-
经典网络解析(二)Vgg | 块的设计思想,代码,小卷积核
之前我们讲到AlexNet,以及改进ZFnet但是这些网络结构都没有提供一个通用的模版来指导后续的设计,都是在一层一层设计
今天的VGG则开创性的利用“块”的设计方式,便于加深网络
可以发现神经网络的研究
从一开始的单个神经元 到 神经网络层 再到 神经网络块
逐渐变得更加抽象
-
单个神经元(Neuron): 单个神经元是神经网络的基本组成单位。
这个阶段类似于一个单一的“工人”,它可以执行基本的信息处理任务,但受限于其简单性和有限的表达能力。
-
神经网络层(Layer): 将多个神经元组织成层次结构。每一层包含多个神经元,这些神经元共同协作来处理输入数据并生成输出。不同层之间的连接权重可以调整,从而使网络能够学习更复杂的特征和关系。
这个阶段类似于将多个工人组织成一个团队,每个成员具有特定的任务,团队协同工作以解决更复杂的问题。
-
神经网络块(Block): 进一步的发展将多个层组合成神经网络块或模块。每个块可以包含多个层,这些层在功能上有一定的相关性,通常用于处理特定类型的任务或数据。块之间的信息流动通常是顺序的,这有助于网络更好地理解复杂的数据结构。
这个阶段类似于将多个团队组织成一个更大的组织,每个团队专注于不同的方面,组织内部的信息流动更加复杂和高效。
1.回顾
VGG(Visual Geometry Group)网络是深度学习领域的一个重要里程碑,具有重要的意义,主要体现在以下几个方面:
- 深度网络的重要性和可训练性验证: VGG网络通过多个卷积层和池化层的堆叠展示了深度神经网络的重要性。它证明了更深层次的网络结构可以更好地学习到图像的抽象特征。此前,一些人认为增加网络深度会导致梯度消失或梯度爆炸问题,因此深度网络很难训练。VGG的成功表明,在适当的设置下,深度神经网络是可训练的,而且能够提取丰富的特征。
