-
【Linux】文件系统
文件系统主要来介绍,如何通过对磁盘文件进行分门别类地存储,来支持更好的存取。
磁盘结构
磁盘不同于内存,属于永久性存储介质。

盘面上存储的都是二进制数据。
其中每个二进制数据是由一块磁铁来标定的。磁盘上聚集有众多这样的小磁铁。
而所谓向磁盘写入数据,本质就是用磁头来改变磁盘上小磁铁的正负性。

磁盘的存储结构
扇区作为磁盘存储数据的基本单位,一般大小是512byte。
虽然磁盘的基本单位是扇区(512byte),但是操作系统(文件系统)和磁盘进行IO的基本单位是4KB(8*512byte)。
原因是,512byte太小了,可能导致多次IO,进而造成效率的降低;而且如果操作系统使用和磁盘一样的大小,当磁盘基本大小发生改变,操作系统的源代码也需要随之改变,所以要进行硬件与软件(操作系统)的解耦。
4KB一般叫做block(块)大小,磁盘也被称为块设备。
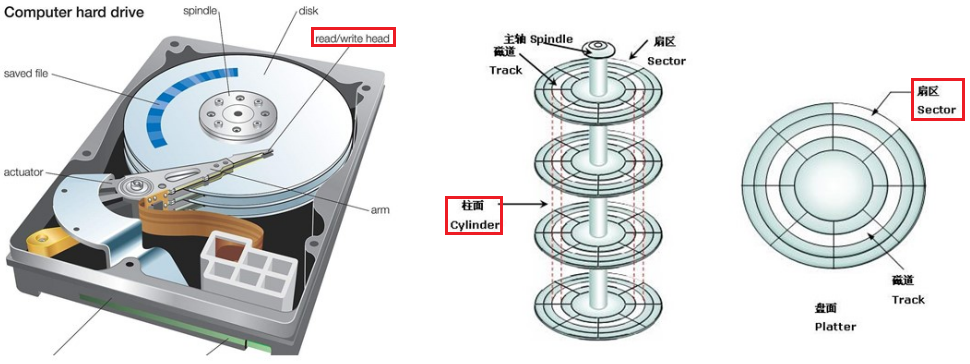
在物理上,通常是通过CHS寻址的方式将数据写入到磁盘指定的扇区里。
CHS寻址:- 确定在哪一个盘面上(对应的就是哪一个磁头) - Head
- 确定在哪一个磁道(柱面)上 - Cylinder
- 确定在哪一个扇区上 - Sector
有了CHS寻址,就能找到磁盘上的任意一个扇区了。
磁盘的抽象(虚拟,逻辑)结构
对磁盘结构的抽象,主要是将磁盘的圆形结构抽象成线性结构。
可以借助磁带由卷被拉成条来理解:

