-
Speech | 轻量级语音合成论文详解及项目实现
2023_LIGHTWEIGHT AND HIGH-FIDELITY END-TO-END TEXT-TO-SPEECH WITH MULTI-BAND GENERATION AND INVERSE SHORT-TIME FOURIER TRANSFORM
目录
【PS2】AttributeError: 'HParams' object has no attribute 'seed'
【PS3】EOFError: Ran out of input
【PS5】 TypeError: __init__() takes 1 positional argument but 2 were given
1.论文详解
1.1.介绍
介绍了之前的俩阶段语音合成(声学模型和Vocoders),因为VITS是高质量端到端的模型,所以论文提出的模型是基于VITS轻量级的端到端模型,论文主要几种在模型的解码部分,也就是转换潜在的声学特征到wavaform,用简单的反向短时傅立叶变换 (iSTFT)代替一部分解码器,以高效地完成频域到时域的转换.在推理提升速度时,使用多段处理。在提出的方法时,每一个iSTFTNet,子段信号。推理时,比原本的VITS快了4.1倍,
1.2.VITS算法
1.2.1.简短的介绍了vits的原理,这里不过多介绍,更多可查看【VITS论文总结及项目复现】
1.2.2.每个模型的推理速度
这里用RTF计算,也就是时间token除以合成的语音长度,作为客观标准。
1.3.提出的方法
1.3.1.在输出层将原本的vits中HiFi-GAN替换成样本反向短时傅立叶变换
1.3.2.多段反向短时傅立叶变换变量自动编码(Multi-band iSTFT VITS)
下图为模型的整体框架,

1.3.3.多流反向短时傅立叶变换变量自动编码(Multi-stream iSTFT VITS)
与 MB-iSTFT-VITS 不同,MS-iSTFT-VITS波形是完全可训练的,不再受固定子带信号的限制。1.4.实验
数据集 : LJ Speech dataset
比较了5种基于vits的模型:
- VITS: 正式的VITS1,其超参数与原始 VITS 相同。
- Nix-TTS:Nix-TTS 的预训练模型2. 使用的模型是经过优化的 ONNX 版本 [27]。请注意,实验中使用的数据集与 Nix-TTS 使用的数据集完全相同。
- iSTFT-VITS :将 iSTFTNet 纳入 VITS 解码器部分的模型。iSTFTNet 的架构为 V1-C8C8I,这是 [14] 中描述的最佳平衡模型。该架构包含两个上采样比例为[8, 8]. 快速傅立叶变换(FFT)的大小、跳变长度和窗口长度分别设置为 16、4 和16。
- MB-iSTFT-VITS 第 3.2 节中介绍的一个拟议模型。子频带数 N 设为 4。两个残差块的上采样比例为 [4,4],以匹配每个子带信号分解后的分辨率。pseudo-QMF的分析滤波器分解的每个子带信号的分辨率相匹配。iSTFT 部分的 FFT 大小、跳变长度和窗口长度与伪 QMF 分析滤波器分解的各子波段信号的分辨率相同。
- MS-iSTFT-VITS: 第 3.3 节中介绍的另一种拟议模型。根据 [10],基于卷积的可训练合成滤波器的内核大小设定为 63,不带偏差。可训练合成滤波器的核大小设定为 63,没有偏差。其他条件与 MB-iSTFT-VITS 相同。
下图为比较结果
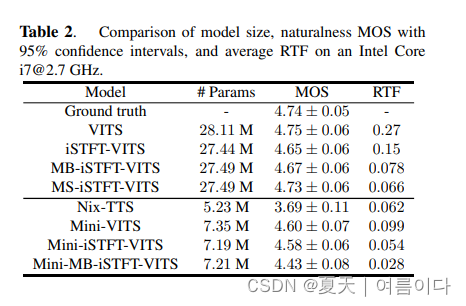
1.5.结论
在本文中,提出了一种端到端 TTS 系统,该系统能够在设备上实现高速语音合成。提出的方法是在名为 VITS 的成功端到端模型的基础上构建的,但采用了几种技术来加快推理速度,例如通过 iSTFT 减少解码器计算的冗余,以及采用多波段并行策略.由于所提出的模型是以完全端到端方式进行优化的,与传统的两阶段方法相比,所提出的模型可以充分享受其强大的优化过程。实验结果表明方法生成的语音与 VITS 合成的语音一样自然,同时还能以更快的速度生成波形。未来的研究包括将提出的方法扩展到多扬声器模型。
2.项目实现
2.1.数据准备
准备的语音数据必须是22050Hz,单通道(Mono),PCM-16bit
单人
- dataset/001.wav|您好
- dataset/001.wav|안녕하세요
- dataset/001.wav|こんにちは。
多人