- 卷积神经网络架构的标准化: VGG网络引入了一种简单而统一的卷积神经网络架构,采用了相同大小的卷积核和池化窗口,以及相同数量的卷积层。这种标准化使得构建和训练卷积神经网络变得更加简单和可控。
- 在图像分类竞赛中的优异表现: VGG网络在2014年的ImageNet图像分类挑战赛中取得了卓越的成绩。它的表现证明了深度卷积神经网络在计算机视觉任务中的巨大潜力。这个突破激发了更多研究人员对深度学习的兴趣,促进了深度学习技术的广泛应用。
2.VGG解析
2.1 结构
VGG-16 13个卷积层与3个全连接层
VGG-19 16个卷积层与3个全连接层
一般用Vgg-16
Vgg比起AlexNet做出的重要的改变是
使用尺寸更小的3×3卷积核串联来替代大卷积核11×11,7×7这样的大尺寸卷积核,引入块设计思想,在相同的感受野的情况下,多个串联非线性能力更强,描述能力更强
2.1.1 输入处理
做平均去均值
AlexNet,ZFnet 统计所有的图像的像素均值,得到一个均值向量,每一个图像输入之前先减去这个均值向量,比如之前输入是227×227×3那么他的均值向量就是227×227×3
而Vgg不以图像为均值,而是统计某一个像素点的所有的R,G,B的均值。均值向量就是3×1 每一个图像输入之前先减去这个均值向量
2.1.2 块的设计
如图左边是AlexNet,右边是Vgg16的结构
橘黄色的部分是Vgg块,可以看到他们大体结构相同,唯一的差别是卷积层数,和通道数,所以可以抽象一个函数实现
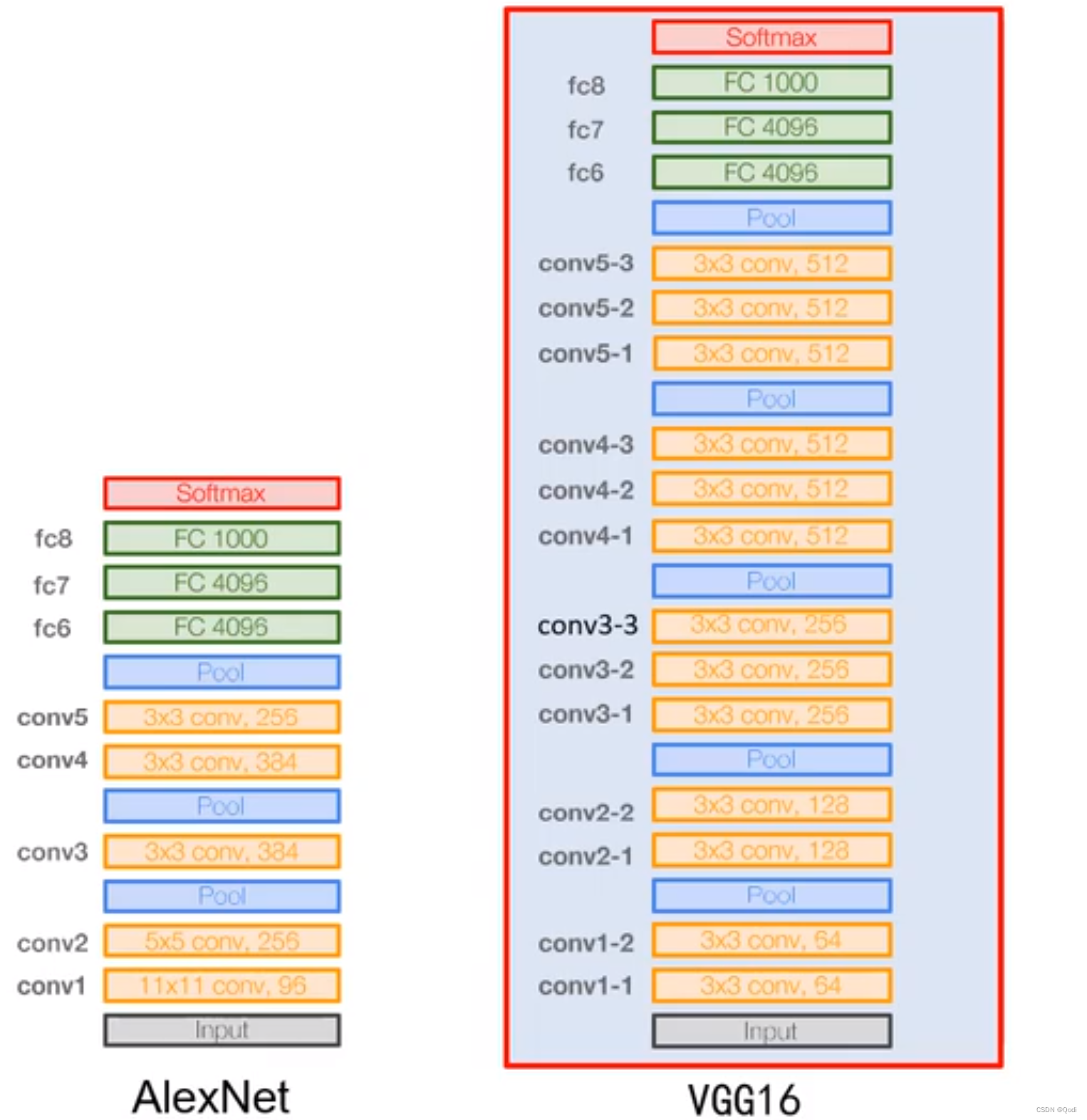
问题 1:为什么前面通道数较少,后面通道数较多?
