-
一篇文章彻底搞懂熵、信息熵、KL散度、交叉熵、Softmax和交叉熵损失函数
一、熵和信息熵
1.1 概念
1. 熵是一个物理学概念,它表示一个系统的不确定性程度,或者说是一个系统的混乱程度。
2. 信息熵:一个叫香农的美国数学家将熵引入信息论中,用来衡量信息的不确定性,并将它命名为 “香农熵” 或者 “信息熵”。
熵和信息熵的区别就是应用领域和具体含义是不同的。
就像其他地方话叫帅哥,而广东话叫靓仔。
熵 vs 信息熵 类似于 帅哥 vs 靓仔。1.2 信息熵公式
1. 信息熵公式如下所示,其中n表示随机变量的可能取值数,x表示随机变量,P(x)表示随机变量的概率函数。
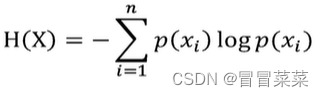
2. 一个简单的例子应用信息熵的公式: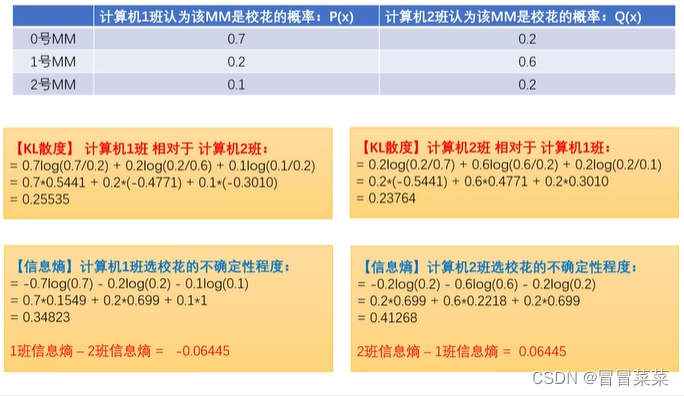
二、KL散度和交叉熵
2.1 KL散度(相对熵)
1. KL散度:是两个概率分布间差异的非对称性度量,KL散度也被称为相对熵。 通俗的说法:KL散度是用来衡量同一个随机变量的两个不同分布之间的距离。
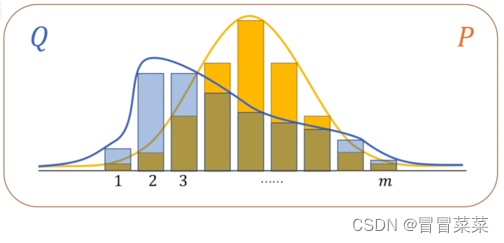
2. KL散度公式如下,其中P( p) 是真实分布,Q(q)是用于拟合P的分布,KL散度越小,Q越接近于P。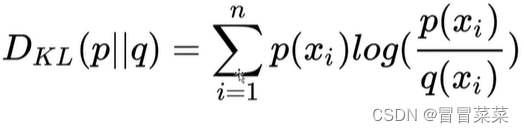
3. KL散度的特性:(1)分对称性:DKL(p||q) ≠ DKL(q||p),只有概率分布完全一样时才相等。(2)非负性:DKL(p||q)恒大于0,只有概率分布完全一样时才等于0。4. 一个简单的例子应用KL散度的公式:
2.2 交叉熵
1. 交叉熵由来是有KL散度公式变形得到的,如下图所示:

2. 交叉熵的主要应用:主要用于度量同一个随机变量X的预测分布Q和真实分布P之间的差距。3. 交叉熵的一般公式:
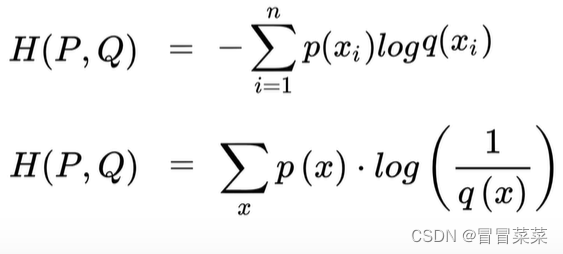
4. 交叉熵的最简公式:
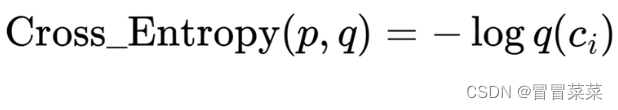
5. 一个简单的例子应用交叉熵的公式:
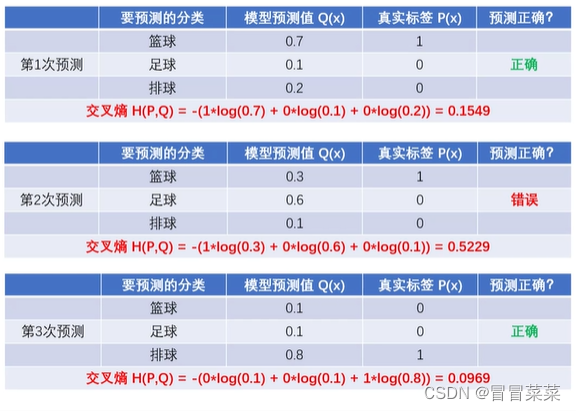
从上述例子得到的结论:(1)预测越准确,交叉熵越小。(2)交叉熵只跟真实标签的预测概率值有关。6. 交叉熵的二分类公式:
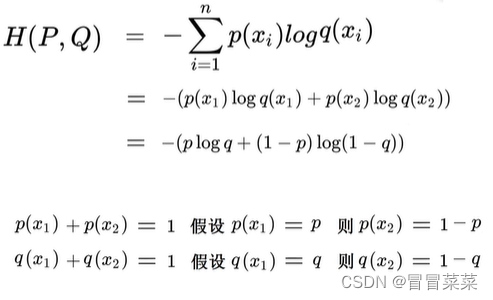
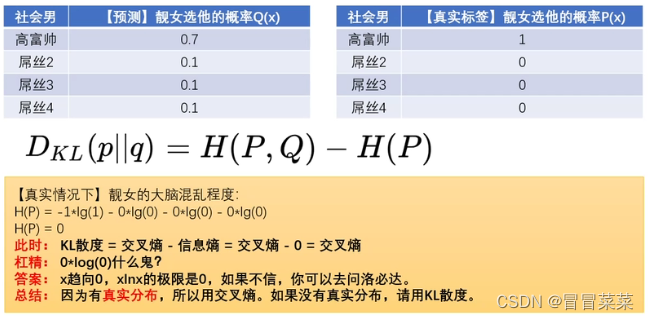
7. 为什么在很多网络模型中,使用交叉熵作为损失函数,而不使用KL散度作为损失函数呢?我们来简单看一个例子直观理解一下:
那总结是因为:交叉熵损失函数在数值稳定性、梯度计算效率和目标函数形式等方面具有优势,因此更常用于网络模型的训练。但在某些特定的任务或场景下,KL散度也可以作为损失函数使用。三、Softmax和交叉熵损失函数