磁盘被展开成线性结构后,其数据可以看做存放在一个大数组中,对于磁盘上的每一个扇区,都可以通过数组下标的方式找到并访问。
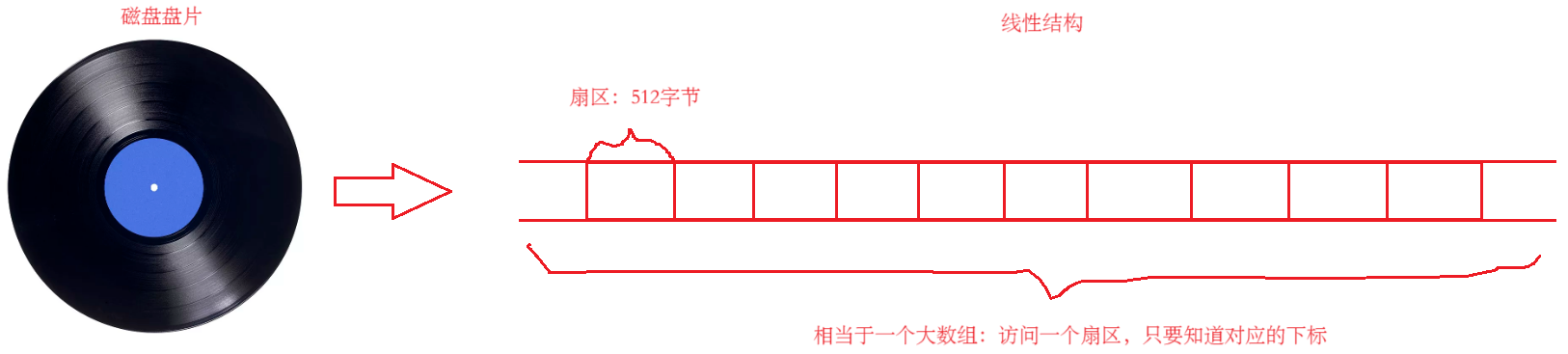
所以通过磁盘结构的抽象,
将数据存储到磁盘转换为数据存储到对应数组;
将找到磁盘特定扇区的位置转换为找到数组中对应下标的位置;
将对磁盘的管理转换为对数组的管理。
但是这个数组非常大,直接管理起来也会非常困难,所以可以通过分区划组的方式缩小管理区间的单位,来实现整个数组的管理。
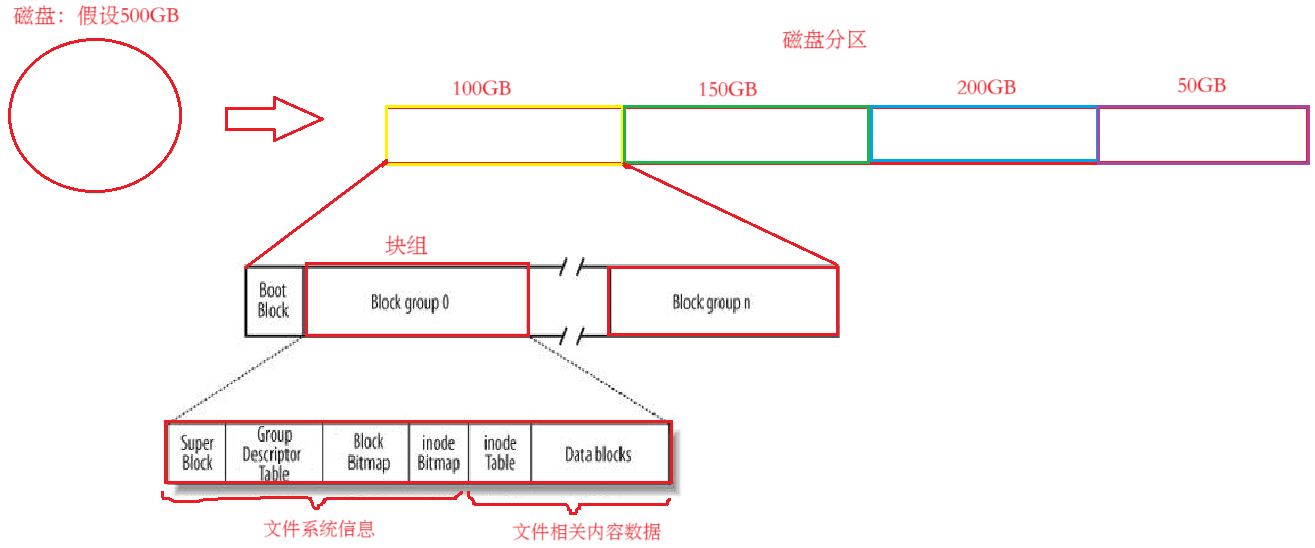
所以,对磁盘的管理通过不断划分,最终转换为对块组的管理。只要能管理好一个块组,其它块组也能管理好,从而管理好整个分区,以此类推,最终管理好整个数组。
块组信息分析:- Super Block:Super Block的信息并不属于块组。它存放的是整个文件系统的属性信息,可以认为代表的就是文件系统本身。至于在块组里面加上Super Block,相当于是在给文件系统的总体宏观信息做备份,便于文件系统出问题时进行恢复。
- Data blocks:多个block(4KB)的集合(保存的是对应文件的内容)
- inode Table:inode是一个大小为128byte的空间,保存的是对应文件的属性信息。所以,inode Table保存的是该块组内,所有文件的inode集合。每一个inode块,都要有一个inode编号。一般而言,一个文件,对应一个inode块,对应一个inode编号。
- BlockBItmap:存放的是比特位,用于标注Data blocks中,哪些block被使用,哪些没有被使用。
- inodeBitmap:存放的是比特位,用于标注inode Table中,哪些inode被使用,哪些没有被使用。
- Group Descriptor Table(GDT):块组描述符。用于描述整个块组的信息,例如:这个块组有多大,有多少个inode,已经使用了多少个inode,有多少个block,已经使用了多少个block…
文件 = 内容 + 属性,从块组的分析看出,Linux在磁盘上存储文件的时候,是将内容和属性分开存储的,也就是说,Linux是将文件内容和文件属性分开管理的。
有了上述对块组的管理模式,任意一个文件就都能做到可追溯,可管理。
而对于找到一个文件,只要找到文件对应的inode编号,就能找到文件的inode属性集合,可是文件的内容如何找到呢?文件的内容存在Data blocks中,且不一定只存在一个block(4KB)中。
其实inode结构中对于文件在Data blocks中的存储位置用了一个blocks数组进行标定。通过这个数组可以找到文件存储在Data blocks中的所有内容。struct inode { // 文件的大小 // 文件的inode编号 //其它属性 int blocks[N]; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
尽管如此,如果存储的文件特别大,inode中定义的blocks数组空间显然会不够,那这要如何存储呢?
要知道,Data blocks中block不是都只能用来存文件数据,它也可以用来存其它block的块号。用这样的存储方式,会展现出多叉树的存储结构,所以大量的叶子结点就存储了文件的所有信息。
找到一个文件,只要找到文件的inode编号就可以了,那inode编号又如何得到呢?
inode编号的获取是依托于目录结构的。
目录也是文件,有自己的inode,在Data blocks中存储的是[文件名 : inode编号]的映射关系。也就是说,知道了文件所在目录/路径,就能知道文件的inode了。 -
相关阅读:
网络七层结构(讲人话)
MyBatis学习:使用resultMap或在SQL语句中给列起别名处理查询结果中列名和JAVA对象属性名不一致的问题
微同城生活圈小程序源码系统 专业搭建本地生活服务的平台 带完整搭建教程
基于nodejs+vue全国公考岗位及报考人数分析
spring - AnnotationConfigApplicationContext启动之reader、scanner、register逻辑整理
get_post (攻防世界)(简单php)
org.apache.commons.lang3.StringUtils工具类使用大全
Part3_理解MATSIM_第51章 效益-成本分析中matsim的微观经济学解释
MySQL的index merge(索引合并)导致数据库死锁分析与解决方案 | 京东云技术团队
Mybatis-Plugs开发手册
- 原文地址:https://blog.csdn.net/weixin_62172209/article/details/132646673