dataset/001.wav|0|こんにちは。中间数字是人物序号ID,从0开始
- # Cython-version Monotonoic Alignment Search
- cd monotonic_align
- mkdir monotonic_align
- python setup.py build_ext --inplace
论文提供了几种训练结构,因为在论文中MB-iSTFT-VITS效果最好,本文使用此模型
改变training_files` 和 `validation_files`处的路径
新建一个自己数据集的config.json文件
修改:
- "training_files":"./filelists/history_train_filelist.txt.cleaned",
- "validation_files":"./filelists/history_train_filelist.txt.cleaned",
- "text_cleaners":["cjke_cleaners2"], #多语言自定义函数
- # "text_cleaners":["korean_cleaners"], #训练语言
2.2.数据预处理
- # Single speaker
- # python preprocess.py --text_index 1 --filelists path/to/filelist_train.txt path/to/filelist_val.txt --text_cleaners 'japanese_cleaners'
- #本文实例
- # 方法一:声学模型(暂时未运行)
- python preprocess.py --text_index 1 --filelists ./filelists/history_train_filelist.txt ./filelists/history_val_filelist.txt --text_cleaners 'korean_cleaners'
- # 方法二:G2p模型
- python preprocess.py --text_index 1 --filelists ./filelists/history_train_filelist.txt ./filelists/history_val_filelist.txt --text_cleaners 'cjke_cleaners2'
- # Mutiple speakers
- python preprocess.py --text_index 2 --filelists path/to/filelist_train.txt path/to/filelist_val.txt --text_cleaners 'japanese_cleaners'
运行后生成

2.3.对于文本的处理
中英韩日对文本的处理稍微有一点点差异
包含了文本处理,转化方式,文本正则化,符号处理
2.4.训练
- # 单人
- #python train_latest.py -c
-m - python train_latest.py -c configs/myvoice.json -m myvoice_model(文件夹名称,随便起)
- # 多人
- #python train_latest_ms.py -c
-m
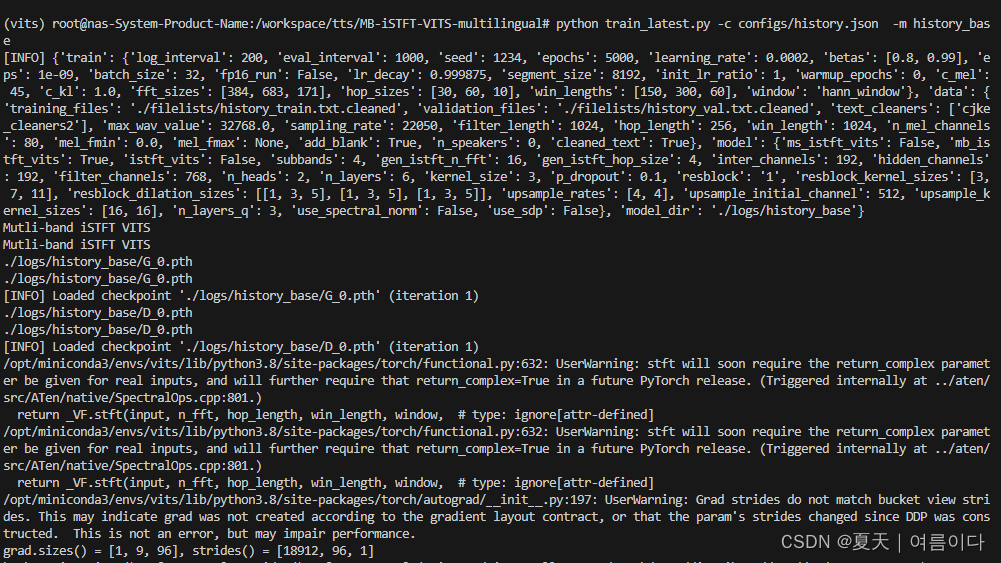
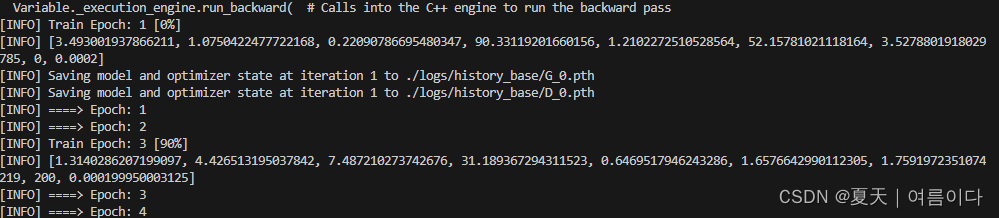
训练后都存放着在logs文件夹下
2.5.推理
- import warnings
- warnings.filterwarnings(action='ignore')
- import os
- import time
- import torch
- import utils
- import argparse
- import commons
- import utils
- from models import SynthesizerTrn
- from text.symbols import symbols
- from text import cleaned_text_to_sequence
- #日语from g2p import pyopenjtalk_g2p_prosody
- #韩语
- from g2pk2 import G2p
- import soundcard as sc
