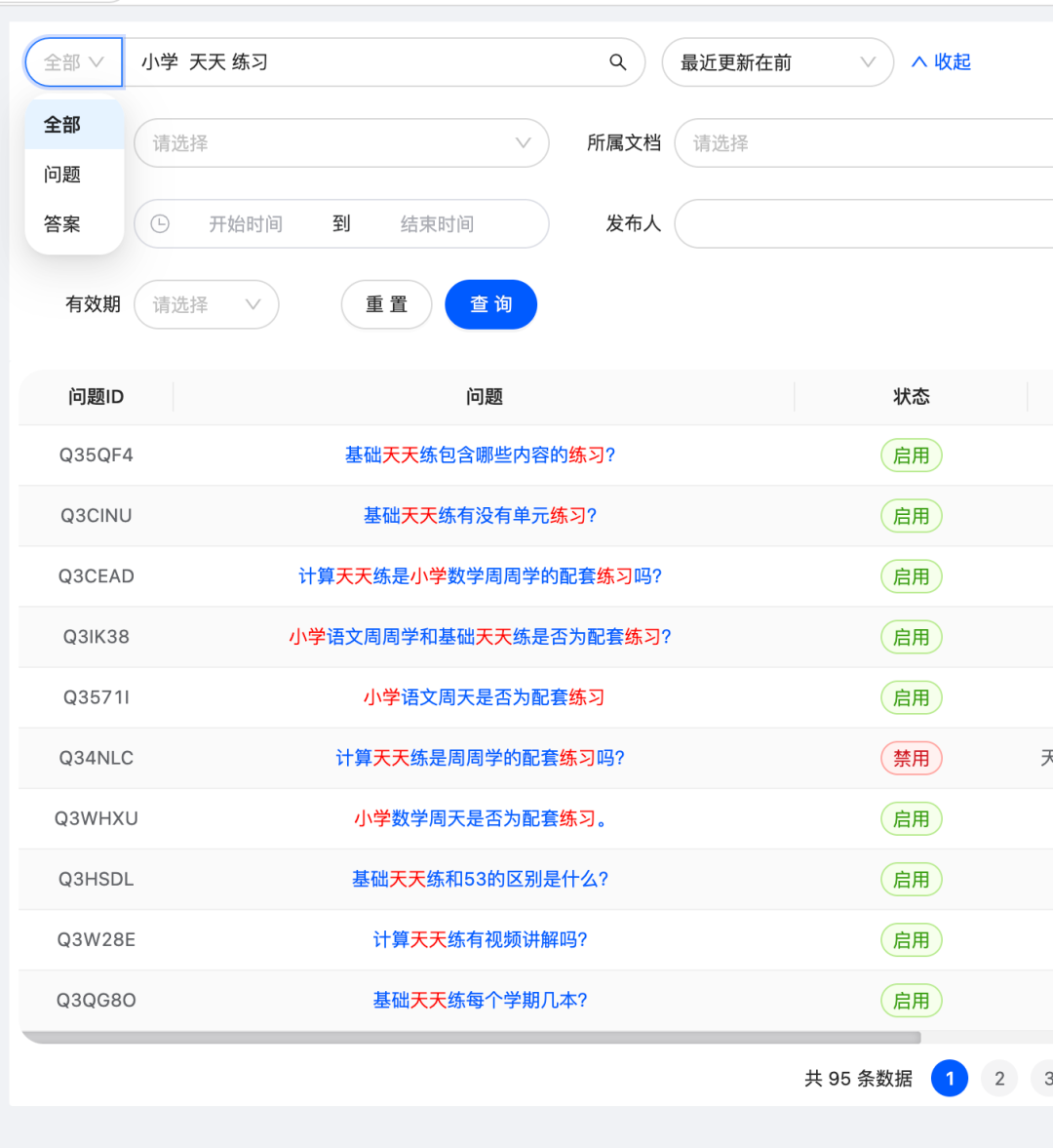
如上图所示,index中有这样四个字段:title content question answer。要查询这四个字段,支持最多输入5个关键词模糊查询,多关键词以空格隔开。
匹配度计算逻辑:
关键词有序排列 ,权重依次降低,即排列在前的关键词权重最高,依此降低;检索顺序和结果顺序一致的排在前面。
title(question)较content(answer)权重高,比如权重高10倍
词频(关键词出现次数)越高,匹配度越高
在匹配度相同的条件下按更新时间倒序排列
就拿上面的截图来看,doc标题:“小学语文周周学和基础天天练是否为配套练习?”这个doc应该排在第一位。
提问球友的 DSL 为:
- {
- "bool": {
- "should": [
- {
- "multi_match": {
- "query": "小学 天天 练习",
- "fields": [title content question answer],
- "type": "best_fields",
- "tie_breaker": 0.3
- }
- },
- {
- "match": {
- "title": {
- "query": "小学 天天 练习",
- "boost": 10
- }
- }
- },
- {
- "match": {
- "question": {
- "query": "小学 天天 练习",
- "boost": 10
- }
- }
- }
- ]
- }
- }
2、需求重新梳理
问题有点长,我们重新梳理一下。
需求 1:检索顺序和结果顺序一致的排在前面。
需求 2:title(question)较content(answer)权重高,比如权重高10倍。
需求 3:词频(关键词出现次数)越高,匹配度越高。
需求 4:时间倒序排序。
已和提问确认,就是上述四个需求。
3、实现讨论
针对需求 2,这个设置权重就可以实现。
针对需求 3,这个 TF-IDF 机制决定的,检索后结果自然满足,也就是评分逻辑就是基于这个实现的(后续升级为BM25模型,原理一致),咱们不用动就可以。
针对需求 4,加个时间排序就可以。
针对需求2、3、4,实现参考如下(字段权重根据实际业务场景自我调整即可):
- POST new_index_2023/_search
- {
- "query": {
- "bool": {
- "should": [
- {
- "multi_match": {
- "query": "小学 天天",
- "fields": [
- "title^10",
- "question^10",
- "content",
- "answer"
- ],
- "type": "best_fields"
- }
- }
- ]
- }
- },
- "sort": [
- {
- "timestamp": {
- "order": "desc"
- }
- }
- ]
- }
问题来了,需求 1 :检索顺序和结果顺序一致的排在前面咋搞呢?
我第一反应想到的是 Match_phrase 和 slop 结合的方案。
扩展说明一下:在 Elasticsearch 中,match_phrase 查询用于搜索精确的短语,而 slop 参数定义了词条之间的允许的最大距离。