我们所有的物体都可以看做是由一些基础的纹理基元表示的
他们是有限的,而组成的可能性很多
前层安排较少的通道数,因为前层是学习一些纹理表示基元,所以不需要那么多通道(Vgg是64),而后参是更具体的高层语义,有着更多的可能,所以安排更多的通道(Vgg是512)
问题2:Vgg前四段里,为什么每经过一次池化操作,卷积核个数就增加一倍
1 池化操作减少特征图尺寸,降低显存占用
2 增加卷积核个数有助于学习更多的结构特征,但会增加显存占用
3 先减少特征图尺寸,再增加特征图个数,一减一增,维持开销,提升网络性能
问题3 为什么卷积核增加到512个不再增加了
因为会让网络参数急剧增大
2.2 代码实现
import torch from torch import nn def vgg_block(num_convs,in_channels,out_channels): layers=[] for _ in range(num_convs): layers.append(nn.Conv2d(kernel_size=3,in_channels=in_channels,out_channels=out_channels,padding=1)) layers.append(nn.ReLU()) in_channels=out_channels layers.append(nn.MaxPool2d(kernel_size=2,stride=2)) return nn.Sequential(*layers) #这里*是解包,可以理解为把列表拆成一个一个的 conv_arch=((2,64),(2,128),(3,256),(3,512),(3,512)) #第一个是vgg块内有几个卷积层,第二个代表vgg块输出卷积层通道数 def vgg(conv_arch): cnn_blocks=[] in_channels=3 for num_convs,out_channels in conv_arch: cnn_blocks.append(vgg_block(num_convs,in_channels,out_channels)) in_channels=out_channels return nn.Sequential( *cnn_blocks, nn.Flatten(), nn.Linear(out_channels*7*7,4096),nn.ReLU(),nn.Dropout(0.5), nn.Linear(4096,4096),nn.ReLU(),nn.Dropout(0.5), nn.Linear(4096,1000),nn.ReLU(),nn.Dropout(0.5), ) x=torch.randn(1,3,227,227) net=vgg(conv_arch) for block in net: x=block(x) print(block.__class__.__name__,"输出形状:",x.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
输出
Sequential 输出形状: torch.Size([1, 64, 113, 113]) Sequential 输出形状: torch.Size([1, 128, 56, 56]) Sequential 输出形状: torch.Size([1, 256, 28, 28]) Sequential 输出形状: torch.Size([1, 512, 14, 14]) Sequential 输出形状: torch.Size([1, 512, 7, 7]) Flatten 输出形状: torch.Size([1, 25088]) Linear 输出形状: torch.Size([1, 4096]) ReLU 输出形状: torch.Size([1, 4096]) Dropout 输出形状: torch.Size([1, 4096]) Linear 输出形状: torch.Size([1, 4096]) ReLU 输出形状: torch.Size([1, 4096]) Dropout 输出形状: torch.Size([1, 4096]) Linear 输出形状: torch.Size([1, 1000]) ReLU 输出形状: torch.Size([1, 1000]) Dropout 输出形状: torch.Size([1, 1000])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.贡献总结
1 使用尺寸更小的3×3卷积核串联来替代大卷积核11×11,7×7这样的大尺寸卷积核,引入块设计思想,在相同的感受野的情况下,多个串联非线性能力更强,描述能力更强
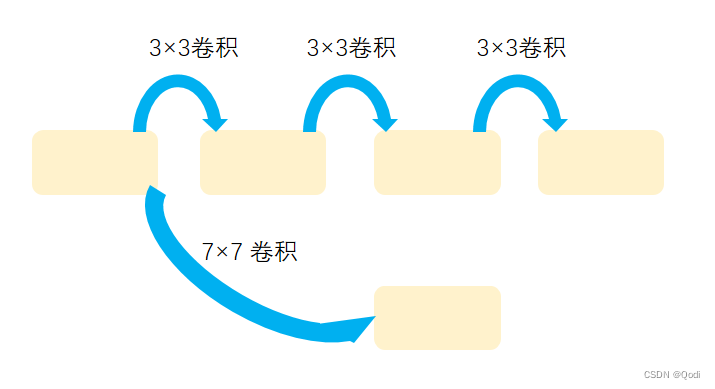
2 深度更深,非线性更强,网络的参数也更少(小尺寸的卷积核参数量要比大尺寸的参数量小)
3 去掉了AlexNet里的局部响应归一化层
-
-
相关阅读:
加密市场波动:地缘政治与美股走弱引发不确定性!
【周末读书】认知驱动:做成一件对他人很有用的事
10个技巧,3分钟教会你高效寻找开源项目
k8s-helm-简介及基础配置
前端开发面试题—CSS清除浮动的方法
一行Python代码即可实现数据可视化大屏
基础语法——组合与继承
UNet网络
C++ auto
硬链接和软链接的区别
- 原文地址:https://blog.csdn.net/Q52099999/article/details/133209514