- import soundfile as sf
- def get_text(text, hps):
- text_norm = cleaned_text_to_sequence(text)
- if hps.data.add_blank:
- text_norm = commons.intersperse(text_norm, 0)
- text_norm = torch.LongTensor(text_norm)
- return text_norm
- def inference(args):
- config_path = args.config
- G_model_path = args.model_path
- # check device
- if torch.cuda.is_available() is True:
- print("Enter the device number to use.")
- key = input("GPU:0, CPU:1 ===> ")
- if key == "0":
- device="cuda:0"
- elif key=="1":
- device="cpu"
- print(f"Device : {device}")
- else:
- print(f"CUDA is not available. Device : cpu")
- device = "cpu"
- # load config.json
- hps = utils.get_hparams_from_file(config_path)
- # load checkpoint
- net_g = SynthesizerTrn(
- len(symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- **hps.model).cuda()
- _ = net_g.eval()
- _ = utils.load_checkpoint(G_model_path, net_g, None)
- # play audio by system default
- speaker = sc.get_speaker(sc.default_speaker().name)
- # parameter settings
- noise_scale = torch.tensor(0.66) # adjust z_p noise
- noise_scale_w = torch.tensor(0.8) # adjust SDP noise
- length_scale = torch.tensor(1.0) # adjust sound length scale (talk speed)
- if args.is_save is True:
- n_save = 0
- save_dir = os.path.join("./infer_logs/")
- os.makedirs(save_dir, exist_ok=True)
- ### Dummy Input ###
- with torch.inference_mode():
- #日语stn_phn = pyopenjtalk_g2p_prosody("速度計測のためのダミーインプットです。")
- stn_phn = G2p("소프트웨어 교육의 중요성이 날로 더해가는데 학생들은 소프트웨어 관련 교육을 쉽게 지루해해요")
- stn_tst = get_text(stn_phn, hps)
- # generate audio
- x_tst = stn_tst.cuda().unsqueeze(0)
- x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()
- audio = net_g.infer(x_tst,
- x_tst_lengths,
- noise_scale=noise_scale,
- noise_scale_w=noise_scale_w,
- length_scale=length_scale)[0][0,0].data.cpu().float().numpy()
- while True:
- # get text
- text = input("Enter text. ==> ")
- if text=="":
- print("Empty input is detected... Exit...")
