-
【数据结构】链表的学习和介绍
前言
今天,我们来学习,数据结构中的链表
链表是什么
链表,就是多个结构体变量之间,通过结构体指针连接在一起的一种数据结构
提示:
本篇文章主要讲解动态链表,对于静态链表不做过多介绍链表的分类
链表可分为静态链表和动态链表
静态链表
只是初步了解,更详细的操作(比如插入节点、删除节点)在这篇文章中不做说明
静态链表,实际上就是一个结构体数组
分配一整片连续的内存空间,各个结构体变量集中安置,逻辑结构上相邻的数据元素,存储在指定的一块内存空间中,数据元素只允许在这块内存空间中随机存放,这样的存储结构生成的链表称为静态链表。也就是说静态链表是用数组来实现链式存储结构
下面,给出一段例子
这就是静态链表的定义和初始化#includeusing namespace std; struct Node { int data;//数据域 int next;//指针域 //注释1 //静态链表的节点是索引值 不是结构体指针 }; int main() { struct Node n[10]; for (int i = 0; i < 10; i++) { n[i].data = i; n[i].next = i + 1;//每个节点的下一个节点位当前索引值+1 } n[9].next = -1; //注释2 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
注释1:
相信大家都知道,链表这种数据结构,前面一部分存储的是数据,后面一部分存储的是指向下一个变量(一般称为节点)的指针
存储数据的区域,就称为数据域
存储指针的区域,就称为指针域注释2:
n[9].next = -1;- 1
这行代码的意思是:将这个链表的最后一个节点 的指针(索引值)赋为-1
为什么要这么做呢?
首先:
当我们已经遍历到最后一个节点时,没有下一个节点了,那么此时的next指针指向的就是一个随机值,这可能会导致发生不可预期的行为,比如程序崩溃其次,将最后一个节点的指针赋为-1,有便于我们检查对于链表的遍历是否结束,这一点在后面会详细说明
最后,当我们在处理链表的最后一个字节时,可以通过-1来直接找到它
静态链表的特点
静态链表需要预先开辟一块空间来存储,并且,静态链表的大小是固定的,(毕竟它没用到动态内存分配 没法变大),以及,静态链表在存储时,在内存中是连续存储的
静态链表也有一些好处,比如:
静态链表可以直接通过索引访问,不需要指针(好像这二者差不多)动态链表
接下来,就进入到我们这篇文章的重头戏:动态链表了
要实现动态链表,有两个东西比较重要:
动态内存的申请,是动态链表之所以被称为动态链表的原因
模块化设计,可以使代码可读性和简洁性提升(当然,都写在一起也不是不行…)下文为了便于理解,对于数据域只使用一个int类型的变量
动态链表的实现思路
本篇文章将动态链表的实现分为五个步骤,
1.创建链表表头
2.创建节点
3.插入节点
4.删除节点
5.打印链表
前四步比较关键,最后一步一般用于测试自己创建的链表是否符合自己的预期创建链表表头
要创建链表,我们首先需要创建一个表头,来指向整个链表,可以将表头理解为第一个节点,
想指向一个结构体变量(也就是节点),那表头应该是结构体指针c
问题来了,如何把一个结构体指针,变成结构体变量呢
这时候,我们就要学习动态内存申请,即malloc函数
(注意:使用new也可以,会在本节的末尾附上使用new创建动态链表的代码)给出一个示例来说明如何创建头节点
struct Node* createList() { struct Node* headNode = (struct Node*)malloc (sizeof(struct Node)); // //用malloc申请内存 headNode->next = nullptr; //注释3 return headNode; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注释3:
有的同学可能会有疑问,为什么要将头节点初始化为空指针首先,现在链表里只有一个变量(节点),不初始化成空指针,那不就变成野指针了
其次,初始化成空指针的话,当我们后续无论是查找头节点还是继续插入新的节点的时候,都是能很轻松的找到头节点
创建节点(一个)
/*- 1
创建节点的这个函数
/*/
下面给出一个例子:
将创建节点的内容模块化城createNode函数struct Node* createNode(int data) { struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; //传入数据 newNode->next = nullptr; //注释4 return newNode; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注释4:
类似的,在创建新的节点时,将next赋值为空指针,
是因为这个新节点并不知道链表中下一个节点是什么,所以只能赋值为空指针插入节点
对于插入,有三种方式:头插法,尾插法,指定位置插入
下面给出一个使用头插法例子:
将创建节点的内容模块化城insertNodeByHead函数(代码中给出了相应的注释)
void insertNodeByHead(struct Node* headNode, int data) { struct Node* newNode = createNode(data); //创建插入的节点 newNode->next = headNode->next; //修改指针域 headNode->next = newNode; //指向要插入的数据 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注释5:
在编写创建节点和插入节点的时候,我感觉这两步有一些联系,在此说明一下:
这两个步骤通常是相互关联的,因为通常我们需要先创建一个新的节点,然后将其插入到链表中。删除节点
下面给出一个例子:
将创建节点的内容模块化城deleteNodeByAppoin函数(代码中给出了相应的注释)
//删除节点 void deleteNodeByAppoin(struct Node* headNode, int posData) //headNode只是一个传入的参数名,不是真的头节点 不要弄混 //posData是要删除的数据 { struct Node* posNode = headNode->next; struct Node* posNodeFront = headNode; //分别对于链表是否为空和posData是否存在进行判断 if (posNode == nullptr) { cout << "链表为空 操作错误" << endl; } else { while (posNode->data != posData) //遍历查找 { posNodeFront = posNode; posNode = posNodeFront->next; if (posNode == nullptr) { cout << "未找到要删除的数据" << endl; return; } } posNodeFront->next = posNode->next; //用free函数释放内存 free(posNode); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