3.1 Softmax
1. 定义:Softmax函数是一种常用的激活函数,它通常用于多分类任务中,将模型的输出转化为概率分布。Softmax函数将输入向量的每个元素进行指数运算,然后对所有元素求和,最后将每个元素除以求和结果,得到一个概率分布。
Soft是将数字转换为概率的神器,是将数据归一化的神器。
2. Softmax的公式如下:

3. 一个简单的例子应用Softmax的公式: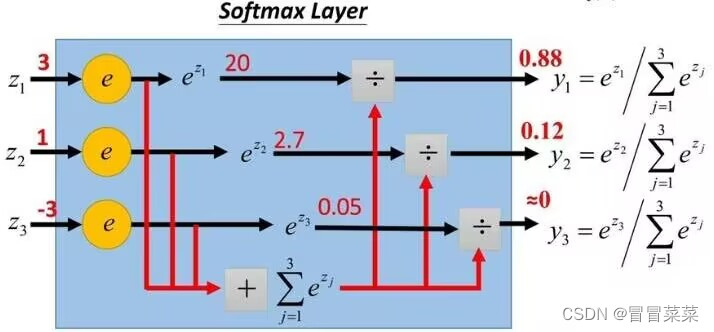
3.2 交叉熵损失函数
1. 交叉熵损失函数公式:
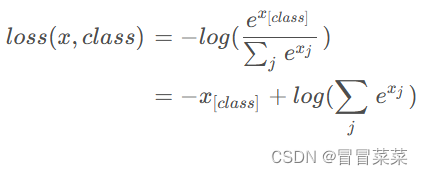
注意:(1)因为有些输入是数值,需经过Softmax转换为概率,所以log括号里写的是Softmax公式。(2)标签中有个真实值肯定为1,其余为0,所以相当于交叉熵最简公式。
2. 代码块举例:
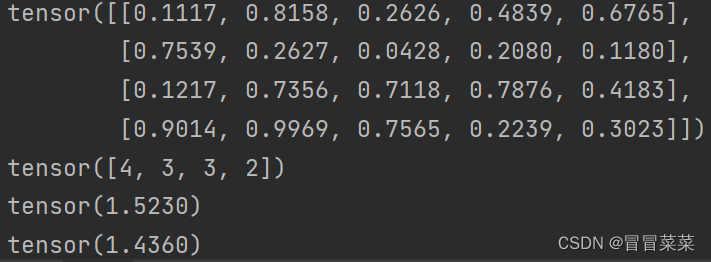
import torch import torch.nn as nn #定义数据 torch.manual_seed(100) #设置随机种子,以保证结果的可重复性。 predict = torch.rand(4, 5) label = torch.tensor([4, 3, 3, 2]) print(predict) print(label) #定义交叉熵损失函数 criterion = nn.CrossEntropyLoss() #计算整体的损失值 loss = criterion(predict, label) print(loss)#最后将这四个样本的损失值进行求平均,得到整体的损失值。 #计算单个样本的损失值 one_loss = criterion(predict[0].unsqueeze(0), label[0].unsqueeze(0)) #.unsqueeze(0)是转二维向量 print(one_loss)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
相关阅读:
PHP- PHP中与HTML标签的联合使用。注意:<?php 之后的需要有一个空格?>
lodash已死?radash库方法介绍及源码解析 —— 对象方法篇
31.带有文本和渐变阴影的CSS图标悬停效果
Gin框架---环境搭建
vscode settings
《TCP/IP网络编程》阅读笔记--基于UDP的服务器端/客户端
前后端分离解决跨域问题
[ Docker ] 部署 nps 和 npc 实现内网穿透
Python中的3D矩阵操作
Mybatis的一级缓存
- 原文地址:https://blog.csdn.net/m0_62881487/article/details/133279415