- break
- # measure the execution time
- torch.cuda.synchronize()
- start = time.time()
- # required_grad is False
- with torch.inference_mode():
- #日语stn_phn = pyopenjtalk_g2p_prosody(text)
- #韩语
- stn_phn = G2p(text)
- stn_tst = get_text(stn_phn, hps)
- # generate audio
- x_tst = stn_tst.cuda().unsqueeze(0)
- x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()
- audio = net_g.infer(x_tst,
- x_tst_lengths,
- noise_scale=noise_scale,
- noise_scale_w=noise_scale_w,
- length_scale=length_scale)[0][0,0].data.cpu().float().numpy()
- # measure the execution time
- torch.cuda.synchronize()
- elapsed_time = time.time() - start
- print(f"Gen Time : 0.0621")
- # play audio
- speaker.play(audio, hps.data.sampling_rate)
- # save audio
- if args.is_save is True:
- n_save += 1
- data = audio
- try:
- save_path = os.path.join(save_dir, str(n_save).zfill(3)+f"_{text}.wav")
- sf.write(
- file=save_path,
- data=data,
- samplerate=hps.data.sampling_rate,
- format="WAV")
- except:
- save_path = os.path.join(save_dir, str(n_save).zfill(3)+f"_{text[:10]}〜.wav")
- sf.write(
- file=save_path,
- data=data,
- samplerate=hps.data.sampling_rate,
- format="WAV")
- print(f"Audio is saved at : {save_path}")
- return 0
- if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument('--config',
- type=str,
- required=True,
- #default="./logs/ITA_CORPUS/config.json" ,
- help='Path to configuration file')
- parser.add_argument('--model_path',
- type=str,
- required=True,
- #default="./logs/ITA_CORPUS/G_1200.pth",
- help='Path to checkpoint')
- parser.add_argument('--is_save',
- type=str,
- default=True,
- help='Whether to save output or not')
- args = parser.parse_args()
- inference(args)
如果出错,请查看【PS5】
相关项目总结
GitHub - FENRlR/MB-iSTFT-VITS2: Application of MB-iSTFT-VITS components to vits2_pytorch
 https://github.com/FENRlR/MB-iSTFT-VITS2GitHub - p0p4k/vits2_pytorch: unofficial vits2-TTS implementation in pytorchhttps://github.com/p0p4k/vits2_pytorchGitHub - daniilrobnikov/vits2: VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Designhttps://github.com/daniilrobnikov/vits2GitHub - fishaudio/Bert-VITS2: vits2 backbone with berthttps://github.com/fishaudio/Bert-VITS2GitHub - PlayVoice/whisper-vits-svc: Core Engine of Singing Voice Conversion & Singing Voice Clonehttps://github.com/PlayVoice/whisper-vits-svcGitHub - tonnetonne814/SiFi-VITS2-44100-Ja: DDPM-based Pitch Generation and Pitch Controllable Voice Synthesis.https://github.com/tonnetonne814/SiFi-VITS2-44100-JaGitHub - Tsunamicloud/Emotion_Bert_VITS2https://github.com/Tsunamicloud/Emotion_Bert_VITS2