遍历打印链表
通过遍历打印链表
void PrintList(struct Node* headNode) { struct Node* pMove = headNode->next; while (pMove) //当pmove不为空指针时 持续遍历 //这里就可以联系到创建节点时,为什么要将next初始化为空指针 //巧妙 妙 //while这里还能这么写 学到了 学到了 { cout << pMove->data; pMove = pMove->next; } cout << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
主函数
int main() { struct Node* list = createList(); insertNodeByHead(list, 1); insertNodeByHead(list, 2); insertNodeByHead(list, 3); PrintList(list); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果:
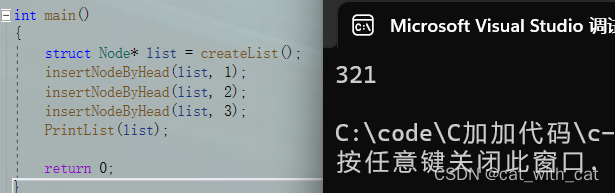
注释6:
因为用的是头插法,所以先插入的变量在遍历输出的时候,在后面完整代码
#includeusing namespace std; struct Node { int data; struct Node* next;//静态链表的节点是索引值 不是结构体指针 }; //创建表头 struct Node* createList() { struct Node* headNode = (struct Node*)malloc (sizeof(struct Node)); //用malloc申请内存 headNode->next = nullptr; //注释3 return headNode; } //创建节点(一个) struct Node* createNode(int data) { struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; //传入数据 newNode->next = nullptr; return newNode; } //插入节点 void insertNodeByHead(struct Node* headNode, int data) { struct Node* newNode = createNode(data); //创建插入的节点 newNode->next = headNode->next; //修改指针域 headNode->next = newNode; //指向要插入的数据 } //删除节点 void deleteNodeByAppoin(struct Node* headNode, int posData) //headNode只是一个传入的参数名,不是真的头节点 不要弄混 //posData是要删除的数据 { struct Node* posNode = headNode->next; struct Node* posNodeFront = headNode; //分别对于链表是否为空和posData是否存在进行判断 if (posNode == nullptr) { cout << "链表为空 操作错误" << endl; } else { while (posNode->data != posData) { posNodeFront = posNode; posNode = posNodeFront->next; if (posNode == nullptr) { cout << "未找到要删除的数据" << endl; return; } } posNodeFront->next = posNode->next; //用free函数释放内存 free(posNode); } } //遍历打印链表 void PrintList(struct Node* headNode) { struct Node* pMove = headNode->next; while (pMove) //当pmove不为空指针时 持续遍历 //这里就可以联系到创建节点时,为什么要将next初始化为空指针 //巧妙 妙 //while这里还能这么写 学到了 学到了 { cout << pMove->data; pMove = pMove->next; } cout << endl; } int main() { struct Node* list = createList(); insertNodeByHead(list, 1); insertNodeByHead(list, 2); insertNodeByHead(list, 3); PrintList(list); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
使用new
使用new的话,只需要在创建节点和插入节点那里修改一下就可以了
Node* createList() { Node* headNode = new Node; headNode->next = nullptr; return headNode; } Node* createNode(int data) { Node* newNode = new Node; newNode->data = data; newNode->next = nullptr; return newNode; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
实际项目中可能会遇到的小问题
在编写如通讯录、图书馆信息管理系统的时候,data一般都是结构体,那么在输入的时候,就可能会遇到输入完数字,再输入字符串,
那么就存在需要清空缓冲区的问题此时,我们可以用setbuf函数
使用格式如下:
setbuf(stdin,NULL);清空缓冲区函数- 1
(在此只是介绍一下,作者也不会)
结语
算是初步把链表中的静态和动态链表了解和学习了一下,希望这篇文章对你有帮助,我们下篇文章见~~
-
相关阅读:
经验风险最小化与极大似然估计概念
条件构造器
webshell免杀之传参方式
西门子PLC的优势在哪呢?
netstat –ano|findstr “port”命令
6. Python数据类型之浮点数
用html做一个漂亮的网站【茶文化12页】期末网页制作 HTML+CSS网页设计实例 企业文化网站制作
【计算机视觉40例】案例23:语义分割
网络安全(黑客)自学
Tomcat下载安装配置
- 原文地址:https://blog.csdn.net/cat_with_cat/article/details/133145089
