-
自定义数据类型
前言:小伙伴们又见面啦,今天这篇文章,我们来谈谈几种自定义数据类型。

目录
一.都有哪些自定义数据类型
我们在C语言的基础中已经了解到了结构体,是一种对多种数据集中管理的一种自定义数据类型。
除此之外,我们还有另外三种:-
- 位段
- 枚举
- 联合
接下面我们就开始对这四种数据类型逐一展开讲解。
二.结构体
在我们前边的文章《C语言基础之——结构体》中我们已经对结构体展开了细致的讲解,所以在这篇文章中我们不再重复讲解。
那么在这篇文章中,我们来谈谈结构体类型的大小。
我们知道任何一种数据类型都有它所占用的内存大小,但是结构体类型却是多种数据类型的整合。
那小伙伴们是否知道结构体类型该如何计算大小呢???
来看例子:
- #include
- struct Str1
- {
- char a;
- char b;
- int c;
- };
- struct Str2
- {
- char a;
- int b;
- char c;
- };
- int main()
- {
- int num1 = sizeof(struct Str1);
- int num2 = sizeof(struct Str2);
- printf("%d\n", num1);
- printf("%d\n", num2);
- }
小伙伴们可以猜一猜,Str1 和 Str2的内存大小会是多少呢???
有的小伙伴可能会说:啊,都是两个char类型和一个int类型,那大小不就是6呗。
那到底是不是6呢???我们来看结果:

哇塞,天差地别,不仅不是6,而且两个数还不一样。
这是为什么呢???
事实上,对于结构体,有结构体内存对齐这样一个概念。
结构体内存对齐
1.如何对齐
我们先来看对齐的规则:
1.第一个成员放在与结构体变量偏移量为0的地址处。
2.其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数与该成员大小的较小值。
- 博主所使用的VS2019的默认对齐数为8
- Linux中没有默认对齐数,对齐数就是成员变量本身的大小
3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4.如果出现嵌套结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
什么意思呢,下面我们根据例子来具体讲解:
struct Str1
{
char a;
char b;
int c;
};首先来看这个结构体,它的第一个成员变量a为char型, 大小为1个字节,放在结构体变量偏移量为0的地址处,即从0开始存放。
然后第二个成员变量b也是char类型,大小为1个字节,从第二个成员变量开始我们要根据最大对齐数进行对齐,将1与8相比,肯定是1较小,所以对齐数为1,所谓对齐数,就是这个成员变量所存放的空间的前边所占用的空间个数需要是对齐数的整数倍,要对齐到1的整数倍的位置,我们现在只占用了一个字节,1是1的整数倍数,那自然就是从第二个字节开始存放,占用一个字节。
最后来看第三个成员变量c为int类型,大小为4个字节,则其对齐数为4,那么我们要对齐到4的整数倍的位置,但是现在我们只有两个字节的位置被占用,2不是4的整数倍数,所以我们还需要浪费两个字节,来实现对齐到4的倍数的位置,所以要从标号为4的位置存放四个字节。



这样一来我们就得到了我们的结果,8个字节。
下边我们继续来看一个例子:
struct Str2
{
char a;
int b;
char c;
};第一个为char型,放在0处。
第二个为int型,对齐数为4,现在只占用了一个字节,不是4的整数倍,所以要浪费3个字节,从标号为4的位置开始,占用四个字节。
第三个为char型,对齐数为1,8是1的整数倍,所以直接从标号为8的位置开始,占用一个字节。



这个时候出问题了,这不是才9个字节吗,那结果为什么是12个字节呢???
这时候来看我们规则的第三条: 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
我们上述结构体的最大对齐数为int型的4,但是现在我们只占用了9个字节,并不是4的整数倍,所以我们还得浪费3个字节,达到12个字节,才是我们最终的结果。
下面我们来看最后一个例子:
struct Str3
{
double a;
char b;
int c;
};struct Str4
{
char a;
struct Str3 s3;
double c;
};我们来计算Str4这样一个嵌套结构体的大小。
经过我们上边的学习,已经能够很容易的算出,Str3的大小为16个字节。下边我们来计算Str4。
第一个为char型,放在地址为0的位置,占用一个字节。
第二个为struct Str3结构体类型,大小为16个字节,那么根据我们的规则4,嵌套的结构体对齐到自己内部的最大对齐数的整数倍处,那么Str3内部的最大对齐数为double类型的8,所以要是8的倍数,很显然1并不是8的倍数,所以要浪费7个字节,从标号为8的位置开始,占用16个字节。
第三个为double类型,大小为8个字节,对齐数为8,前边刚好占用了24个字节,是8的整数倍,所以我们就从标号为24的位置开始,占用8个字节。