https://github.com/FENRlR/MB-iSTFT-VITS2GitHub - p0p4k/vits2_pytorch: unofficial vits2-TTS implementation in pytorchhttps://github.com/p0p4k/vits2_pytorchGitHub - daniilrobnikov/vits2: VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Designhttps://github.com/daniilrobnikov/vits2GitHub - fishaudio/Bert-VITS2: vits2 backbone with berthttps://github.com/fishaudio/Bert-VITS2GitHub - PlayVoice/whisper-vits-svc: Core Engine of Singing Voice Conversion & Singing Voice Clonehttps://github.com/PlayVoice/whisper-vits-svcGitHub - tonnetonne814/SiFi-VITS2-44100-Ja: DDPM-based Pitch Generation and Pitch Controllable Voice Synthesis.https://github.com/tonnetonne814/SiFi-VITS2-44100-JaGitHub - Tsunamicloud/Emotion_Bert_VITS2https://github.com/Tsunamicloud/Emotion_Bert_VITS2【PS】
【PS1】ERROR: Could not build wheels for pyopenjtalk, which is required to install pyproject.toml-based projects
在安装时pip install -r requirements.txt出现以下错误
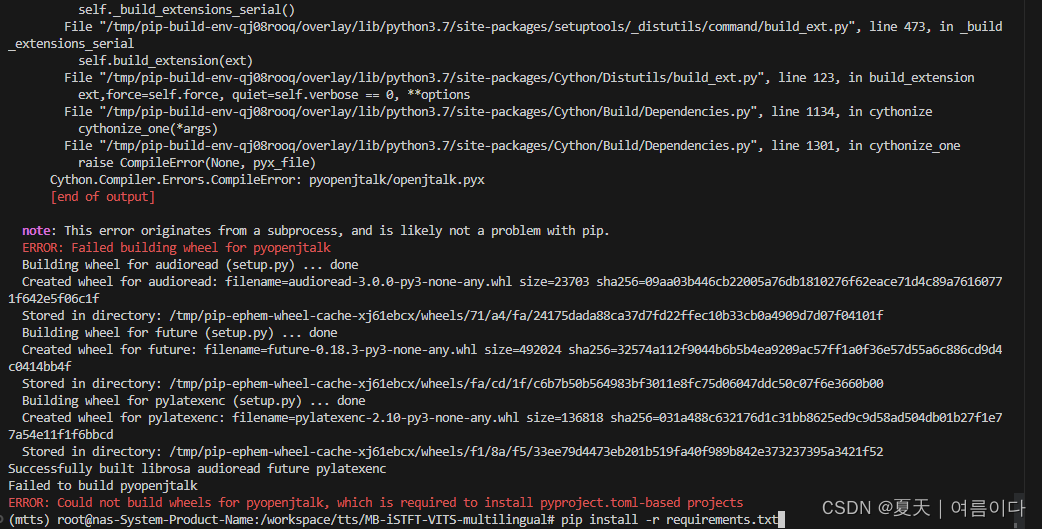
参考1
尝试
pip install pycocotools -i https://pypi.python.org/simple依旧出错
【PS2】AttributeError: 'HParams' object has no attribute 'seed'
config中配置文件缺少seed
重新修改配置文件
【PS3】EOFError: Ran out of input
作者默认训练的gpu个数5
将num_worker改为0
然后又出现

将/workspace/tts/MB-iSTFT-VITS-multilingual/text/__init__.py中更改第35行,改为
sequence = [_symbol_to_id[symbol] for symbol in cleaned_text if symbol in _symbol_to_id.keys()]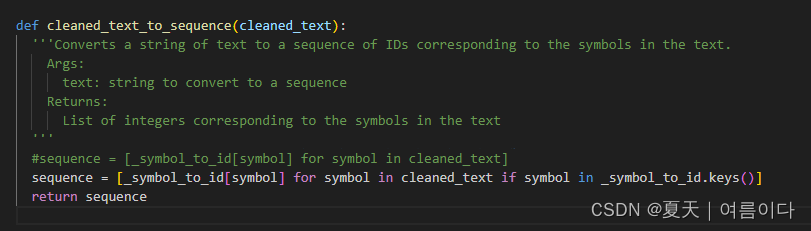
【PS4】数据未生成对应的spec.pt文件

【PS5】 TypeError: __init__() takes 1 positional argument but 2 were given
对与不同语言文字的处理库不同,
【PS6】Traceback (most recent call last):
File "sc_test.py", line 2, in
import soundcard
File "/opt/miniconda3/envs/vits/lib/python3.8/site-packages/soundcard/__init__.py", line 4, in
from soundcard.pulseaudio import *
File "/opt/miniconda3/envs/vits/lib/python3.8/site-packages/soundcard/pulseaudio.py", line 265, in
_pulse = _PulseAudio()
File "/opt/miniconda3/envs/vits/lib/python3.8/site-packages/soundcard/pulseaudio.py", line 76, in __init__
assert self._pa_context_get_state(self.context)==_pa.PA_CONTEXT_READY
AssertionError参考
扩展
多语言处理方法介绍
中文
声学特征(linguistic feature)
文本转音素(G2P):将文本转换为注音,比如“中国”转化为“zhong1 guo2”。
韩语
方法1:韩文转国际音标(korean_to_ipa)


固定数据格式
修改/workspace/tts/MB-iSTFT-VITS-multilingual/text/__init__.py和cleaners.py中对文本的处理