slop 的意思是允许搜索的短语中的词条有多少的移动量来使其与文档中的短语匹配。
一句话:Match_phrase 和 slop 结合的方案,并不能直接实现需求1。
那怎么办?我们单独分析一下吧。
4、需求 1 实现讨论
针对需求1,通常在 Elasticsearch 里,检索顺序和结果顺序一致的功能是相对复杂的,尤其是当查询涉及多个字段和多个关键词时。通常这一需求是通过应用层的代码进行处理,而不是在 Elasticsearch 中。
可能的解决方案参考如下:
如果确实想在 Elasticsearch 里解决这个问题,那么脚本排序可能是唯一可行的内置解决方案,尽管这样可能会带来性能和可维护性的问题。
在多字段和多关键词的情况下,使用 Painless 脚本可能是最直接的方法来精确控制排序逻辑,但通常会牺牲一些性能。
简而言之,Elasticsearch 本身可能不是最适合解决这一具体需求的工具。更合适的方式可能是结合应用层的逻辑来实现这一需求。
一般遇到类似问题,就得有理有据的和产品经理讨论清楚需求,不要任凭产品经理“瞎指挥、瞎忽悠”。
那么借助脚本如何实现呢?构造数据及拆解实现讨论如下:
4.1 步骤1:创建索引及导入数据
- PUT /new_index_2023
- {
- "mappings": {
- "properties": {
- "title": {
- "type": "text",
- "fields": {
- "keyword": {
- "type": "keyword"
- }
- }
- },
- "content": {
- "type": "text"
- },
- "question": {
- "type": "text"
- },
- "answer": {
- "type": "text"
- }
- }
- }
- }
- POST /new_index_2023/_bulk
- {"index": {}}
- {"title": "基础天天练有没有单元练习?"}
- {"index": {}}
- {"title": "计算天天练是小学数学周周学的配套练习吗?"}
- {"index": {}}
- {"title": "小学语文周周学和基础天天练是否为配套练习?"}
- {"index": {}}
- {"title": "小学语文周天是否为配套练习"}
- {"index": {}}
- {"title": "计算天天练是周周学的配套练习吗?"}
- {"index": {}}
- {"title": "小学数学周天是否为配套练习"}
- {"index": {}}
- {"title": "基础天天练和53的区别是什么?"}
- {"index": {}}
- {"title": "计算天天练有视频讲解吗?"}
- {"index": {}}
- {"title": "基础天天练每个学期几本?"}
4.2 步骤2:脚本排序实现
如下实现仅针对需求1,脚本仅供参考。
- POST new_index_2023/_search
- {
- "query": {
- "match": {
- "title": "小学 天天"
- }
- },
- "sort": [
- {
- "_script": {
- "type": "number",
- "script": {
- "source": """