这样,我们总共就是占用了32个字节。
到这里,我们就讲完了通过结构体内存对齐的规则来计算结构体大小的知识。
那么小伙伴们是否有个疑惑,我们为什么就非得对齐呢?
2.为什么要对齐
我们通过查阅大量的资料,最终得出以下两点:
1.平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据;某些硬件平台只能在某些地址处取某些特定的类型的数据,否则就会抛出硬件异常。
数据结构(尤其是栈)应该尽可能的在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要做两次内存访问;而对齐的内存访问仅需要一次访问。
总体来说:
结构体的内存对齐是拿空间来换取时间的做法。牺牲空间来换取效率。
那么有没有什么办法能够帮助我们即能够提升效率,又能节省空间呢???
3.节省空间和提升效率的方法
(1)让占用空间小的成员尽量集中在一起
struct Str1
{
char a;
char b;
int c;
};
struct Str2
{
char a;
int b;
char c;
};就比如还是我们这两个结构体,成员变量一模一样,但是大小却不一样,但是Str1的空间是小于Str2的,所以,第一种方法就是:让占用空间小的成员尽量集中在一起。
(2)修改默认对齐数
我们知道,默认对齐数这个规则对我们的空间占用影响很大,那我们便可以通过修改默认对齐数的方法来实现节省空间和提升效率。
那么默认对齐数该如何修改呢???
通过#pragma这个预处理指令来改变。
- #include
- #pragma pack(1)//将默认对齐数修改为1
- struct Str1
- {
- char a;
- char b;
- int c;
- };
- #pragma pack()//恢复默认对齐数的原值
- struct Str2
- {
- char a;
- int b;
- char c;
- };
- int main()
- {
- int num1 = sizeof(struct Str1);
- int num2 = sizeof(struct Str2);
- printf("%d\n", num1);
- printf("%d\n", num2);
- }
我们通过#pragma pack()这个指令,可以将默认对齐数修改为()内的值,比如我们上述代码修改为1, 修改之后,默认对齐数就固定为1,每个数据都对齐到1的整数倍,同时也要记得及时恢复默认对齐数的原值,确保只有这一块的结构体我们需要修改,以免发生错误。
来看结果:

除此之外,我们还有第三种方法,那就是——位段。
三.位段
讲完了结构体的内存分配情况之后,我们就得紧接着来谈谈结构体实现位段的能力。
1.什么是位段
位段的出现,是为了让结构体更加节省空间。
位段的声明和结构体是类似的,有两处不同:
- 位段的成员必须是int、unsigned int 、signed int或char类型
- 位段的成员名后边有一个“冒号”和一个数字
来看例子:
struct Str1
{
char a : 3;
char b : 4;
char c : 5;
char d : 4;
};位段的位,指的是二进制的位数,char a : 3,就表示a这个数据占用3个bit位。
如果不用位段,我们这个结构体就是4个字节的大小,但是使用位段之后来看:

只用到了3个字节,节省了空间。
这种情况适用于能够知道创建的数据大概会占用多少的空间。
2.位段的的内存分配
那么我们上述结构体通过位段实现的8个字节的空间又是怎么来的呢???
位段开辟空间是一步一步来的,如果是int型,就会先开辟4个字节给你用,如果不够,那就再开辟一个,char同样。
我们很清楚,一个字节是8个bit位,那么a、b、c、d分别为3、4、5、4个bit位,3 + 4 = 7 < 8,所以a和b共用一个字节,剩下一位不够c用,那就丢掉,再开辟一个。存入c之后剩余3位,不够d用,便继续丢掉,在开辟,最终一共开辟3个字节。
虽然位段能够帮助我们节省一大部分的空间,但这并不代表着我们可以随便的使用位段。
因为其涉及着很多的不确定因素,不能跨平台,所以注重可移植性的程序应避免使用位段。
3.位段的跨平台问题
- int位段被当成有符号数还是无符号数是不确定的。
- 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32)
- 位段中的成员在内存中从左向右分配还是从右往左分配标准尚未定义。
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段的剩余位时,是舍弃剩余的位还是利用是不确定的。
对于第4条,我们上边的代码已经能够验证,在当前的VS2019编译器下是直接舍弃。
四.枚举
枚举,顾名思义也就是一一的列举。
把我们可能需要用到的数据一一列举出来。
一周的七天;
一年的月份;
一年的四季
这些都能够写成一个枚举类型来一一列举,下面我们就来看看枚举的具体用法。
1.枚举类型的定义
定义枚举常量要用到enum
enum Season
{
SPRING,
SUMMER,
AUTUMN,
WINTER
};这样我们就定义出来一个简单的季节枚举。
值得注意的是,每个枚举常量之间都用逗号隔开,最后一个枚举常量后边不用跟任何符号,而且枚举常量一般都用其英文的大写字母表示。
在枚举类型中,枚举常量都表示一个常数,从第一个枚举常量开始,代表0,此后逐个递增,因此枚举常量都是int类型。
- #include
- enum Season
- {
- SPRING,
- SUMMER,
- AUTUMN,
- WINTER
- };
- int main()
- {
- printf("%d\n", SPRING);
- printf("%d\n", SUMMER);
- printf("%d\n", AUTUMN);
- printf("%d\n", WINTER);
- return 0;
- }
结果如下:

枚举常量不能在枚举类型外修改,但是可以在其定义时修改,并且会影响到后边的值:
- #include
- enum Season
- {
- SPRING,
- SUMMER = 100,
- AUTUMN,
- WINTER
- };
- int main()
- {
- printf("%d\n", SPRING);
- printf("%d\n", SUMMER);
- printf("%d\n", AUTUMN);
- printf("%d\n", WINTER);
- return 0;
- }
例如我们将SUMMER改为100,那么AUTUMN和WINTER也会在此基础上累加。

我们现在也已经了解到,枚举其实也是一种定义常量的方式,那我们前边也学过#define同样可以定义常量,那么为什么非要用枚举类型呢???
2.枚举的优点
- 增加代码的可读性和可维护性。
- 和#define定义的标识符比较,枚举有类型检查,更加严谨。
- 便于调试。
- 使用方便,一次可以定义多个常量。
五.联合体
1.联合体的定义
联合也是一种特殊的自定义类型。
这种类型定义的变量也包含一系列的成员,特征是这些成员共用同一块空间(所以也叫共用体)
- #include
- union Un
- {
- int a;
- char b;
- };
- int main()
- {
- union Un un;
- printf("%d\n", sizeof(un));
- printf("%p\n", &un);
- printf("%p\n", &(un.a));
- printf("%p\n", &(un.b));
- return 0;
- }
来看,我们输出一下这个联合体的大小、地址以及其成员的地址:
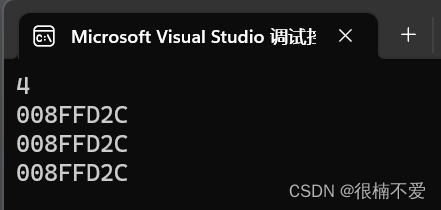
能够看出,联合体的大小确实是int型的4个字节,且成员变量的地址都相同,这就说明它们共用同一块内存空间。
2.联合体的使用
用来判断编译器的大小端存储:
- #include
- int check_sys()
- {
- union Un
- {
- int a;
- char b;
- }u;
- u.a = 1;
- return u.b;//返回1表示小端,返回0表示大端
- }
- int main()
- {
- int ret = check_sys();
- if (ret == 1)
- printf("小端\n");
- else
- printf("大端\n");
- return 0;
- }
既然共用一块空间,那么我们就可以通过不同类型的字节数来进行大小端的判断。

得出我们当前编译器为小端存储。
对于联合体的具体使用,我们指出一个方向:当成员变量不需要同时使用时,可以使用联合体。
3.联合体大小的计算
- 联合体的大小至少是最大成员的大小。
- 当最大成员大小不是最大对齐数的整数倍时候,就要对齐到最大对齐数的整数倍。
- #include
- union Un
- {
- int a;
- char b[5];
- };
- int main()
- {
- printf("%d\n", sizeof(union Un));
- return 0;
- }
来看这个联合体,它的大小是多少?5吗???

并不是,而是8。
因为最大对齐数为4,5不是4的整数倍,所以就要浪费3个字节达到8。
六.总结
关于自定义数据类型的讲解到这里就结束啦。
今天的文章也是相当的长啊,快累死博主我了呜呜呜~~~

最后还是希望文章能够帮助到大家,不要忘记一键三连哦!!!
我们下期再见!!!
-
相关阅读:
hive建表,与插入数据
python-爬虫-xpath方法-批量爬取王者皮肤图片
Python tests in.....
数字先锋 | 打造城市“一朵云”,天翼云推动芜湖新型智慧城市建设
JavaScript字符串③
10年开发大佬,用300案例,附学习路线,详解多线程编程核心
腾讯面试——自然语言处理
SpringBoot使用git-commit-id-maven-plugin打包
[React] Zustand状态管理库
用wpf替代winform 解决PLC数据量过大页面卡顿的问题
- 原文地址:https://blog.csdn.net/2303_78442132/article/details/133243562