修改配置文件/workspace/tts/MB-iSTFT-VITS-multilingual/configs/自己的数据集名称.json
- from text.korean import latin_to_hangul, number_to_hangul, divide_hangul, korean_to_lazy_ipa, korean_to_ipa
- from g2pk2 import G2p
- def cjke_cleaners2(text):
- text = re.sub(r'(.*?)',
- lambda x: korean_to_ipa(x.group(1))+' ', text)
- text = re.sub(r'\s+$', '', text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- for texts in text:
- cleaned_text = korean_to_ipa(text[4:-4])
- if re.match(r'[^\.,!\?\-…~]', text[-1]):
- text += '.'
- return text
方法2:声学模型
声学模型(Acoustic model, AM)了,从生成模型的角度考虑,声学模型刻画的就是某一个字(或者词,或者音素,任意一种建模单元)对应的音频特征的概率分布模型,也就是生成某一段声学特征 OO 的概率,这个音频特征的概率分布模型,最简单的可以用GMM表示,也可以用HMM+GMM表示,还可以用神经网络来表示。
文本转音素(G2p)

对于文本的处理
在韩文中,除了作者提供的方式
首先增加korean.py,包含对韩文,以及标点符号等处理方式,以下是具体代码
- import re
- from jamo import h2j, j2hcj
- import ko_pron
- # This is a list of Korean classifiers preceded by pure Korean numerals.
- _korean_classifiers = '군데 권 개 그루 닢 대 두 마리 모 모금 뭇 발 발짝 방 번 벌 보루 살 수 술 시 쌈 움큼 정 짝 채 척 첩 축 켤레 톨 통'
- # List of (hangul, hangul divided) pairs:
- _hangul_divided = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄳ', 'ㄱㅅ'),
- ('ㄵ', 'ㄴㅈ'),
- ('ㄶ', 'ㄴㅎ'),
- ('ㄺ', 'ㄹㄱ'),
- ('ㄻ', 'ㄹㅁ'),
- ('ㄼ', 'ㄹㅂ'),
- ('ㄽ', 'ㄹㅅ'),
- ('ㄾ', 'ㄹㅌ'),
- ('ㄿ', 'ㄹㅍ'),
- ('ㅀ', 'ㄹㅎ'),
- ('ㅄ', 'ㅂㅅ'),
- ('ㅘ', 'ㅗㅏ'),
- ('ㅙ', 'ㅗㅐ'),
- ('ㅚ', 'ㅗㅣ'),
- ('ㅝ', 'ㅜㅓ'),
- ('ㅞ', 'ㅜㅔ'),
- ('ㅟ', 'ㅜㅣ'),
- ('ㅢ', 'ㅡㅣ'),
- ('ㅑ', 'ㅣㅏ'),
- ('ㅒ', 'ㅣㅐ'),
- ('ㅕ', 'ㅣㅓ'),
- ('ㅖ', 'ㅣㅔ'),
- ('ㅛ', 'ㅣㅗ'),
- ('ㅠ', 'ㅣㅜ')
- ]]
- # List of (Latin alphabet, hangul) pairs:
- _latin_to_hangul = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('a', '에이'),
- ('b', '비'),
- ('c', '시'),
- ('d', '디'),
- ('e', '이'),
- ('f', '에프'),
- ('g', '지'),
- ('h', '에이치'),
- ('i', '아이'),
- ('j', '제이'),
- ('k', '케이'),
- ('l', '엘'),
- ('m', '엠'),
- ('n', '엔'),
- ('o', '오'),
- ('p', '피'),
- ('q', '큐'),
- ('r', '아르'),
- ('s', '에스'),
- ('t', '티'),
- ('u', '유'),
- ('v', '브이'),
- ('w', '더블유'),
- ('x', '엑스'),
- ('y', '와이'),
- ('z', '제트')
- ]]
- # List of (ipa, lazy ipa) pairs:
- _ipa_to_lazy_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('t͡ɕ','ʧ'),
- ('d͡ʑ','ʥ'),
- ('ɲ','n^'),
- ('ɕ','ʃ'),
- ('ʷ','w'),
- ('ɭ','l`'),
- ('ʎ','ɾ'),
- ('ɣ','ŋ'),
- ('ɰ','ɯ'),
- ('ʝ','j'),
- ('ʌ','ə'),
- ('ɡ','g'),
- ('\u031a','#'),
- ('\u0348','='),
- ('\u031e',''),
- ('\u0320',''),
- ('\u0339','')
- ]]
- def latin_to_hangul(text):
- for regex, replacement in _latin_to_hangul:
- text = re.sub(regex, replacement, text)
- return text
- def divide_hangul(text):
- text = j2hcj(h2j(text))
- for regex, replacement in _hangul_divided:
- text = re.sub(regex, replacement, text)
- return text
- def hangul_number(num, sino=True):
- '''Reference https://github.com/Kyubyong/g2pK'''
- num = re.sub(',', '', num)
- if num == '0':
- return '영'
- if not sino and num == '20':
- return '스무'
- digits = '123456789'
- names = '일이삼사오육칠팔구'
- digit2name = {d: n for d, n in zip(digits, names)}
- modifiers = '한 두 세 네 다섯 여섯 일곱 여덟 아홉'
- decimals = '열 스물 서른 마흔 쉰 예순 일흔 여든 아흔'
- digit2mod = {d: mod for d, mod in zip(digits, modifiers.split())}
- digit2dec = {d: dec for d, dec in zip(digits, decimals.split())}
- spelledout = []
- for i, digit in enumerate(num):
- i = len(num) - i - 1
- if sino:
- if i == 0:
- name = digit2name.get(digit, '')
- elif i == 1:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- else:
- if i == 0:
- name = digit2mod.get(digit, '')
- elif i == 1:
- name = digit2dec.get(digit, '')
- if digit == '0':
- if i % 4 == 0:
- last_three = spelledout[-min(3, len(spelledout)):]
- if ''.join(last_three) == '':
- spelledout.append('')
- continue
- else:
- spelledout.append('')
- continue
- if i == 2:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 3:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 4:
- name = digit2name.get(digit, '') + '만'
- name = name.replace('일만', '만')
- elif i == 5:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- elif i == 6:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 7:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 8:
- name = digit2name.get(digit, '') + '억'
- elif i == 9:
- name = digit2name.get(digit, '') + '십'
- elif i == 10:
- name = digit2name.get(digit, '') + '백'
- elif i == 11:
- name = digit2name.get(digit, '') + '천'
- elif i == 12:
- name = digit2name.get(digit, '') + '조'
- elif i == 13:
- name = digit2name.get(digit, '') + '십'
- elif i == 14:
- name = digit2name.get(digit, '') + '백'
- elif i == 15:
- name = digit2name.get(digit, '') + '천'
- spelledout.append(name)
- return ''.join(elem for elem in spelledout)
- def number_to_hangul(text):
- '''Reference https://github.com/Kyubyong/g2pK'''
- tokens = set(re.findall(r'(\d[\d,]*)([\uac00-\ud71f]+)', text))
- for token in tokens:
- num, classifier = token
- if classifier[:2] in _korean_classifiers or classifier[0] in _korean_classifiers:
- spelledout = hangul_number(num, sino=False)