- def title = doc['title.keyword'].value;
- def keywordToFind = params.keywordToFind;
- def schoolKeyword = params.schoolKeyword;
- def indexSchool = title.indexOf(schoolKeyword);
- def indexKeyword = title.indexOf(keywordToFind);
- if (indexSchool < indexKeyword) {
- return 1;
- } else if (indexSchool > indexKeyword) {
- return -1;
- } else {
- return 0;
- }
- """,
- "lang": "painless",
- "params": {
- "keywordToFind": "天天",
- "schoolKeyword": "小学"
- }
- },
- "order": "desc"
- }
- }
- ]
- }
脚本目的:为了对搜索结果进行排序,确保"title"字段中"小学"出现在"天天"之前的文档排在前面。
脚本实现逻辑解读:
步骤 描述 1 通过 doc['title.keyword'].value获取当前文档的"title"字段值并存储在title变量中。2 使用Java的 indexOf方法,找到"小学"在"title"中的位置,并将这个位置存储在indexSchool变量中。3 使用同样的方法,找到"天天"在"title"中的位置,并将这个位置存储在 indexKeyword变量中。4 判断两个关键字的位置:如果"小学"在"天天"之前,返回1。 5 如果"小学"在"天天"之后,返回-1。 6 如果"小学"和"天天"在相同位置(实际上可能不会发生),返回0。 通过上述脚本,Elasticsearch 会优先返回那些"title"字段中"小学"出现在"天天"之前的文档。
读到这里,读者可能会问,这换个词咋办?的确这不是普适的解决方案,而是定制的解决方案。
如果要“普适”,得咱们业务层面自己把控实现,这是大前提!
5、小结
如上看似复杂需求,是借助拆解需求实现的任务分解。
请注意,这是一个非常简化和特定的例子。更复杂的需求(例如,处理多个字段或更多的关键词)可能需要更复杂的脚本。
但切记:如果排序逻辑变得太复杂或影响性能,可能需要考虑在应用层进行后处理,而不是依赖 Elasticsearch 的内部排序。
推荐阅读

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!
-
相关阅读:
Spring Boot 依赖注入实现原理
flinkcdc踩坑指南
Python——使用asyncio包处理并发
状态机-----
【构造】构造题汇总
这是JWT 简单使用
使用扩展运算符(...)合并数组
【自监督Re-ID】ICCV_2023_Oral | ISR论文阅读
借助ChatGPT撰写学术论文,如何设定有效的角色提示词指
【第 8 章 MySQL InnoDB ClusterSet 】
- 原文地址:https://blog.csdn.net/wojiushiwo987/article/details/133285401