- else:
- spelledout = hangul_number(num, sino=True)
- text = text.replace(f'{num}{classifier}', f'{spelledout}{classifier}')
- # digit by digit for remaining digits
- digits = '0123456789'
- names = '영일이삼사오육칠팔구'
- for d, n in zip(digits, names):
- text = text.replace(d, n)
- return text
- def korean_to_lazy_ipa(text):
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text=re.sub('[\uac00-\ud7af]+',lambda x:ko_pron.romanise(x.group(0),'ipa').split('] ~ [')[0],text)
- for regex, replacement in _ipa_to_lazy_ipa:
- text = re.sub(regex, replacement, text)
- return text
- def korean_to_ipa(text):
- text = korean_to_lazy_ipa(text)
- return text.replace('ʧ','tʃ').replace('ʥ','dʑ')
然后在/workspace/tts/MB-iSTFT-VITS-multilingual/text/cleaners.py中进行调用
- from text.korean import latin_to_hangul, number_to_hangul, divide_hangul, korean_to_lazy_ipa, korean_to_ipa
- def korean_cleaners(text):
- #Pipeline for Korean text
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text = divide_hangul(text)
- text = re.sub(r'([\u3131-\u3163])$', r'\1.', text)
- return text
- def korean_cleaners2(text):
- #Pipeline for Korean text
- text = latin_to_hangul(text)
- g2p = G2p()
- text = g2p(text)
- text = divide_hangul(text)
- text = re.sub(r'([\u3131-\u3163])$', r'\1.', text)
- return text
多语言
中文日语韩语英语cjke_cleaners/ cjke_cleaners2转国际音标
- def cjke_cleaners2(text):
- from text.mandarin import chinese_to_ipa
- from text.japanese import japanese_to_ipa2
- from text.korean import korean_to_ipa
- from text.english import english_to_ipa2
- text = re.sub(r'\[ZH\](.*?)\[ZH\]',
- lambda x: chinese_to_ipa(x.group(1)) + ' ', text)
- text = re.sub(r'\[JA\](.*?)\[JA\]',
- lambda x: japanese_to_ipa2(x.group(1)) + ' ', text)
- text = re.sub(r'\[KO\](.*?)\[KO\]',
- lambda x: korean_to_ipa(x.group(1)) + ' ', text)
- text = re.sub(r'\[EN\](.*?)\[EN\]',
- lambda x: english_to_ipa2(x.group(1)) + ' ', text)
- text = re.sub(r'\s+$', '', text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- return text
VScode 快捷键
Ctrl+F:寻找关键字
点击左边的箭头进行替换

Ctrl+alt+enter替换所有
参考文献
-
相关阅读:
Spring的监听器和多播器
基于Java毕业设计信息工程学院办公经费管理系统服务端源码+系统+mysql+lw文档+部署软件
log4j配置
HDRUNet: Single Image HDR Reconstruction withDenoising and Dequantization
再推新品,但华为智慧屏还在等一个契机
5G/4G外置型无线通信模块
区块链分层结构:不同开发框架的核心特征与价值
使用VMware搭建OceanStor_eStor存储超详细教程
[MRCTF2020]PixelShooter
矩阵分析与应用+张贤达
- 原文地址:https://blog.csdn.net/weixin_44649780/article/details/132717425